 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn End-to-end Planning Framework with Agentic LLMs and PDDL
Dec 10, 2025We present an end-to-end framework for planning supported by verifiers. An orchestrator receives a human specification written in natural language and converts it into a PDDL (Planning Domain Definition Language) model, where the domain and problem are iteratively refined by sub-modules (agents) to address common planning requirements, such as time constraints and optimality, as well as ambiguities and contradictions that may exist in the human specification. The validated domain and problem are then passed to an external planning engine to generate a plan. The orchestrator and agents are powered by Large Language Models (LLMs) and require no human intervention at any stage of the process. Finally, a module translates the final plan back into natural language to improve human readability while maintaining the correctness of each step. We demonstrate the flexibility and effectiveness of our framework across various domains and tasks, including the Google NaturalPlan benchmark and PlanBench, as well as planning problems like Blocksworld and the Tower of Hanoi (where LLMs are known to struggle even with small instances). Our framework can be integrated with any PDDL planning engine and validator (such as Fast Downward, LPG, POPF, VAL, and uVAL, which we have tested) and represents a significant step toward end-to-end planning aided by LLMs.
Trust in Vision-Language Models: Insights from a Participatory User Workshop
Nov 17, 2025With the growing deployment of Vision-Language Models (VLMs), pre-trained on large image-text and video-text datasets, it is critical to equip users with the tools to discern when to trust these systems. However, examining how user trust in VLMs builds and evolves remains an open problem. This problem is exacerbated by the increasing reliance on AI models as judges for experimental validation, to bypass the cost and implications of running participatory design studies directly with users. Following a user-centred approach, this paper presents preliminary results from a workshop with prospective VLM users. Insights from this pilot workshop inform future studies aimed at contextualising trust metrics and strategies for participants' engagement to fit the case of user-VLM interaction.
Mapping User Trust in Vision Language Models: Research Landscape, Challenges, and Prospects
May 08, 2025The rapid adoption of Vision Language Models (VLMs), pre-trained on large image-text and video-text datasets, calls for protecting and informing users about when to trust these systems. This survey reviews studies on trust dynamics in user-VLM interactions, through a multi-disciplinary taxonomy encompassing different cognitive science capabilities, collaboration modes, and agent behaviours. Literature insights and findings from a workshop with prospective VLM users inform preliminary requirements for future VLM trust studies.
Learning Interpretable Heuristics for WalkSAT
Jul 10, 2023Local search algorithms are well-known methods for solving large, hard instances of the satisfiability problem (SAT). The performance of these algorithms crucially depends on heuristics for setting noise parameters and scoring variables. The optimal setting for these heuristics varies for different instance distributions. In this paper, we present an approach for learning effective variable scoring functions and noise parameters by using reinforcement learning. We consider satisfiability problems from different instance distributions and learn specialized heuristics for each of them. Our experimental results show improvements with respect to both a WalkSAT baseline and another local search learned heuristic.
Extracting Lifted Mutual Exclusion Invariants from Temporal Planning Domains
Feb 07, 2017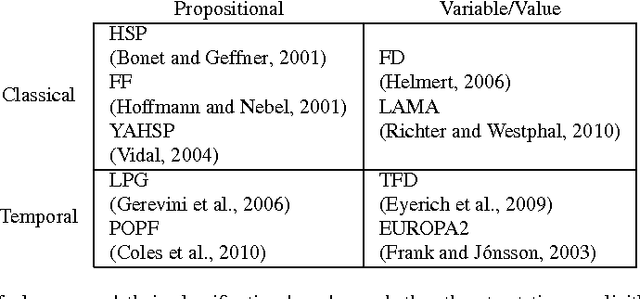
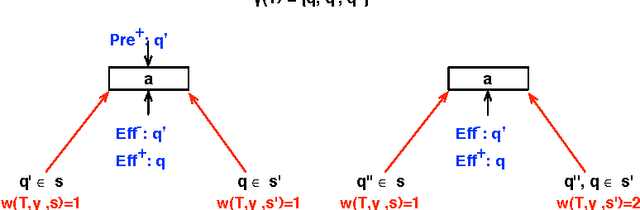
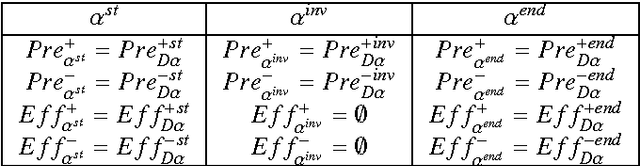
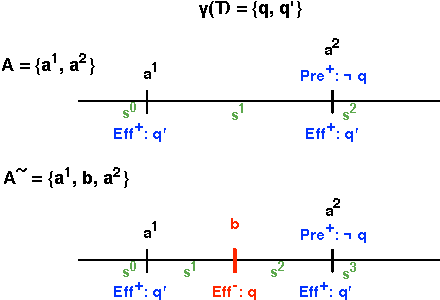
We present a technique for automatically extracting mutual exclusion invariants from temporal planning instances. It first identifies a set of invariant templates by inspecting the lifted representation of the domain and then checks these templates against properties that assure invariance. Our technique builds on other approaches to invariant synthesis presented in the literature, but departs from their limited focus on instantaneous actions by addressing temporal domains. To deal with time, we formulate invariance conditions that account for the entire structure of the actions and the possible concurrent interactions between them. As a result, we construct a significantly more comprehensive technique than previous methods, which is able to find not only invariants for temporal domains, but also a broader set of invariants for non-temporal domains. The experimental results reported in this paper provide evidence that identifying a broader set of invariants results in the generation of fewer multi-valued state variables with larger domains. We show that, in turn, this reduction in the number of variables reflects positively on the performance of a number of temporal planners that use a variable/value representation by significantly reducing their running time.