 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint MoE Scaling Laws: Mixture of Experts Can Be Memory Efficient
Feb 07, 2025



Mixture of Experts (MoE) architectures have significantly increased computational efficiency in both research and real-world applications of large-scale machine learning models. However, their scalability and efficiency under memory constraints remain relatively underexplored. In this work, we present joint scaling laws for dense and MoE models, incorporating key factors such as the number of active parameters, dataset size, and the number of experts. Our findings provide a principled framework for selecting the optimal MoE configuration under fixed memory and compute budgets. Surprisingly, we show that MoE models can be more memory-efficient than dense models, contradicting conventional wisdom. To derive and validate the theoretical predictions of our scaling laws, we conduct over 280 experiments with up to 2.7B active parameters and up to 5B total parameters. These results offer actionable insights for designing and deploying MoE models in practical large-scale training scenarios.
Scaling Laws for Fine-Grained Mixture of Experts
Feb 12, 2024



Mixture of Experts (MoE) models have emerged as a primary solution for reducing the computational cost of Large Language Models. In this work, we analyze their scaling properties, incorporating an expanded range of variables. Specifically, we introduce a new hyperparameter, granularity, whose adjustment enables precise control over the size of the experts. Building on this, we establish scaling laws for fine-grained MoE, taking into account the number of training tokens, model size, and granularity. Leveraging these laws, we derive the optimal training configuration for a given computational budget. Our findings not only show that MoE models consistently outperform dense Transformers but also highlight that the efficiency gap between dense and MoE models widens as we scale up the model size and training budget. Furthermore, we demonstrate that the common practice of setting the size of experts in MoE to mirror the feed-forward layer is not optimal at almost any computational budget.
MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
Jan 08, 2024



State Space Models (SSMs) have become serious contenders in the field of sequential modeling, challenging the dominance of Transformers. At the same time, Mixture of Experts (MoE) has significantly improved Transformer-based LLMs, including recent state-of-the-art open-source models. We propose that to unlock the potential of SSMs for scaling, they should be combined with MoE. We showcase this on Mamba, a recent SSM-based model that achieves remarkable, Transformer-like performance. Our model, MoE-Mamba, outperforms both Mamba and Transformer-MoE. In particular, MoE-Mamba reaches the same performance as Mamba in 2.2x less training steps while preserving the inference performance gains of Mamba against the Transformer.
Structured Packing in LLM Training Improves Long Context Utilization
Jan 02, 2024Recent advances in long-context Large Language Models (LCLMs) have generated significant interest, especially in applications such as querying scientific research papers. However, their potential is often limited by inadequate context utilization. We identify the absence of long-range semantic dependencies in typical training data as a primary hindrance. To address this, we delve into the benefits of frequently incorporating related documents into training inputs. Using the inherent directory structure of code data as a source of training examples, we demonstrate improvements in perplexity, even for tasks unrelated to coding. Building on these findings, but with a broader focus, we introduce Structured Packing for Long Context (SPLiCe). SPLiCe is an innovative method for creating training examples by using a retrieval method to collate the most mutually relevant documents into a single training context. Our results indicate that \method{} enhances model performance and can be used to train large models to utilize long contexts better. We validate our results by training a large $3$B model, showing both perplexity improvements and better long-context performance on downstream tasks.
Mixture of Tokens: Efficient LLMs through Cross-Example Aggregation
Oct 24, 2023



Despite the promise of Mixture of Experts (MoE) models in increasing parameter counts of Transformer models while maintaining training and inference costs, their application carries notable drawbacks. The key strategy of these models is to, for each processed token, activate at most a few experts - subsets of an extensive feed-forward layer. But this approach is not without its challenges. The operation of matching experts and tokens is discrete, which makes MoE models prone to issues like training instability and uneven expert utilization. Existing techniques designed to address these concerns, such as auxiliary losses or balance-aware matching, result either in lower model performance or are more difficult to train. In response to these issues, we propose Mixture of Tokens, a fully-differentiable model that retains the benefits of MoE architectures while avoiding the aforementioned difficulties. Rather than routing tokens to experts, this approach mixes tokens from different examples prior to feeding them to experts, enabling the model to learn from all token-expert combinations. Importantly, this mixing can be disabled to avoid mixing of different sequences during inference. Crucially, this method is fully compatible with both masked and causal Large Language Model training and inference.
Sparse is Enough in Scaling Transformers
Nov 24, 2021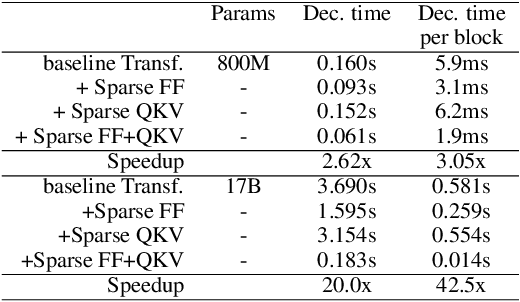
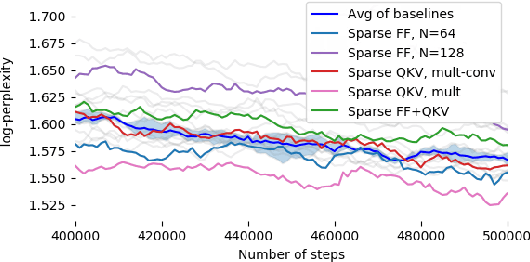
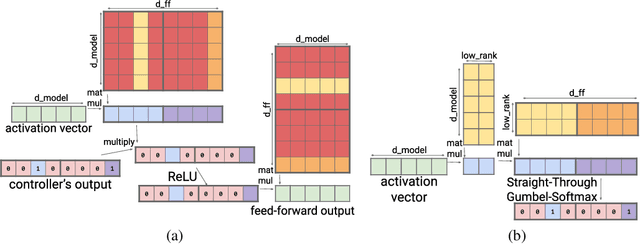
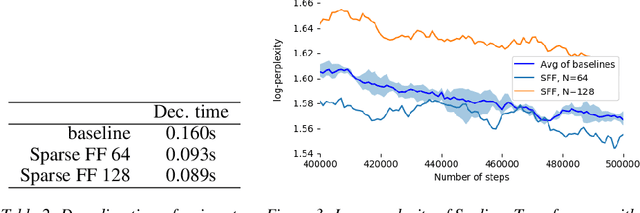
Large Transformer models yield impressive results on many tasks, but are expensive to train, or even fine-tune, and so slow at decoding that their use and study becomes out of reach. We address this problem by leveraging sparsity. We study sparse variants for all layers in the Transformer and propose Scaling Transformers, a family of next generation Transformer models that use sparse layers to scale efficiently and perform unbatched decoding much faster than the standard Transformer as we scale up the model size. Surprisingly, the sparse layers are enough to obtain the same perplexity as the standard Transformer with the same number of parameters. We also integrate with prior sparsity approaches to attention and enable fast inference on long sequences even with limited memory. This results in performance competitive to the state-of-the-art on long text summarization.
Neural heuristics for SAT solving
May 27, 2020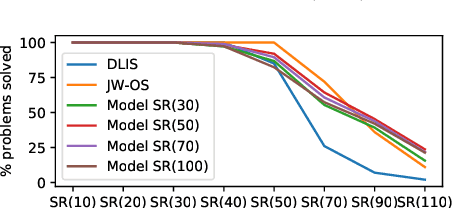
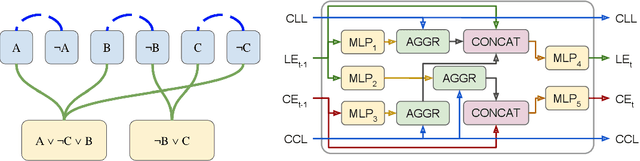
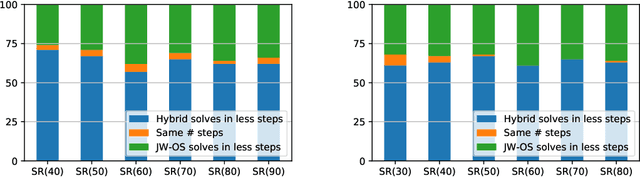
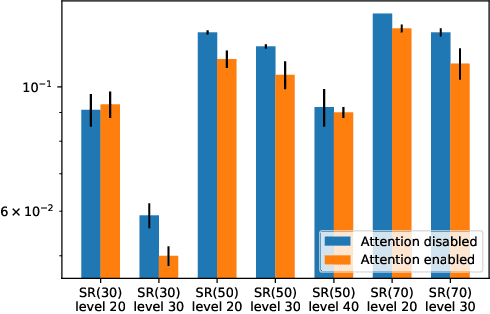
We use neural graph networks with a message-passing architecture and an attention mechanism to enhance the branching heuristic in two SAT-solving algorithms. We report improvements of learned neural heuristics compared with two standard human-designed heuristics.