 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT Can Predict the Future when it Tells Stories Set in the Future About the Past
Apr 13, 2024This study investigates whether OpenAI's ChatGPT-3.5 and ChatGPT-4 can accurately forecast future events using two distinct prompting strategies. To evaluate the accuracy of the predictions, we take advantage of the fact that the training data at the time of experiment stopped at September 2021, and ask about events that happened in 2022 using ChatGPT-3.5 and ChatGPT-4. We employed two prompting strategies: direct prediction and what we call future narratives which ask ChatGPT to tell fictional stories set in the future with characters that share events that have happened to them, but after ChatGPT's training data had been collected. Concentrating on events in 2022, we prompted ChatGPT to engage in storytelling, particularly within economic contexts. After analyzing 100 prompts, we discovered that future narrative prompts significantly enhanced ChatGPT-4's forecasting accuracy. This was especially evident in its predictions of major Academy Award winners as well as economic trends, the latter inferred from scenarios where the model impersonated public figures like the Federal Reserve Chair, Jerome Powell. These findings indicate that narrative prompts leverage the models' capacity for hallucinatory narrative construction, facilitating more effective data synthesis and extrapolation than straightforward predictions. Our research reveals new aspects of LLMs' predictive capabilities and suggests potential future applications in analytical contexts.
Extracting Spatiotemporal Demand for Public Transit from Mobility Data
Jun 05, 2020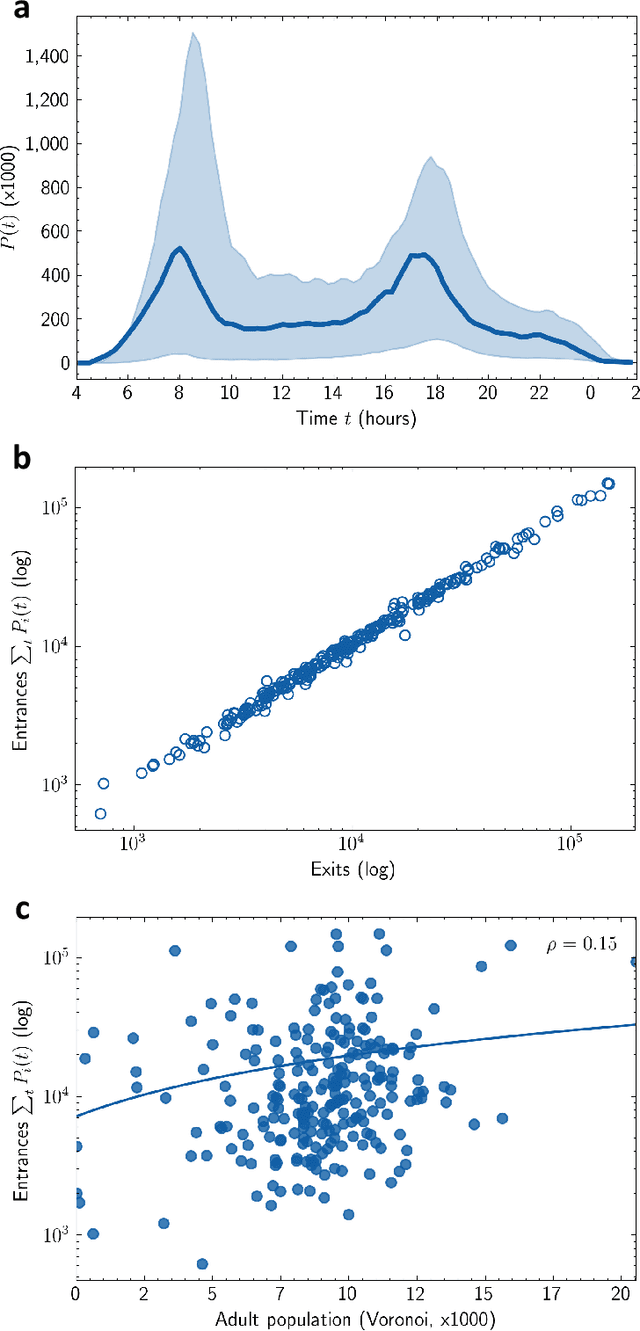
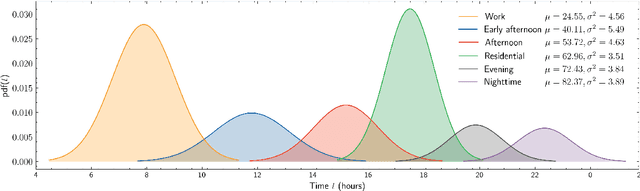
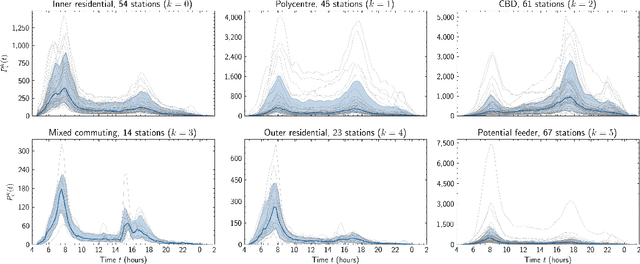
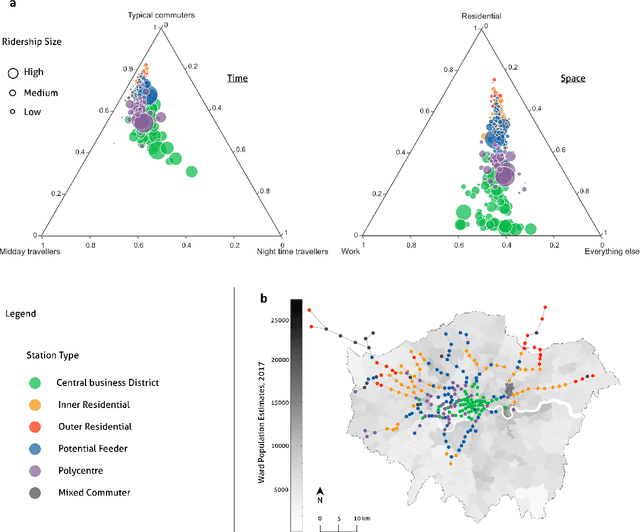
With people constantly migrating to different urban areas, our mobility needs for work, services and leisure are transforming rapidly. The changing urban demographics pose several challenges for the efficient management of transit services. To forecast transit demand, planners often resort to sociological investigations or modelling that are either difficult to obtain, inaccurate or outdated. How can we then estimate the variegated demand for mobility? We propose a simple method to identify the spatiotemporal demand for public transit in a city. Using a Gaussian mixture model, we decompose empirical ridership data into a set of temporal demand profiles representative of ridership over any given day. A case of approximately 4.6 million daily transit traces from the Greater London region reveals distinct demand profiles. We find that a weighted mixture of these profiles can generate any station traffic remarkably well, uncovering spatially concentric clusters of mobility needs. Our method of analysing the spatiotemporal geography of a city can be extended to other urban regions with different modes of public transit.