 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving the Accuracy and Efficiency of MAP Inference for Markov Logic
Jun 13, 2012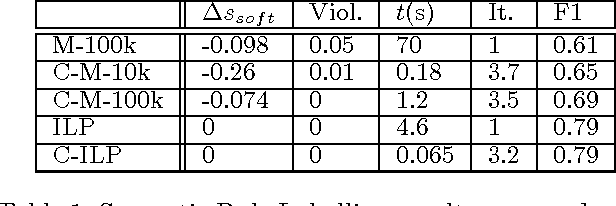
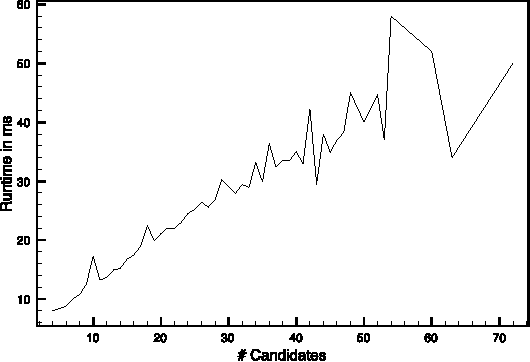
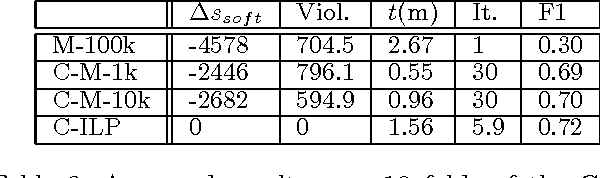
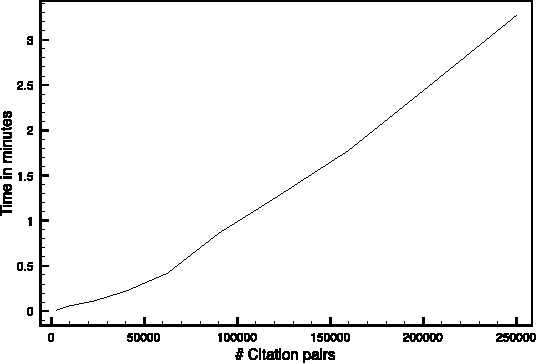
In this work we present Cutting Plane Inference (CPI), a Maximum A Posteriori (MAP) inference method for Statistical Relational Learning. Framed in terms of Markov Logic and inspired by the Cutting Plane Method, it can be seen as a meta algorithm that instantiates small parts of a large and complex Markov Network and then solves these using a conventional MAP method. We evaluate CPI on two tasks, Semantic Role Labelling and Joint Entity Resolution, while plugging in two different MAP inference methods: the current method of choice for MAP inference in Markov Logic, MaxWalkSAT, and Integer Linear Programming. We observe that when used with CPI both methods are significantly faster than when used alone. In addition, CPI improves the accuracy of MaxWalkSAT and maintains the exactness of Integer Linear Programming.
Inference by Minimizing Size, Divergence, or their Sum
Mar 15, 2012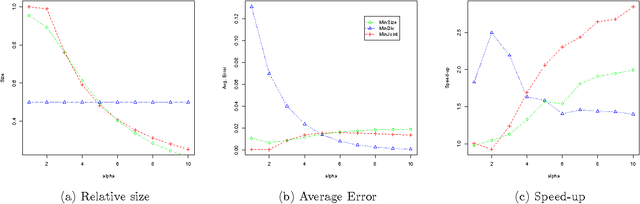

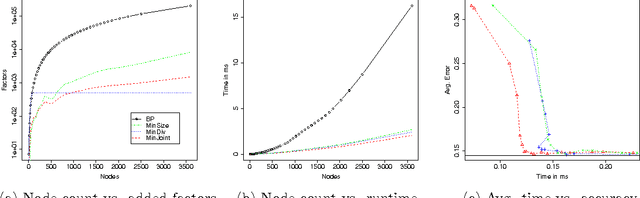
We speed up marginal inference by ignoring factors that do not significantly contribute to overall accuracy. In order to pick a suitable subset of factors to ignore, we propose three schemes: minimizing the number of model factors under a bound on the KL divergence between pruned and full models; minimizing the KL divergence under a bound on factor count; and minimizing the weighted sum of KL divergence and factor count. All three problems are solved using an approximation of the KL divergence than can be calculated in terms of marginals computed on a simple seed graph. Applied to synthetic image denoising and to three different types of NLP parsing models, this technique performs marginal inference up to 11 times faster than loopy BP, with graph sizes reduced up to 98%-at comparable error in marginals and parsing accuracy. We also show that minimizing the weighted sum of divergence and size is substantially faster than minimizing either of the other objectives based on the approximation to divergence presented here.