 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffTAD: Temporal Action Detection with Proposal Denoising Diffusion
Mar 27, 2023We propose a new formulation of temporal action detection (TAD) with denoising diffusion, DiffTAD in short. Taking as input random temporal proposals, it can yield action proposals accurately given an untrimmed long video. This presents a generative modeling perspective, against previous discriminative learning manners. This capability is achieved by first diffusing the ground-truth proposals to random ones (i.e., the forward/noising process) and then learning to reverse the noising process (i.e., the backward/denoising process). Concretely, we establish the denoising process in the Transformer decoder (e.g., DETR) by introducing a temporal location query design with faster convergence in training. We further propose a cross-step selective conditioning algorithm for inference acceleration. Extensive evaluations on ActivityNet and THUMOS show that our DiffTAD achieves top performance compared to previous art alternatives. The code will be made available at https://github.com/sauradip/DiffusionTAD.
PersonalTailor: Personalizing 2D Pattern Design from 3D Garment Point Clouds
Mar 17, 2023



Garment pattern design aims to convert a 3D garment to the corresponding 2D panels and their sewing structure. Existing methods rely either on template fitting with heuristics and prior assumptions, or on model learning with complicated shape parameterization. Importantly, both approaches do not allow for personalization of the output garment, which today has increasing demands. To fill this demand, we introduce PersonalTailor: a personalized 2D pattern design method, where the user can input specific constraints or demands (in language or sketch) for personal 2D panel fabrication from 3D point clouds. PersonalTailor first learns a multi-modal panel embeddings based on unsupervised cross-modal association and attentive fusion. It then predicts a binary panel masks individually using a transformer encoder-decoder framework. Extensive experiments show that our PersonalTailor excels on both personalized and standard pattern fabrication tasks.
Multi-Modal Few-Shot Temporal Action Detection via Vision-Language Meta-Adaptation
Nov 27, 2022



Few-shot (FS) and zero-shot (ZS) learning are two different approaches for scaling temporal action detection (TAD) to new classes. The former adapts a pretrained vision model to a new task represented by as few as a single video per class, whilst the latter requires no training examples by exploiting a semantic description of the new class. In this work, we introduce a new multi-modality few-shot (MMFS) TAD problem, which can be considered as a marriage of FS-TAD and ZS-TAD by leveraging few-shot support videos and new class names jointly. To tackle this problem, we further introduce a novel MUlti-modality PromPt mETa-learning (MUPPET) method. This is enabled by efficiently bridging pretrained vision and language models whilst maximally reusing already learned capacity. Concretely, we construct multi-modal prompts by mapping support videos into the textual token space of a vision-language model using a meta-learned adapter-equipped visual semantics tokenizer. To tackle large intra-class variation, we further design a query feature regulation scheme. Extensive experiments on ActivityNetv1.3 and THUMOS14 demonstrate that our MUPPET outperforms state-of-the-art alternative methods, often by a large margin. We also show that our MUPPET can be easily extended to tackle the few-shot object detection problem and again achieves the state-of-the-art performance on MS-COCO dataset. The code will be available in https://github.com/sauradip/MUPPET
Post-Processing Temporal Action Detection
Nov 27, 2022Existing Temporal Action Detection (TAD) methods typically take a pre-processing step in converting an input varying-length video into a fixed-length snippet representation sequence, before temporal boundary estimation and action classification. This pre-processing step would temporally downsample the video, reducing the inference resolution and hampering the detection performance in the original temporal resolution. In essence, this is due to a temporal quantization error introduced during the resolution downsampling and recovery. This could negatively impact the TAD performance, but is largely ignored by existing methods. To address this problem, in this work we introduce a novel model-agnostic post-processing method without model redesign and retraining. Specifically, we model the start and end points of action instances with a Gaussian distribution for enabling temporal boundary inference at a sub-snippet level. We further introduce an efficient Taylor-expansion based approximation, dubbed as Gaussian Approximated Post-processing (GAP). Extensive experiments demonstrate that our GAP can consistently improve a wide variety of pre-trained off-the-shelf TAD models on the challenging ActivityNet (+0.2% -0.7% in average mAP) and THUMOS (+0.2% -0.5% in average mAP) benchmarks. Such performance gains are already significant and highly comparable to those achieved by novel model designs. Also, GAP can be integrated with model training for further performance gain. Importantly, GAP enables lower temporal resolutions for more efficient inference, facilitating low-resource applications. The code will be available in https://github.com/sauradip/GAP
Large-Scale Product Retrieval with Weakly Supervised Representation Learning
Aug 01, 2022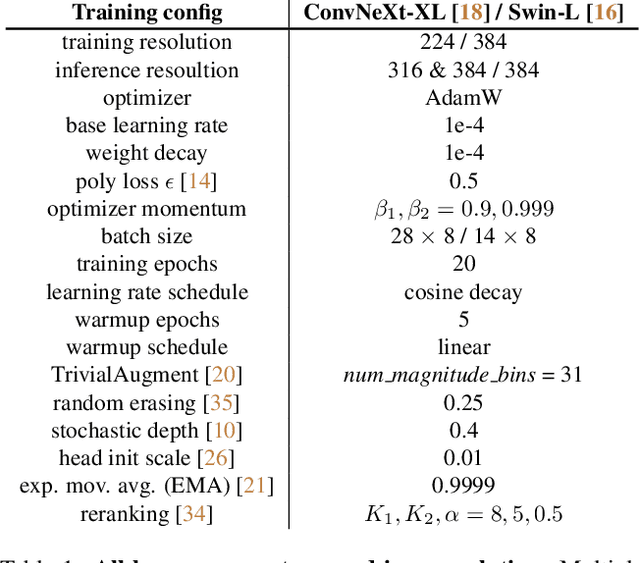
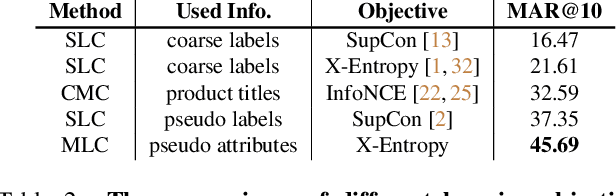
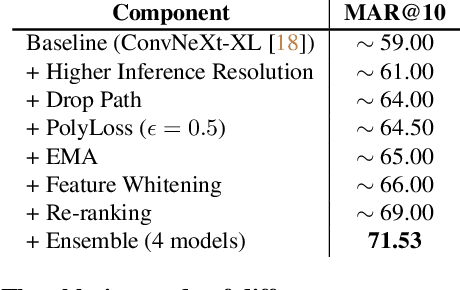
Large-scale weakly supervised product retrieval is a practically useful yet computationally challenging problem. This paper introduces a novel solution for the eBay Visual Search Challenge (eProduct) held at the Ninth Workshop on Fine-Grained Visual Categorisation workshop (FGVC9) of CVPR 2022. This competition presents two challenges: (a) E-commerce is a drastically fine-grained domain including many products with subtle visual differences; (b) A lacking of target instance-level labels for model training, with only coarse category labels and product titles available. To overcome these obstacles, we formulate a strong solution by a set of dedicated designs: (a) Instead of using text training data directly, we mine thousands of pseudo-attributes from product titles and use them as the ground truths for multi-label classification. (b) We incorporate several strong backbones with advanced training recipes for more discriminative representation learning. (c) We further introduce a number of post-processing techniques including whitening, re-ranking and model ensemble for retrieval enhancement. By achieving 71.53% MAR, our solution "Involution King" achieves the second position on the leaderboard.
Zero-Shot Temporal Action Detection via Vision-Language Prompting
Jul 17, 2022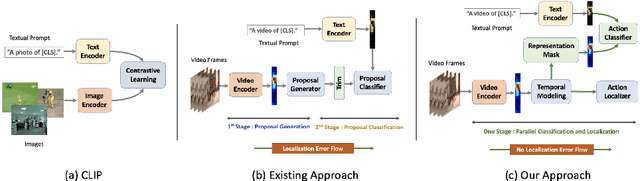
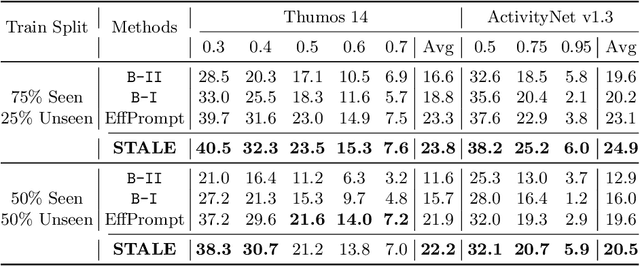
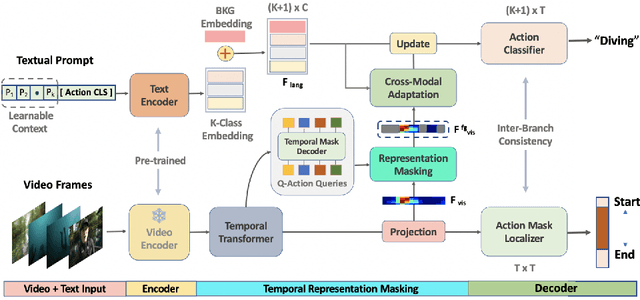
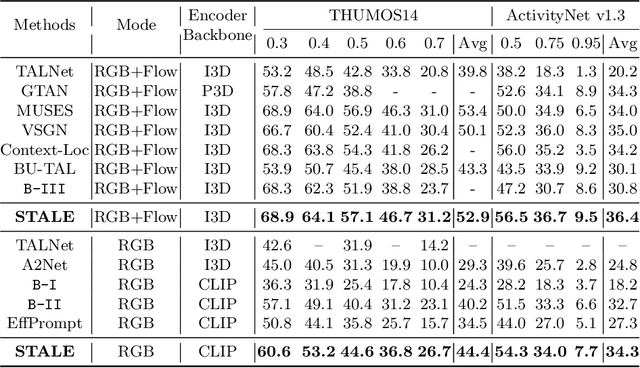
Existing temporal action detection (TAD) methods rely on large training data including segment-level annotations, limited to recognizing previously seen classes alone during inference. Collecting and annotating a large training set for each class of interest is costly and hence unscalable. Zero-shot TAD (ZS-TAD) resolves this obstacle by enabling a pre-trained model to recognize any unseen action classes. Meanwhile, ZS-TAD is also much more challenging with significantly less investigation. Inspired by the success of zero-shot image classification aided by vision-language (ViL) models such as CLIP, we aim to tackle the more complex TAD task. An intuitive method is to integrate an off-the-shelf proposal detector with CLIP style classification. However, due to the sequential localization (e.g, proposal generation) and classification design, it is prone to localization error propagation. To overcome this problem, in this paper we propose a novel zero-Shot Temporal Action detection model via Vision-LanguagE prompting (STALE). Such a novel design effectively eliminates the dependence between localization and classification by breaking the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for improved optimization. Extensive experiments on standard ZS-TAD video benchmarks show that our STALE significantly outperforms state-of-the-art alternatives. Besides, our model also yields superior results on supervised TAD over recent strong competitors. The PyTorch implementation of STALE is available at https://github.com/sauradip/STALE.
Semi-Supervised Temporal Action Detection with Proposal-Free Masking
Jul 14, 2022
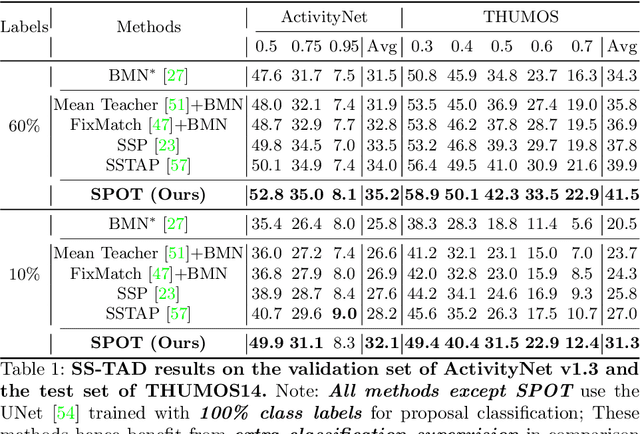
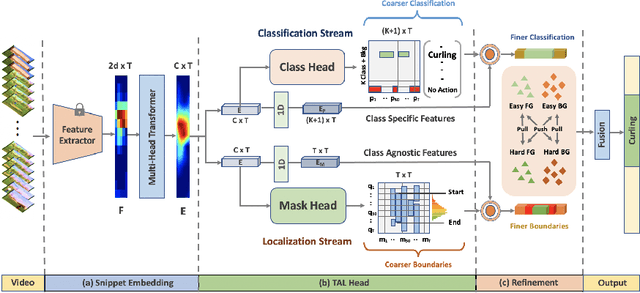
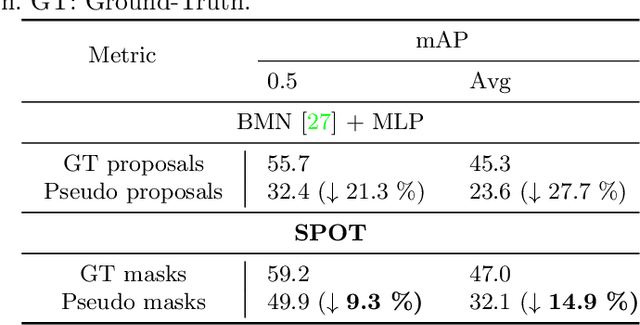
Existing temporal action detection (TAD) methods rely on a large number of training data with segment-level annotations. Collecting and annotating such a training set is thus highly expensive and unscalable. Semi-supervised TAD (SS-TAD) alleviates this problem by leveraging unlabeled videos freely available at scale. However, SS-TAD is also a much more challenging problem than supervised TAD, and consequently much under-studied. Prior SS-TAD methods directly combine an existing proposal-based TAD method and a SSL method. Due to their sequential localization (e.g, proposal generation) and classification design, they are prone to proposal error propagation. To overcome this limitation, in this work we propose a novel Semi-supervised Temporal action detection model based on PropOsal-free Temporal mask (SPOT) with a parallel localization (mask generation) and classification architecture. Such a novel design effectively eliminates the dependence between localization and classification by cutting off the route for error propagation in-between. We further introduce an interaction mechanism between classification and localization for prediction refinement, and a new pretext task for self-supervised model pre-training. Extensive experiments on two standard benchmarks show that our SPOT outperforms state-of-the-art alternatives, often by a large margin. The PyTorch implementation of SPOT is available at https://github.com/sauradip/SPOT
Temporal Action Detection with Global Segmentation Mask Learning
Jul 14, 2022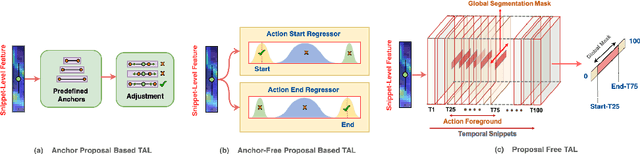
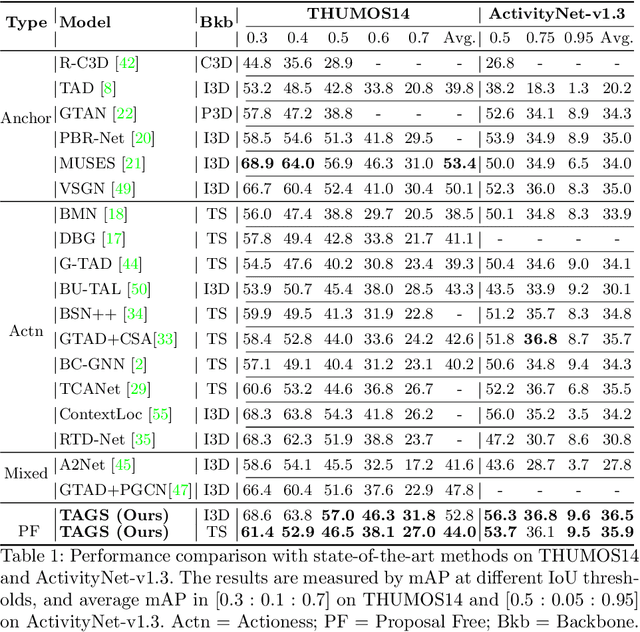
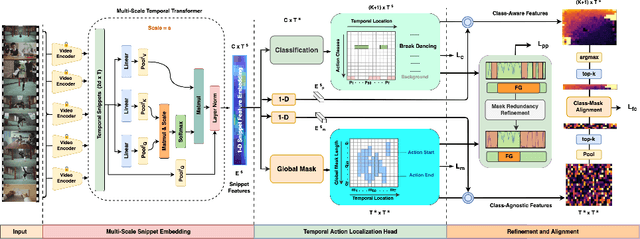
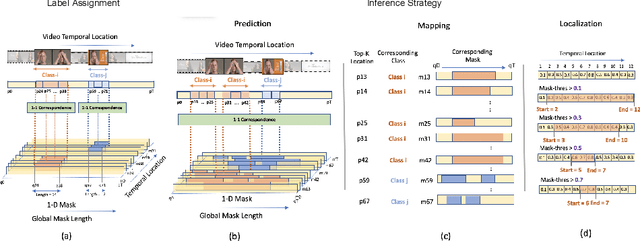
Existing temporal action detection (TAD) methods rely on generating an overwhelmingly large number of proposals per video. This leads to complex model designs due to proposal generation and/or per-proposal action instance evaluation and the resultant high computational cost. In this work, for the first time, we propose a proposal-free Temporal Action detection model with Global Segmentation mask (TAGS). Our core idea is to learn a global segmentation mask of each action instance jointly at the full video length. The TAGS model differs significantly from the conventional proposal-based methods by focusing on global temporal representation learning to directly detect local start and end points of action instances without proposals. Further, by modeling TAD holistically rather than locally at the individual proposal level, TAGS needs a much simpler model architecture with lower computational cost. Extensive experiments show that despite its simpler design, TAGS outperforms existing TAD methods, achieving new state-of-the-art performance on two benchmarks. Importantly, it is ~ 20x faster to train and ~1.6x more efficient for inference. Our PyTorch implementation of TAGS is available at https://github.com/sauradip/TAGS .
How Far Can I Go ? : A Self-Supervised Approach for Deterministic Video Depth Forecasting
Jul 08, 2022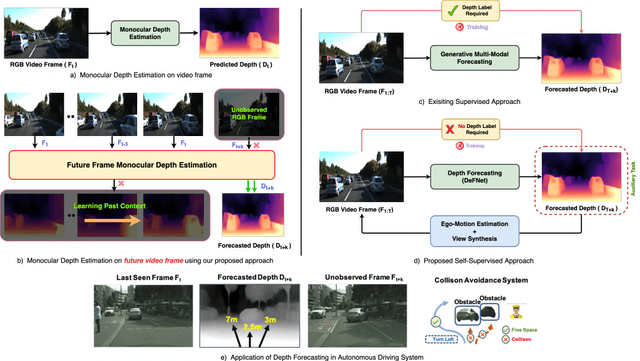
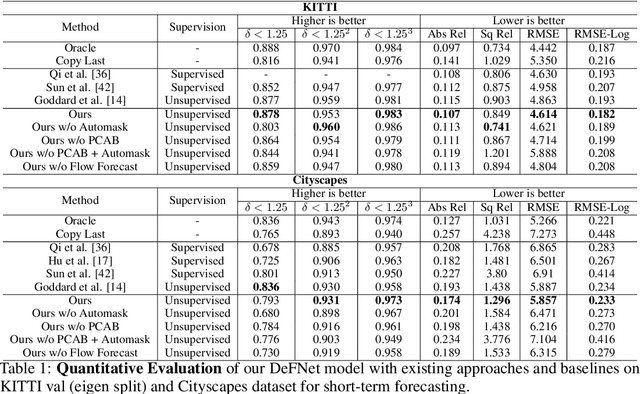
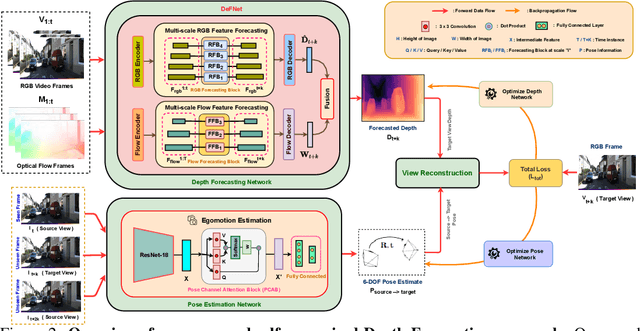
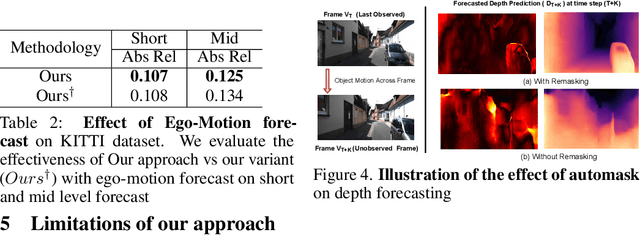
In this paper we present a novel self-supervised method to anticipate the depth estimate for a future, unobserved real-world urban scene. This work is the first to explore self-supervised learning for estimation of monocular depth of future unobserved frames of a video. Existing works rely on a large number of annotated samples to generate the probabilistic prediction of depth for unseen frames. However, this makes it unrealistic due to its requirement for large amount of annotated depth samples of video. In addition, the probabilistic nature of the case, where one past can have multiple future outcomes often leads to incorrect depth estimates. Unlike previous methods, we model the depth estimation of the unobserved frame as a view-synthesis problem, which treats the depth estimate of the unseen video frame as an auxiliary task while synthesizing back the views using learned pose. This approach is not only cost effective - we do not use any ground truth depth for training (hence practical) but also deterministic (a sequence of past frames map to an immediate future). To address this task we first develop a novel depth forecasting network DeFNet which estimates depth of unobserved future by forecasting latent features. Second, we develop a channel-attention based pose estimation network that estimates the pose of the unobserved frame. Using this learned pose, estimated depth map is reconstructed back into the image domain, thus forming a self-supervised solution. Our proposed approach shows significant improvements in Abs Rel metric compared to state-of-the-art alternatives on both short and mid-term forecasting setting, benchmarked on KITTI and Cityscapes. Code is available at https://github.com/sauradip/depthForecasting
Few-Shot Temporal Action Localization with Query Adaptive Transformer
Oct 20, 2021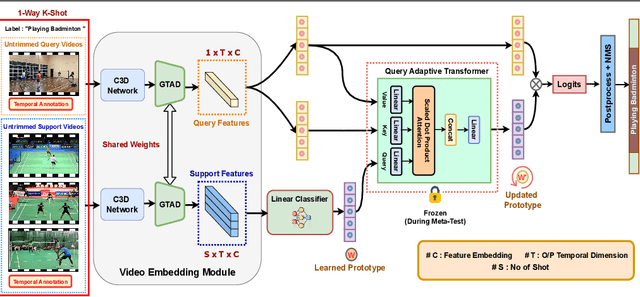
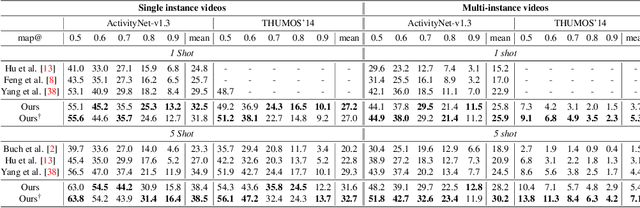
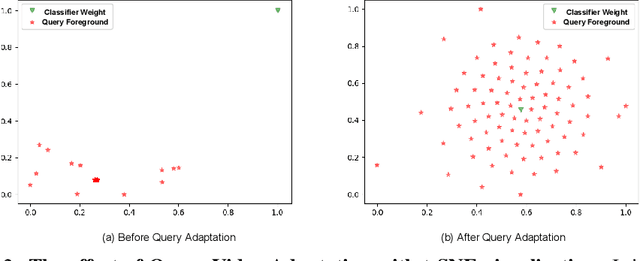
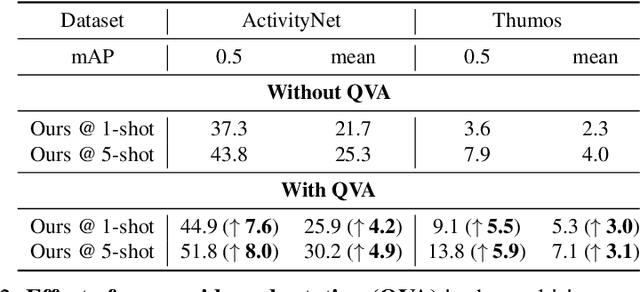
Existing temporal action localization (TAL) works rely on a large number of training videos with exhaustive segment-level annotation, preventing them from scaling to new classes. As a solution to this problem, few-shot TAL (FS-TAL) aims to adapt a model to a new class represented by as few as a single video. Exiting FS-TAL methods assume trimmed training videos for new classes. However, this setting is not only unnatural actions are typically captured in untrimmed videos, but also ignores background video segments containing vital contextual cues for foreground action segmentation. In this work, we first propose a new FS-TAL setting by proposing to use untrimmed training videos. Further, a novel FS-TAL model is proposed which maximizes the knowledge transfer from training classes whilst enabling the model to be dynamically adapted to both the new class and each video of that class simultaneously. This is achieved by introducing a query adaptive Transformer in the model. Extensive experiments on two action localization benchmarks demonstrate that our method can outperform all the state of the art alternatives significantly in both single-domain and cross-domain scenarios. The source code can be found in https://github.com/sauradip/fewshotQAT