 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLifted Rule Injection for Relation Embeddings
Sep 23, 2016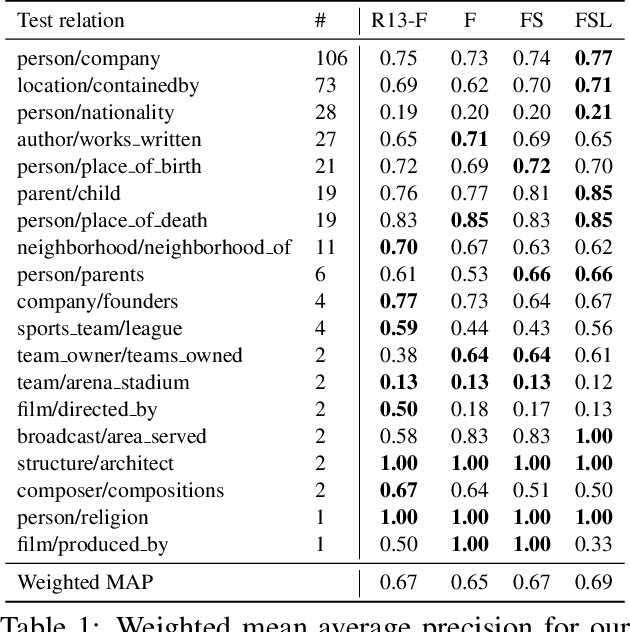
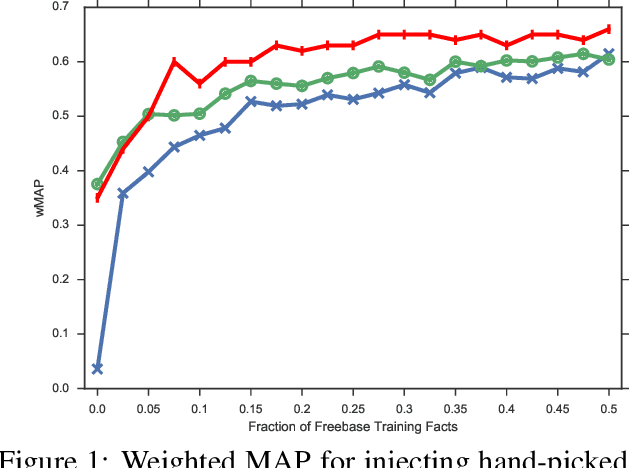

Methods based on representation learning currently hold the state-of-the-art in many natural language processing and knowledge base inference tasks. Yet, a major challenge is how to efficiently incorporate commonsense knowledge into such models. A recent approach regularizes relation and entity representations by propositionalization of first-order logic rules. However, propositionalization does not scale beyond domains with only few entities and rules. In this paper we present a highly efficient method for incorporating implication rules into distributed representations for automated knowledge base construction. We map entity-tuple embeddings into an approximately Boolean space and encourage a partial ordering over relation embeddings based on implication rules mined from WordNet. Surprisingly, we find that the strong restriction of the entity-tuple embedding space does not hurt the expressiveness of the model and even acts as a regularizer that improves generalization. By incorporating few commonsense rules, we achieve an increase of 2 percentage points mean average precision over a matrix factorization baseline, while observing a negligible increase in runtime.
Numerically Grounded Language Models for Semantic Error Correction
Aug 14, 2016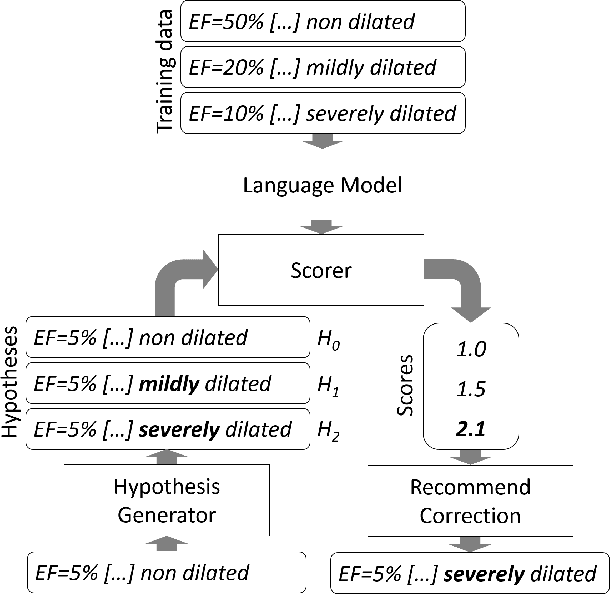
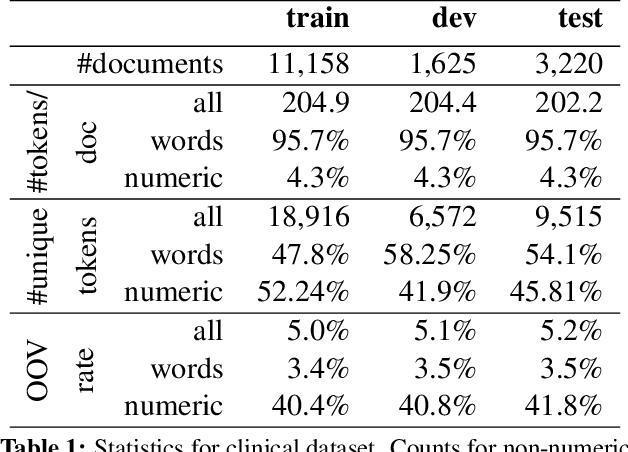
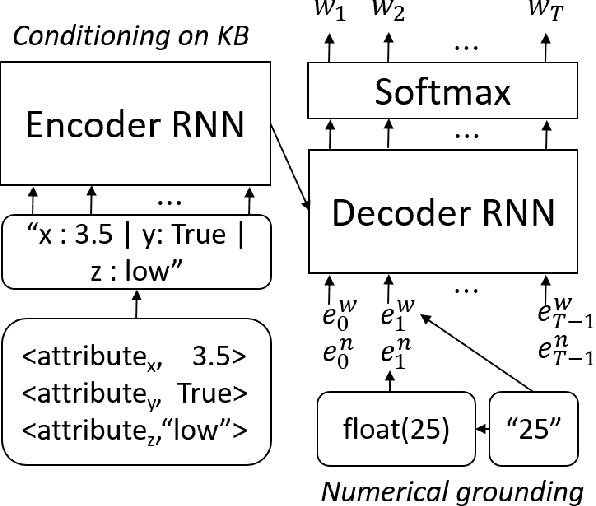
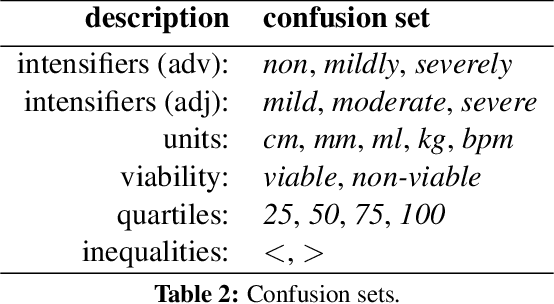
Semantic error detection and correction is an important task for applications such as fact checking, speech-to-text or grammatical error correction. Current approaches generally focus on relatively shallow semantics and do not account for numeric quantities. Our approach uses language models grounded in numbers within the text. Such groundings are easily achieved for recurrent neural language model architectures, which can be further conditioned on incomplete background knowledge bases. Our evaluation on clinical reports shows that numerical grounding improves perplexity by 33% and F1 for semantic error correction by 5 points when compared to ungrounded approaches. Conditioning on a knowledge base yields further improvements.
Complex Embeddings for Simple Link Prediction
Jun 20, 2016
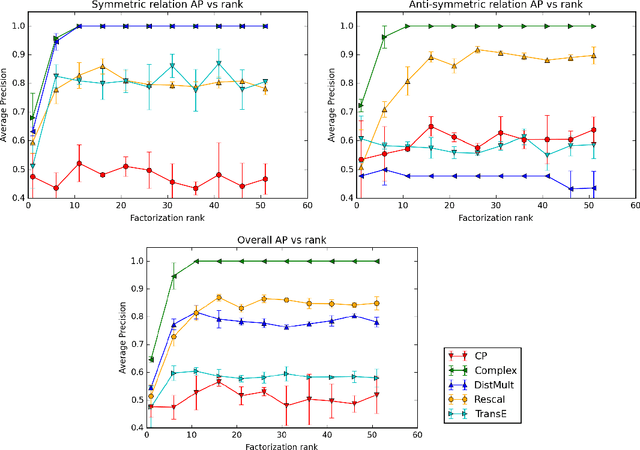
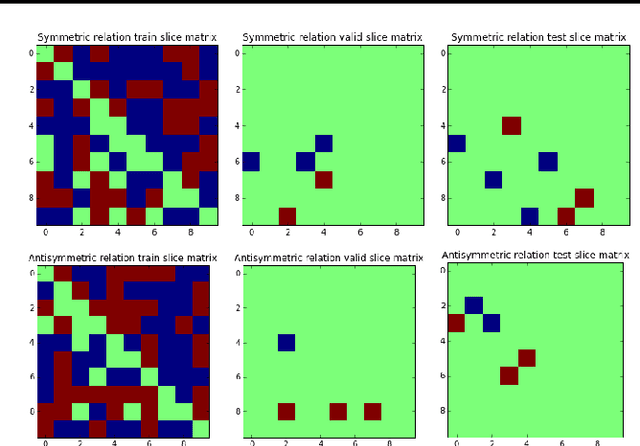
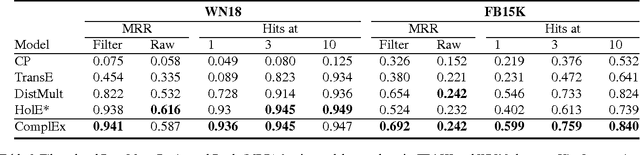
In statistical relational learning, the link prediction problem is key to automatically understand the structure of large knowledge bases. As in previous studies, we propose to solve this problem through latent factorization. However, here we make use of complex valued embeddings. The composition of complex embeddings can handle a large variety of binary relations, among them symmetric and antisymmetric relations. Compared to state-of-the-art models such as Neural Tensor Network and Holographic Embeddings, our approach based on complex embeddings is arguably simpler, as it only uses the Hermitian dot product, the complex counterpart of the standard dot product between real vectors. Our approach is scalable to large datasets as it remains linear in both space and time, while consistently outperforming alternative approaches on standard link prediction benchmarks.
Generating Natural Language Inference Chains
Jun 04, 2016


The ability to reason with natural language is a fundamental prerequisite for many NLP tasks such as information extraction, machine translation and question answering. To quantify this ability, systems are commonly tested whether they can recognize textual entailment, i.e., whether one sentence can be inferred from another one. However, in most NLP applications only single source sentences instead of sentence pairs are available. Hence, we propose a new task that measures how well a model can generate an entailed sentence from a source sentence. We take entailment-pairs of the Stanford Natural Language Inference corpus and train an LSTM with attention. On a manually annotated test set we found that 82% of generated sentences are correct, an improvement of 10.3% over an LSTM baseline. A qualitative analysis shows that this model is not only capable of shortening input sentences, but also inferring new statements via paraphrasing and phrase entailment. We then apply this model recursively to input-output pairs, thereby generating natural language inference chains that can be used to automatically construct an entailment graph from source sentences. Finally, by swapping source and target sentences we can also train a model that given an input sentence invents additional information to generate a new sentence.
A Factorization Machine Framework for Testing Bigram Embeddings in Knowledgebase Completion
Apr 20, 2016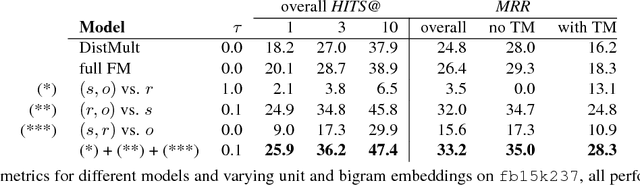
Embedding-based Knowledge Base Completion models have so far mostly combined distributed representations of individual entities or relations to compute truth scores of missing links. Facts can however also be represented using pairwise embeddings, i.e. embeddings for pairs of entities and relations. In this paper we explore such bigram embeddings with a flexible Factorization Machine model and several ablations from it. We investigate the relevance of various bigram types on the fb15k237 dataset and find relative improvements compared to a compositional model.
An Attentive Neural Architecture for Fine-grained Entity Type Classification
Apr 19, 2016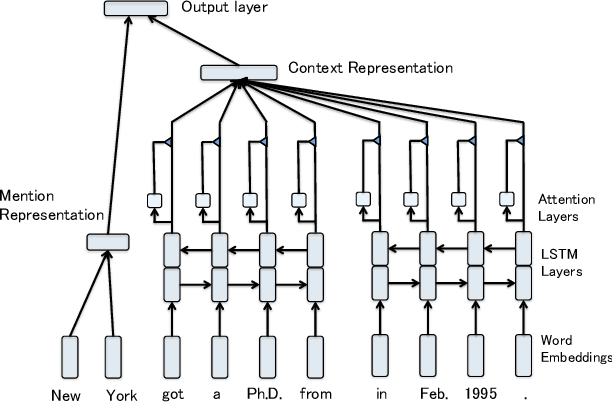
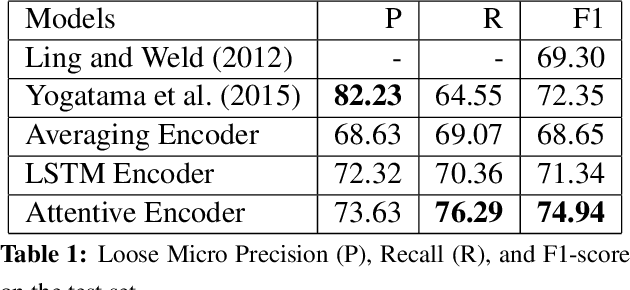
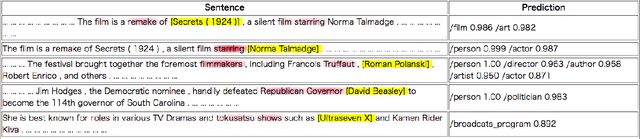
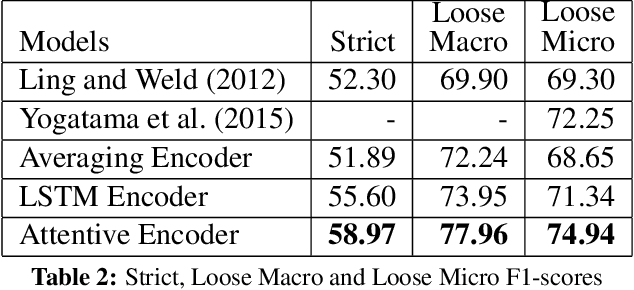
In this work we propose a novel attention-based neural network model for the task of fine-grained entity type classification that unlike previously proposed models recursively composes representations of entity mention contexts. Our model achieves state-of-the-art performance with 74.94% loose micro F1-score on the well-established FIGER dataset, a relative improvement of 2.59%. We also investigate the behavior of the attention mechanism of our model and observe that it can learn contextual linguistic expressions that indicate the fine-grained category memberships of an entity.
Extraction of evidence tables from abstracts of randomized clinical trials using a maximum entropy classifier and global constraints
Sep 17, 2015


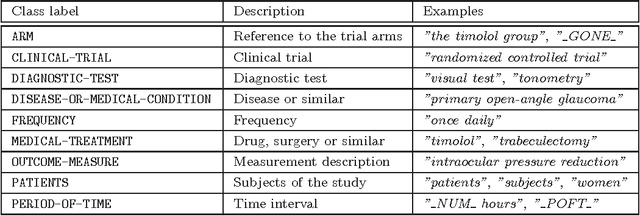
Systematic use of the published results of randomized clinical trials is increasingly important in evidence-based medicine. In order to collate and analyze the results from potentially numerous trials, evidence tables are used to represent trials concerning a set of interventions of interest. An evidence table has columns for the patient group, for each of the interventions being compared, for the criterion for the comparison (e.g. proportion who survived after 5 years from treatment), and for each of the results. Currently, it is a labour-intensive activity to read each published paper and extract the information for each field in an evidence table. There have been some NLP studies investigating how some of the features from papers can be extracted, or at least the relevant sentences identified. However, there is a lack of an NLP system for the systematic extraction of each item of information required for an evidence table. We address this need by a combination of a maximum entropy classifier, and integer linear programming. We use the later to handle constraints on what is an acceptable classification of the features to be extracted. With experimental results, we demonstrate substantial advantages in using global constraints (such as the features describing the patient group, and the interventions, must occur before the features describing the results of the comparison).
Anytime Belief Propagation Using Sparse Domains
Nov 14, 2013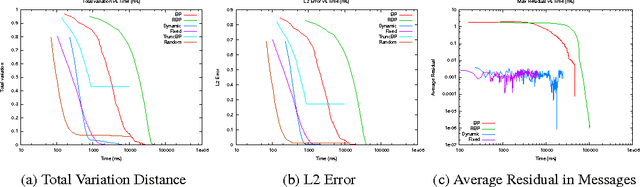
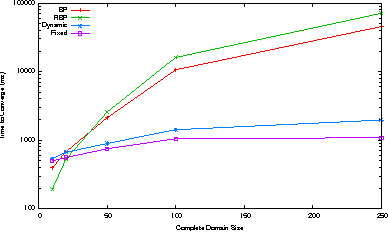
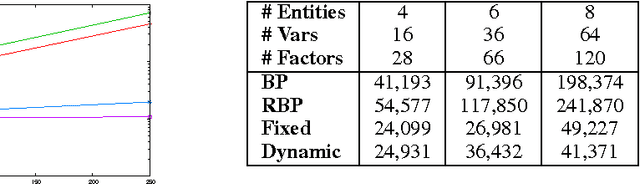
Belief Propagation has been widely used for marginal inference, however it is slow on problems with large-domain variables and high-order factors. Previous work provides useful approximations to facilitate inference on such models, but lacks important anytime properties such as: 1) providing accurate and consistent marginals when stopped early, 2) improving the approximation when run longer, and 3) converging to the fixed point of BP. To this end, we propose a message passing algorithm that works on sparse (partially instantiated) domains, and converges to consistent marginals using dynamic message scheduling. The algorithm grows the sparse domains incrementally, selecting the next value to add using prioritization schemes based on the gradients of the marginal inference objective. Our experiments demonstrate local anytime consistency and fast convergence, providing significant speedups over BP to obtain low-error marginals: up to 25 times on grid models, and up to 6 times on a real-world natural language processing task.
Automorphism Groups of Graphical Models and Lifted Variational Inference
Sep 26, 2013
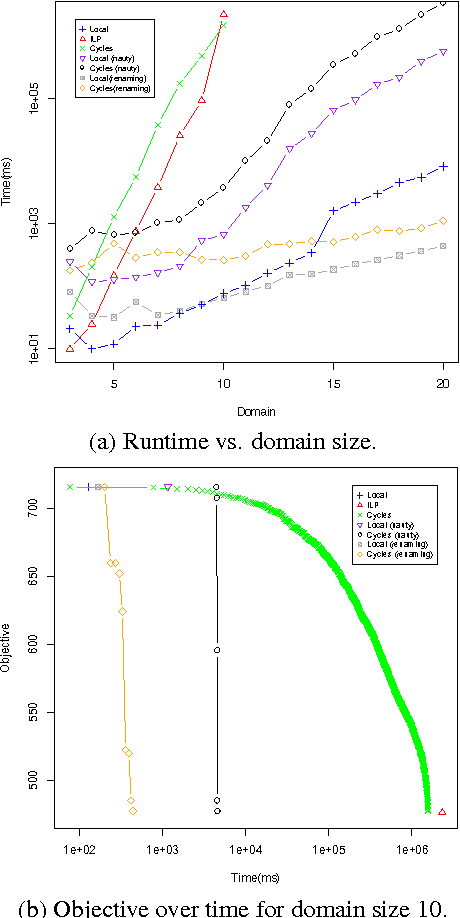
Using the theory of group action, we first introduce the concept of the automorphism group of an exponential family or a graphical model, thus formalizing the general notion of symmetry of a probabilistic model. This automorphism group provides a precise mathematical framework for lifted inference in the general exponential family. Its group action partitions the set of random variables and feature functions into equivalent classes (called orbits) having identical marginals and expectations. Then the inference problem is effectively reduced to that of computing marginals or expectations for each class, thus avoiding the need to deal with each individual variable or feature. We demonstrate the usefulness of this general framework in lifting two classes of variational approximation for maximum a posteriori (MAP) inference: local linear programming (LP) relaxation and local LP relaxation with cycle constraints; the latter yields the first lifted variational inference algorithm that operates on a bound tighter than the local constraints.
Latent Relation Representations for Universal Schemas
Jan 28, 2013Traditional relation extraction predicts relations within some fixed and finite target schema. Machine learning approaches to this task require either manual annotation or, in the case of distant supervision, existing structured sources of the same schema. The need for existing datasets can be avoided by using a universal schema: the union of all involved schemas (surface form predicates as in OpenIE, and relations in the schemas of pre-existing databases). This schema has an almost unlimited set of relations (due to surface forms), and supports integration with existing structured data (through the relation types of existing databases). To populate a database of such schema we present a family of matrix factorization models that predict affinity between database tuples and relations. We show that this achieves substantially higher accuracy than the traditional classification approach. More importantly, by operating simultaneously on relations observed in text and in pre-existing structured DBs such as Freebase, we are able to reason about unstructured and structured data in mutually-supporting ways. By doing so our approach outperforms state-of-the-art distant supervision systems.