 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKARL: Knowledge Agents via Reinforcement Learning
Mar 05, 2026We present a system for training enterprise search agents via reinforcement learning that achieves state-of-the-art performance across a diverse suite of hard-to-verify agentic search tasks. Our work makes four core contributions. First, we introduce KARLBench, a multi-capability evaluation suite spanning six distinct search regimes, including constraint-driven entity search, cross-document report synthesis, tabular numerical reasoning, exhaustive entity retrieval, procedural reasoning over technical documentation, and fact aggregation over internal enterprise notes. Second, we show that models trained across heterogeneous search behaviors generalize substantially better than those optimized for any single benchmark. Third, we develop an agentic synthesis pipeline that employs long-horizon reasoning and tool use to generate diverse, grounded, and high-quality training data, with iterative bootstrapping from increasingly capable models. Fourth, we propose a new post-training paradigm based on iterative large-batch off-policy RL that is sample efficient, robust to train-inference engine discrepancies, and naturally extends to multi-task training with out-of-distribution generalization. Compared to Claude 4.6 and GPT 5.2, KARL is Pareto-optimal on KARLBench across cost-quality and latency-quality trade-offs, including tasks that were out-of-distribution during training. With sufficient test-time compute, it surpasses the strongest closed models. These results show that tailored synthetic data in combination with multi-task reinforcement learning enables cost-efficient and high-performing knowledge agents for grounded reasoning.
Does your data spark joy? Performance gains from domain upsampling at the end of training
Jun 05, 2024



Pretraining datasets for large language models (LLMs) have grown to trillions of tokens composed of large amounts of CommonCrawl (CC) web scrape along with smaller, domain-specific datasets. It is expensive to understand the impact of these domain-specific datasets on model capabilities as training at large FLOP scales is required to reveal significant changes to difficult and emergent benchmarks. Given the increasing cost of experimenting with pretraining data, how does one determine the optimal balance between the diversity in general web scrapes and the information density of domain specific data? In this work, we show how to leverage the smaller domain specific datasets by upsampling them relative to CC at the end of training to drive performance improvements on difficult benchmarks. This simple technique allows us to improve up to 6.90 pp on MMLU, 8.26 pp on GSM8K, and 6.17 pp on HumanEval relative to the base data mix for a 7B model trained for 1 trillion (T) tokens, thus rivaling Llama-2 (7B)$\unicode{x2014}$a model trained for twice as long. We experiment with ablating the duration of domain upsampling from 5% to 30% of training and find that 10% to 20% percent is optimal for navigating the tradeoff between general language modeling capabilities and targeted benchmarks. We also use domain upsampling to characterize at scale the utility of individual datasets for improving various benchmarks by removing them during this final phase of training. This tool opens up the ability to experiment with the impact of different pretraining datasets at scale, but at an order of magnitude lower cost compared to full pretraining runs.
MLlib: Machine Learning in Apache Spark
May 26, 2015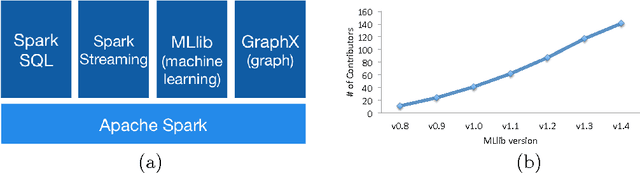
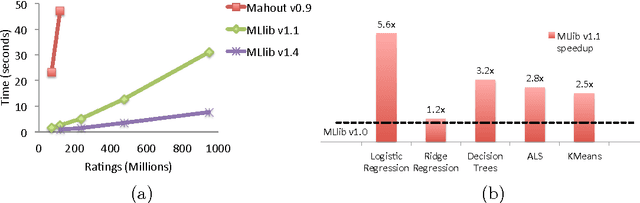
Apache Spark is a popular open-source platform for large-scale data processing that is well-suited for iterative machine learning tasks. In this paper we present MLlib, Spark's open-source distributed machine learning library. MLlib provides efficient functionality for a wide range of learning settings and includes several underlying statistical, optimization, and linear algebra primitives. Shipped with Spark, MLlib supports several languages and provides a high-level API that leverages Spark's rich ecosystem to simplify the development of end-to-end machine learning pipelines. MLlib has experienced a rapid growth due to its vibrant open-source community of over 140 contributors, and includes extensive documentation to support further growth and to let users quickly get up to speed.