 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards representation agnostic probabilistic programming
Dec 25, 2025Current probabilistic programming languages and tools tightly couple model representations with specific inference algorithms, preventing experimentation with novel representations or mixed discrete-continuous models. We introduce a factor abstraction with five fundamental operations that serve as a universal interface for manipulating factors regardless of their underlying representation. This enables representation-agnostic probabilistic programming where users can freely mix different representations (e.g. discrete tables, Gaussians distributions, sample-based approaches) within a single unified framework, allowing practical inference in complex hybrid models that current toolkits cannot adequately express.
Adaptive Noise Resilient Keyword Spotting Using One-Shot Learning
May 14, 2025Keyword spotting (KWS) is a key component of smart devices, enabling efficient and intuitive audio interaction. However, standard KWS systems deployed on embedded devices often suffer performance degradation under real-world operating conditions. Resilient KWS systems address this issue by enabling dynamic adaptation, with applications such as adding or replacing keywords, adjusting to specific users, and improving noise robustness. However, deploying resilient, standalone KWS systems with low latency on resource-constrained devices remains challenging due to limited memory and computational resources. This study proposes a low computational approach for continuous noise adaptation of pretrained neural networks used for KWS classification, requiring only 1-shot learning and one epoch. The proposed method was assessed using two pretrained models and three real-world noise sources at signal-to-noise ratios (SNRs) ranging from 24 to -3 dB. The adapted models consistently outperformed the pretrained models across all scenarios, especially at SNR $\leq$ 18 dB, achieving accuracy improvements of 4.9% to 46.0%. These results highlight the efficacy of the proposed methodology while being lightweight enough for deployment on resource-constrained devices.
On-Device Crack Segmentation for Edge Structural Health Monitoring
May 12, 2025Crack segmentation can play a critical role in Structural Health Monitoring (SHM) by enabling accurate identification of crack size and location, which allows to monitor structural damages over time. However, deploying deep learning models for crack segmentation on resource-constrained microcontrollers presents significant challenges due to limited memory, computational power, and energy resources. To address these challenges, this study explores lightweight U-Net architectures tailored for TinyML applications, focusing on three optimization strategies: filter number reduction, network depth reduction, and the use of Depthwise Separable Convolutions (DWConv2D). Our results demonstrate that reducing convolution kernels and network depth significantly reduces RAM and Flash requirement, and inference times, albeit with some accuracy trade-offs. Specifically, by reducing the filer number to 25%, the network depth to four blocks, and utilizing depthwise convolutions, a good compromise between segmentation performance and resource consumption is achieved. This makes the network particularly suitable for low-power TinyML applications. This study not only advances TinyML-based crack segmentation but also provides the possibility for energy-autonomous edge SHM systems.
Efficient Continual Learning in Keyword Spotting using Binary Neural Networks
May 05, 2025



Keyword spotting (KWS) is an essential function that enables interaction with ubiquitous smart devices. However, in resource-limited devices, KWS models are often static and can thus not adapt to new scenarios, such as added keywords. To overcome this problem, we propose a Continual Learning (CL) approach for KWS built on Binary Neural Networks (BNNs). The framework leverages the reduced computation and memory requirements of BNNs while incorporating techniques that enable the seamless integration of new keywords over time. This study evaluates seven CL techniques on a 16-class use case, reporting an accuracy exceeding 95% for a single additional keyword and up to 86% for four additional classes. Sensitivity to the amount of training samples in the CL phase, and differences in computational complexities are being evaluated. These evaluations demonstrate that batch-based algorithms are more sensitive to the CL dataset size, and that differences between the computational complexities are insignificant. These findings highlight the potential of developing an effective and computationally efficient technique for continuously integrating new keywords in KWS applications that is compatible with resource-constrained devices.
Survey of Quantization Techniques for On-Device Vision-based Crack Detection
Feb 04, 2025



Structural Health Monitoring (SHM) ensures the safety and longevity of infrastructure by enabling timely damage detection. Vision-based crack detection, combined with UAVs, addresses the limitations of traditional sensor-based SHM methods but requires the deployment of efficient deep learning models on resource-constrained devices. This study evaluates two lightweight convolutional neural network models, MobileNetV1x0.25 and MobileNetV2x0.5, across TensorFlow, PyTorch, and Open Neural Network Exchange platforms using three quantization techniques: dynamic quantization, post-training quantization (PTQ), and quantization-aware training (QAT). Results show that QAT consistently achieves near-floating-point accuracy, such as an F1-score of 0.8376 for MBNV2x0.5 with Torch-QAT, while maintaining efficient resource usage. PTQ significantly reduces memory and energy consumption but suffers from accuracy loss, particularly in TensorFlow. Dynamic quantization preserves accuracy but faces deployment challenges on PyTorch. By leveraging QAT, this work enables real-time, low-power crack detection on UAVs, enhancing safety, scalability, and cost-efficiency in SHM applications, while providing insights into balancing accuracy and efficiency across different platforms for autonomous inspections.
Comparison of Tiny Machine Learning Techniques for Embedded Acoustic Emission Analysis
Nov 22, 2024



This paper compares machine learning approaches with different input data formats for the classification of acoustic emission (AE) signals. AE signals are a promising monitoring technique in many structural health monitoring applications. Machine learning has been demonstrated as an effective data analysis method, classifying different AE signals according to the damage mechanism they represent. These classifications can be performed based on the entire AE waveform or specific features that have been extracted from it. However, it is currently unknown which of these approaches is preferred. With the goal of model deployment on resource-constrained embedded Internet of Things (IoT) systems, this work evaluates and compares both approaches in terms of classification accuracy, memory requirement, processing time, and energy consumption. To accomplish this, features are extracted and carefully selected, neural network models are designed and optimized for each input data scenario, and the models are deployed on a low-power IoT node. The comparative analysis reveals that all models can achieve high classification accuracies of over 99\%, but that embedded feature extraction is computationally expensive. Consequently, models utilizing the raw AE signal as input have the fastest processing speed and thus the lowest energy consumption, which comes at the cost of a larger memory requirement.
On-device Anomaly Detection in Conveyor Belt Operations
Nov 16, 2024



Mining 4.0 leverages advancements in automation, digitalization, and interconnected technologies from Industry 4.0 to address the unique challenges of the mining sector, enhancing efficiency, safety, and sustainability. Conveyor belts are crucial in mining operations by enabling the continuous and efficient movement of bulk materials over long distances, which directly impacts productivity. While detecting anomalies in specific conveyor belt components, such as idlers, pulleys, and belt surfaces, has been widely studied, identifying the root causes of these failures remains critical due to factors like changing production conditions and operator errors. Continuous monitoring of mining conveyor belt work cycles for anomaly detection is still at an early stage and requires robust solutions. This study proposes two distinctive pattern recognition approaches for real-time anomaly detection in the operational cycles of mining conveyor belts, combining feature extraction, threshold-based cycle detection, and tiny machine-learning classification. Both approaches outperformed a state-of-the-art technique on two datasets for duty cycle classification in terms of F1-scores. The first approach, with 97.3% and 80.2% for normal and abnormal cycles, respectively, reaches the highest performance in the first dataset while the second approach excels on the second dataset, scoring 91.3% and 67.9%. Implemented on two low-power microcontrollers, the methods demonstrated efficient, real-time operation with energy consumption of 13.3 and 20.6 ${\mu}$J during inference. These results offer valuable insights for detecting mechanical failure sources, supporting targeted preventive maintenance, and optimizing production cycles.
Towards Measuring Ethicality of an Intelligent Assistive System
Feb 28, 2023Artificial intelligence (AI) based assistive systems, so called intelligent assistive technology (IAT) are becoming increasingly ubiquitous by each day. IAT helps people in improving their quality of life by providing intelligent assistance based on the provided data. A few examples of such IATs include self-driving cars, robot assistants and smart-health management solutions. However, the presence of such autonomous entities poses ethical challenges concerning the stakeholders involved in using these systems. There is a lack of research when it comes to analysing how such IAT adheres to provided ethical regulations due to ethical, logistic and cost issues associated with such an analysis. In the light of the above-mentioned problem statement and issues, we present a method to measure the ethicality of an assistive system. To perform this task, we utilised our simulation tool that focuses on modelling navigation and assistance of Persons with Dementia (PwD) in indoor environments. By utilising this tool, we analyse how well different assistive strategies adhere to provided ethical regulations such as autonomy, justice and beneficence of the stakeholders.
An artificial neural network-based system for detecting machine failures using tiny sound data: A case study
Sep 23, 2022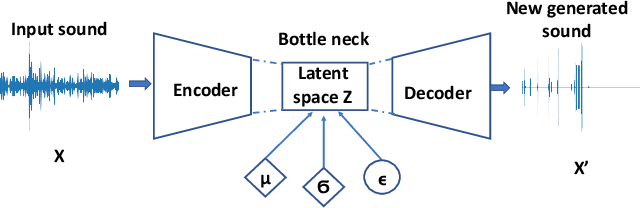
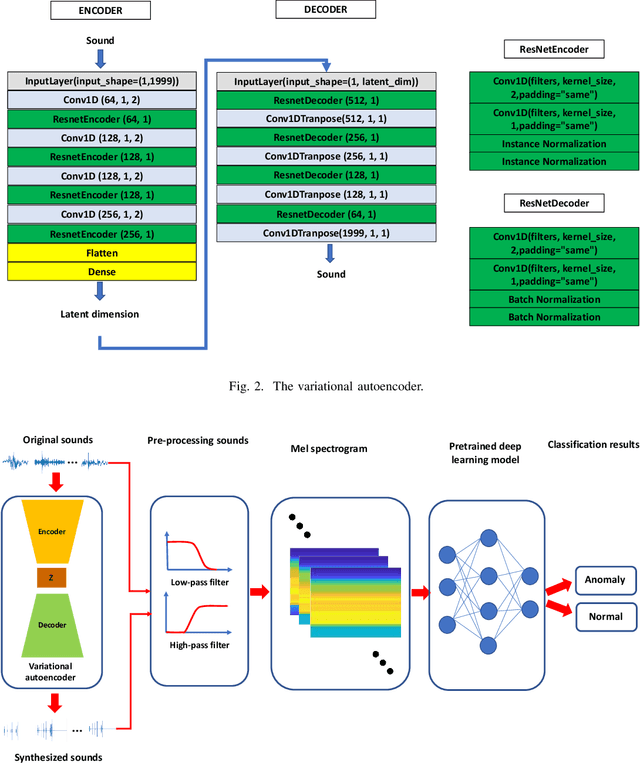
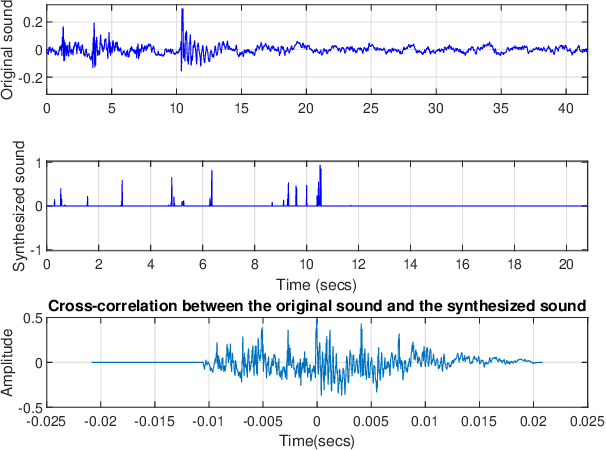
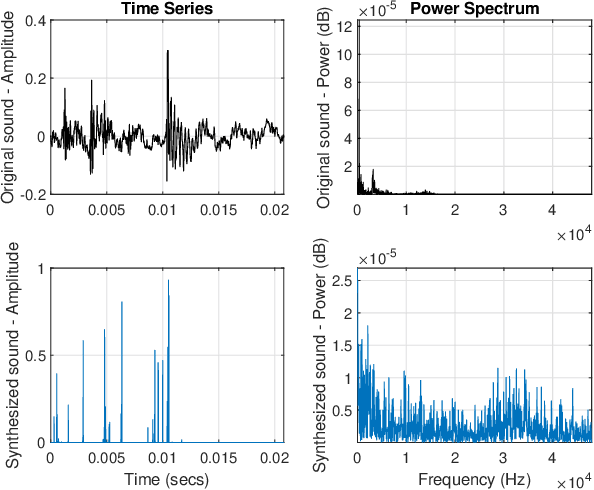
In an effort to advocate the research for a deep learning-based machine failure detection system, we present a case study of our proposed system based on a tiny sound dataset. Our case study investigates a variational autoencoder (VAE) for augmenting a small drill sound dataset from Valmet AB. A Valmet dataset contains 134 sounds that have been divided into two categories: "Anomaly" and "Normal" recorded from a drilling machine in Valmet AB, a company in Sundsvall, Sweden that supplies equipment and processes for the production of biofuels. Using deep learning models to detect failure drills on such a small sound dataset is typically unsuccessful. We employed a VAE to increase the number of sounds in the tiny dataset by synthesizing new sounds from original sounds. The augmented dataset was created by combining these synthesized sounds with the original sounds. We used a high-pass filter with a passband frequency of 1000 Hz and a low-pass filter with a passband frequency of 22\kern 0.16667em000 Hz to pre-process sounds in the augmented dataset before transforming them to Mel spectrograms. The pre-trained 2D-CNN Alexnet was then trained using these Mel spectrograms. When compared to using the original tiny sound dataset to train pre-trained Alexnet, using the augmented sound dataset enhanced the CNN model's classification results by 6.62\%(94.12\% when trained on the augmented dataset versus 87.5\% when trained on the original dataset).
Denoising Induction Motor Sounds Using an Autoencoder
Aug 08, 2022
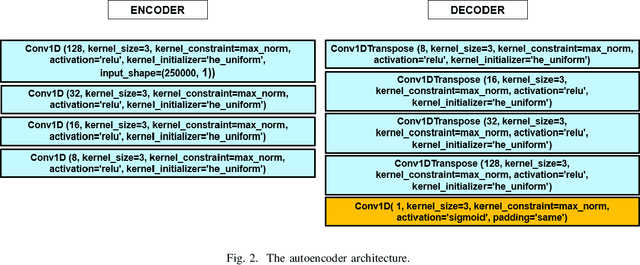
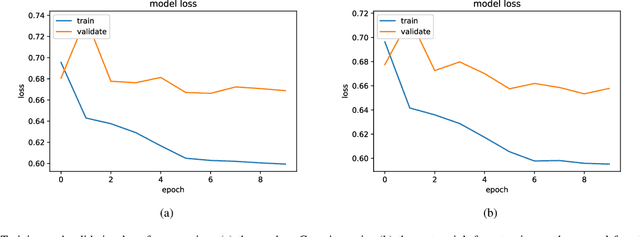
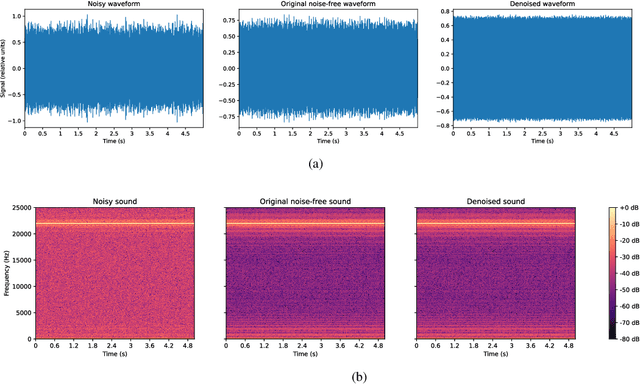
Denoising is the process of removing noise from sound signals while improving the quality and adequacy of the sound signals. Denoising sound has many applications in speech processing, sound events classification, and machine failure detection systems. This paper describes a method for creating an autoencoder to map noisy machine sounds to clean sounds for denoising purposes. There are several types of noise in sounds, for example, environmental noise and generated frequency-dependent noise from signal processing methods. Noise generated by environmental activities is environmental noise. In the factory, environmental noise can be created by vehicles, drilling, people working or talking in the survey area, wind, and flowing water. Those noises appear as spikes in the sound record. In the scope of this paper, we demonstrate the removal of generated noise with Gaussian distribution and the environmental noise with a specific example of the water sink faucet noise from the induction motor sounds. The proposed method was trained and verified on 49 normal function sounds and 197 horizontal misalignment fault sounds from the Machinery Fault Database (MAFAULDA). The mean square error (MSE) was used as the assessment criteria to evaluate the similarity between denoised sounds using the proposed autoencoder and the original sounds in the test set. The MSE is below or equal to 0.14 when denoise both types of noises on 15 testing sounds of the normal function category. The MSE is below or equal to 0.15 when denoising 60 testing sounds on the horizontal misalignment fault category. The low MSE shows that both the generated Gaussian noise and the environmental noise were almost removed from the original sounds with the proposed trained autoencoder.