 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMULTISEISMO: A Multimodal Seismic Dataset and Model for Cross-Modal Seismic Understanding
May 25, 2026The application of generalist multimodal models (GMMs) to specialized scientific domains remains limited due to the scarcity of comprehensive domain-specific datasets that integrate multiple data modalities beyond text and images. In seismology, understanding earthquake phenomena requires the synthesis of timeseries waveform data, geographical imagery, and contextual metadata, a multimodal integration absent in existing seismic datasets. We present MultiSeismo, a large scale structured multimodal seismic dataset, comprising over 16K seismic events spanning 13 years (2010 to 2023) across diverse geographical regions. Each event data integrates waveform recordings from global station networks, intensity maps, population exposure visualizations, and a comprehensive textual description within a standardized JSON format. We additionally develop MISCE, a multimodal instruction set on top of raw data to enable supervised training and evaluation of GMMs on seismic reasoning tasks ranging from basic information retrieval to complex cross modal analysis. We leverage MISCE to finetune an existing multimodal model (Unified IO 2) enhanced with a specialized timeseries encoder, which yields SeisModal, the first domain specific multimodal model for comprehensive seismic analysis. Evaluation of state of the art multimodal models on MultiSeismo reveals significant challenges, particularly with time-series data processing for general purpose models, while demonstrating SeisModal's superior performance on seismic multimodal reasoning tasks. These results prove that MultiSeismo provides a rigorous benchmark for future multimodal research in seismology and validate the success of our domain specific architectural adaptations.
In What Ways Are Deep Neural Networks Invariant and How Should We Measure This?
Oct 07, 2022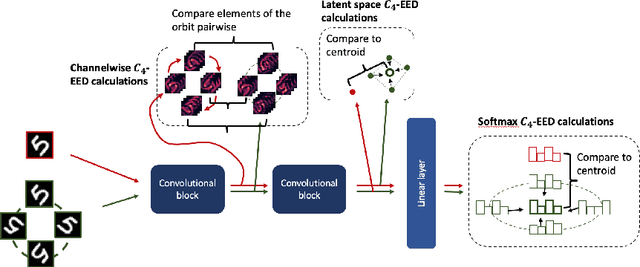
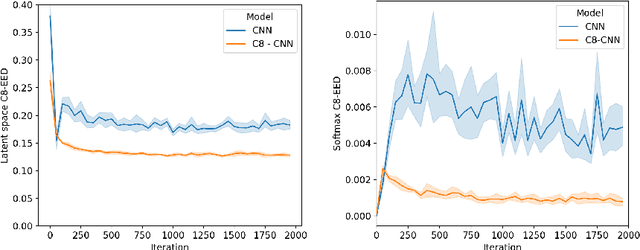
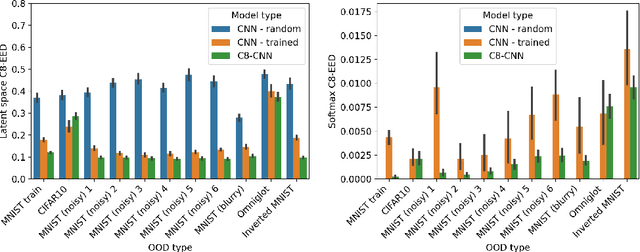
It is often said that a deep learning model is "invariant" to some specific type of transformation. However, what is meant by this statement strongly depends on the context in which it is made. In this paper we explore the nature of invariance and equivariance of deep learning models with the goal of better understanding the ways in which they actually capture these concepts on a formal level. We introduce a family of invariance and equivariance metrics that allows us to quantify these properties in a way that disentangles them from other metrics such as loss or accuracy. We use our metrics to better understand the two most popular methods used to build invariance into networks: data augmentation and equivariant layers. We draw a range of conclusions about invariance and equivariance in deep learning models, ranging from whether initializing a model with pretrained weights has an effect on a trained model's invariance, to the extent to which invariance learned via training can generalize to out-of-distribution data.