 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyondScene: Higher-Resolution Human-Centric Scene Generation With Pretrained Diffusion
Apr 06, 2024



Generating higher-resolution human-centric scenes with details and controls remains a challenge for existing text-to-image diffusion models. This challenge stems from limited training image size, text encoder capacity (limited tokens), and the inherent difficulty of generating complex scenes involving multiple humans. While current methods attempted to address training size limit only, they often yielded human-centric scenes with severe artifacts. We propose BeyondScene, a novel framework that overcomes prior limitations, generating exquisite higher-resolution (over 8K) human-centric scenes with exceptional text-image correspondence and naturalness using existing pretrained diffusion models. BeyondScene employs a staged and hierarchical approach to initially generate a detailed base image focusing on crucial elements in instance creation for multiple humans and detailed descriptions beyond token limit of diffusion model, and then to seamlessly convert the base image to a higher-resolution output, exceeding training image size and incorporating details aware of text and instances via our novel instance-aware hierarchical enlargement process that consists of our proposed high-frequency injected forward diffusion and adaptive joint diffusion. BeyondScene surpasses existing methods in terms of correspondence with detailed text descriptions and naturalness, paving the way for advanced applications in higher-resolution human-centric scene creation beyond the capacity of pretrained diffusion models without costly retraining. Project page: https://janeyeon.github.io/beyond-scene.
Doubly Perturbed Task-Free Continual Learning
Dec 20, 2023



Task-free online continual learning (TF-CL) is a challenging problem where the model incrementally learns tasks without explicit task information. Although training with entire data from the past, present as well as future is considered as the gold standard, naive approaches in TF-CL with the current samples may be conflicted with learning with samples in the future, leading to catastrophic forgetting and poor plasticity. Thus, a proactive consideration of an unseen future sample in TF-CL becomes imperative. Motivated by this intuition, we propose a novel TF-CL framework considering future samples and show that injecting adversarial perturbations on both input data and decision-making is effective. Then, we propose a novel method named Doubly Perturbed Continual Learning (DPCL) to efficiently implement these input and decision-making perturbations. Specifically, for input perturbation, we propose an approximate perturbation method that injects noise into the input data as well as the feature vector and then interpolates the two perturbed samples. For decision-making process perturbation, we devise multiple stochastic classifiers. We also investigate a memory management scheme and learning rate scheduling reflecting our proposed double perturbations. We demonstrate that our proposed method outperforms the state-of-the-art baseline methods by large margins on various TF-CL benchmarks.
Deep Internal Learning: Deep Learning from a Single Input
Dec 12, 2023Deep learning in general focuses on training a neural network from large labeled datasets. Yet, in many cases there is value in training a network just from the input at hand. This may involve training a network from scratch using a single input or adapting an already trained network to a provided input example at inference time. This survey paper aims at covering deep internal-learning techniques that have been proposed in the past few years for these two important directions. While our main focus will be on image processing problems, most of the approaches that we survey are derived for general signals (vectors with recurring patterns that can be distinguished from noise) and are therefore applicable to other modalities. We believe that the topic of internal-learning is very important in many signal and image processing problems where training data is scarce and diversity is large on the one hand, and on the other, there is a lot of structure in the data that can be exploited.
Detailed Human-Centric Text Description-Driven Large Scene Synthesis
Nov 30, 2023



Text-driven large scene image synthesis has made significant progress with diffusion models, but controlling it is challenging. While using additional spatial controls with corresponding texts has improved the controllability of large scene synthesis, it is still challenging to faithfully reflect detailed text descriptions without user-provided controls. Here, we propose DetText2Scene, a novel text-driven large-scale image synthesis with high faithfulness, controllability, and naturalness in a global context for the detailed human-centric text description. Our DetText2Scene consists of 1) hierarchical keypoint-box layout generation from the detailed description by leveraging large language model (LLM), 2) view-wise conditioned joint diffusion process to synthesize a large scene from the given detailed text with LLM-generated grounded keypoint-box layout and 3) pixel perturbation-based pyramidal interpolation to progressively refine the large scene for global coherence. Our DetText2Scene significantly outperforms prior arts in text-to-large scene synthesis qualitatively and quantitatively, demonstrating strong faithfulness with detailed descriptions, superior controllability, and excellent naturalness in a global context.
On Exact Inversion of DPM-Solvers
Nov 30, 2023



Diffusion probabilistic models (DPMs) are a key component in modern generative models. DPM-solvers have achieved reduced latency and enhanced quality significantly, but have posed challenges to find the exact inverse (i.e., finding the initial noise from the given image). Here we investigate the exact inversions for DPM-solvers and propose algorithms to perform them when samples are generated by the first-order as well as higher-order DPM-solvers. For each explicit denoising step in DPM-solvers, we formulated the inversions using implicit methods such as gradient descent or forward step method to ensure the robustness to large classifier-free guidance unlike the prior approach using fixed-point iteration. Experimental results demonstrated that our proposed exact inversion methods significantly reduced the error of both image and noise reconstructions, greatly enhanced the ability to distinguish invisible watermarks and well prevented unintended background changes consistently during image editing. Project page: \url{https://smhongok.github.io/inv-dpm.html}.
Fully Quantized Always-on Face Detector Considering Mobile Image Sensors
Nov 02, 2023



Despite significant research on lightweight deep neural networks (DNNs) designed for edge devices, the current face detectors do not fully meet the requirements for "intelligent" CMOS image sensors (iCISs) integrated with embedded DNNs. These sensors are essential in various practical applications, such as energy-efficient mobile phones and surveillance systems with always-on capabilities. One noteworthy limitation is the absence of suitable face detectors for the always-on scenario, a crucial aspect of image sensor-level applications. These detectors must operate directly with sensor RAW data before the image signal processor (ISP) takes over. This gap poses a significant challenge in achieving optimal performance in such scenarios. Further research and development are necessary to bridge this gap and fully leverage the potential of iCIS applications. In this study, we aim to bridge the gap by exploring extremely low-bit lightweight face detectors, focusing on the always-on face detection scenario for mobile image sensor applications. To achieve this, our proposed model utilizes sensor-aware synthetic RAW inputs, simulating always-on face detection processed "before" the ISP chain. Our approach employs ternary (-1, 0, 1) weights for potential implementations in image sensors, resulting in a relatively simple network architecture with shallow layers and extremely low-bitwidth. Our method demonstrates reasonable face detection performance and excellent efficiency in simulation studies, offering promising possibilities for practical always-on face detectors in real-world applications.
Online Continual Learning on Hierarchical Label Expansion
Aug 28, 2023



Continual learning (CL) enables models to adapt to new tasks and environments without forgetting previously learned knowledge. While current CL setups have ignored the relationship between labels in the past task and the new task with or without small task overlaps, real-world scenarios often involve hierarchical relationships between old and new tasks, posing another challenge for traditional CL approaches. To address this challenge, we propose a novel multi-level hierarchical class incremental task configuration with an online learning constraint, called hierarchical label expansion (HLE). Our configuration allows a network to first learn coarse-grained classes, with data labels continually expanding to more fine-grained classes in various hierarchy depths. To tackle this new setup, we propose a rehearsal-based method that utilizes hierarchy-aware pseudo-labeling to incorporate hierarchical class information. Additionally, we propose a simple yet effective memory management and sampling strategy that selectively adopts samples of newly encountered classes. Our experiments demonstrate that our proposed method can effectively use hierarchy on our HLE setup to improve classification accuracy across all levels of hierarchies, regardless of depth and class imbalance ratio, outperforming prior state-of-the-art works by significant margins while also outperforming them on the conventional disjoint, blurry and i-Blurry CL setups.
Efficient Unified Demosaicing for Bayer and Non-Bayer Patterned Image Sensors
Jul 20, 2023As the physical size of recent CMOS image sensors (CIS) gets smaller, the latest mobile cameras are adopting unique non-Bayer color filter array (CFA) patterns (e.g., Quad, Nona, QxQ), which consist of homogeneous color units with adjacent pixels. These non-Bayer sensors are superior to conventional Bayer CFA thanks to their changeable pixel-bin sizes for different light conditions but may introduce visual artifacts during demosaicing due to their inherent pixel pattern structures and sensor hardware characteristics. Previous demosaicing methods have primarily focused on Bayer CFA, necessitating distinct reconstruction methods for non-Bayer patterned CIS with various CFA modes under different lighting conditions. In this work, we propose an efficient unified demosaicing method that can be applied to both conventional Bayer RAW and various non-Bayer CFAs' RAW data in different operation modes. Our Knowledge Learning-based demosaicing model for Adaptive Patterns, namely KLAP, utilizes CFA-adaptive filters for only 1% key filters in the network for each CFA, but still manages to effectively demosaic all the CFAs, yielding comparable performance to the large-scale models. Furthermore, by employing meta-learning during inference (KLAP-M), our model is able to eliminate unknown sensor-generic artifacts in real RAW data, effectively bridging the gap between synthetic images and real sensor RAW. Our KLAP and KLAP-M methods achieved state-of-the-art demosaicing performance in both synthetic and real RAW data of Bayer and non-Bayer CFAs.
Neural Diffeomorphic Non-uniform B-spline Flows
Apr 11, 2023Normalizing flows have been successfully modeling a complex probability distribution as an invertible transformation of a simple base distribution. However, there are often applications that require more than invertibility. For instance, the computation of energies and forces in physics requires the second derivatives of the transformation to be well-defined and continuous. Smooth normalizing flows employ infinitely differentiable transformation, but with the price of slow non-analytic inverse transforms. In this work, we propose diffeomorphic non-uniform B-spline flows that are at least twice continuously differentiable while bi-Lipschitz continuous, enabling efficient parametrization while retaining analytic inverse transforms based on a sufficient condition for diffeomorphism. Firstly, we investigate the sufficient condition for Ck-2-diffeomorphic non-uniform kth-order B-spline transformations. Then, we derive an analytic inverse transformation of the non-uniform cubic B-spline transformation for neural diffeomorphic non-uniform B-spline flows. Lastly, we performed experiments on solving the force matching problem in Boltzmann generators, demonstrating that our C2-diffeomorphic non-uniform B-spline flows yielded solutions better than previous spline flows and faster than smooth normalizing flows. Our source code is publicly available at https://github.com/smhongok/Non-uniform-B-spline-Flow.
DITTO-NeRF: Diffusion-based Iterative Text To Omni-directional 3D Model
Apr 06, 2023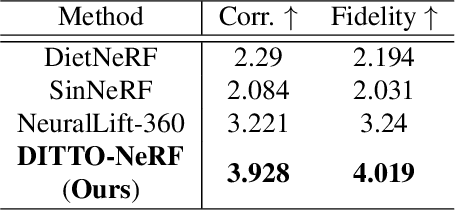

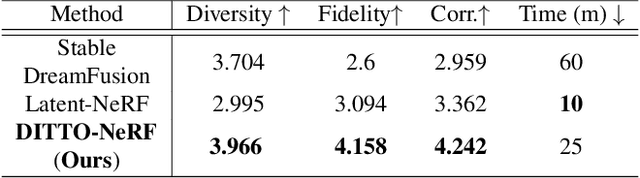

The increasing demand for high-quality 3D content creation has motivated the development of automated methods for creating 3D object models from a single image and/or from a text prompt. However, the reconstructed 3D objects using state-of-the-art image-to-3D methods still exhibit low correspondence to the given image and low multi-view consistency. Recent state-of-the-art text-to-3D methods are also limited, yielding 3D samples with low diversity per prompt with long synthesis time. To address these challenges, we propose DITTO-NeRF, a novel pipeline to generate a high-quality 3D NeRF model from a text prompt or a single image. Our DITTO-NeRF consists of constructing high-quality partial 3D object for limited in-boundary (IB) angles using the given or text-generated 2D image from the frontal view and then iteratively reconstructing the remaining 3D NeRF using inpainting latent diffusion model. We propose progressive 3D object reconstruction schemes in terms of scales (low to high resolution), angles (IB angles initially to outer-boundary (OB) later), and masks (object to background boundary) in our DITTO-NeRF so that high-quality information on IB can be propagated into OB. Our DITTO-NeRF outperforms state-of-the-art methods in terms of fidelity and diversity qualitatively and quantitatively with much faster training times than prior arts on image/text-to-3D such as DreamFusion, and NeuralLift-360.