 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentNLQ: A General-Purpose Agent for Natural Language to SQL
May 18, 2026Natural language to SQL (NL2SQL) conversion is an important problem for researchers and enterprises due to the ubiquitous importance of relational databases in broad-ranging practical problems. Despite the rapid advancements in the capabilities of LLMs, NL2SQL has not reached parity in accuracy with human expert SQL writers, hence needing additional improvements in NL2SQL algorithms. This study presents a new multi-agent method for NL2SQL that achieves 78.1% semantic accuracy on the BIg Bench for LaRge-scale Database (BIRD) benchmark. Our method leverages a semantically enriched representation of user-provided schema, adds user-provided business rules, and produces accurate SQL queries. The main contributions of this study are (a) We designed an optimized new orchestrator in a multi-agent solution that uses LLMs to plan, orchestrate, reflect, and self-correct to generate accurate SQL queries, (b) We developed an advanced schema enrichment method that creates context-aware metadata to improve accuracy, and (c) We demonstrated the accuracy and generalizability of the method across different domains and datasets by evaluating it on the BIRD-SQL benchmark.
RakutenAI-7B: Extending Large Language Models for Japanese
Mar 21, 2024



We introduce RakutenAI-7B, a suite of Japanese-oriented large language models that achieve the best performance on the Japanese LM Harness benchmarks among the open 7B models. Along with the foundation model, we release instruction- and chat-tuned models, RakutenAI-7B-instruct and RakutenAI-7B-chat respectively, under the Apache 2.0 license.
Comparative Snippet Generation
Jun 11, 2022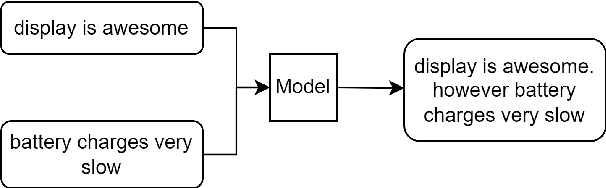


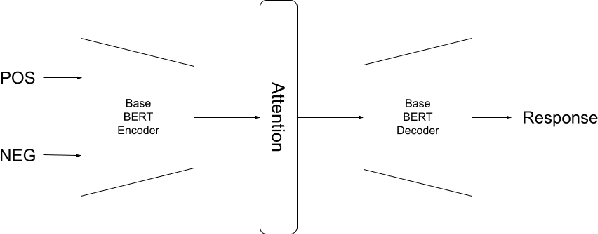
We model product reviews to generate comparative responses consisting of positive and negative experiences regarding the product. Specifically, we generate a single-sentence, comparative response from a given positive and a negative opinion. We contribute the first dataset for this task of Comparative Snippet Generation from contrasting opinions regarding a product, and a performance analysis of a pre-trained BERT model to generate such snippets.
MRCBert: A Machine Reading ComprehensionApproach for Unsupervised Summarization
May 01, 2021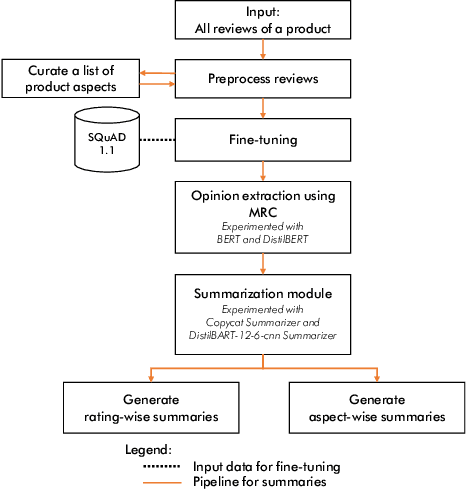

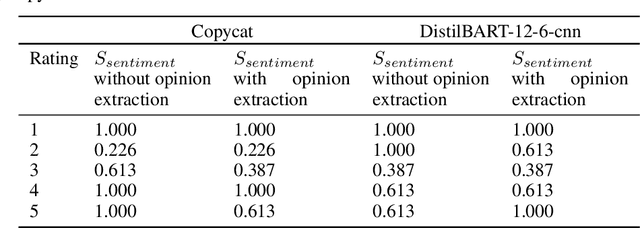
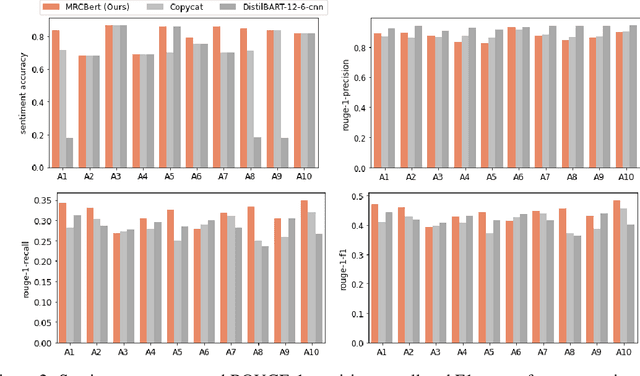
When making an online purchase, it becomes important for the customer to read the product reviews carefully and make a decision based on that. However, reviews can be lengthy, may contain repeated, or sometimes irrelevant information that does not help in decision making. In this paper, we introduce MRCBert, a novel unsupervised method to generate summaries from product reviews. We leverage Machine Reading Comprehension, i.e. MRC, approach to extract relevant opinions and generate both rating-wise and aspect-wise summaries from reviews. Through MRCBert we show that we can obtain reasonable performance using existing models and transfer learning, which can be useful for learning under limited or low resource scenarios. We demonstrated our results on reviews of a product from the Electronics category in the Amazon Reviews dataset. Our approach is unsupervised as it does not require any domain-specific dataset, such as the product review dataset, for training or fine-tuning. Instead, we have used SQuAD v1.1 dataset only to fine-tune BERT for the MRC task. Since MRCBert does not require a task-specific dataset, it can be easily adapted and used in other domains.