 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Sim2Real Adaptation Across Environments
Feb 08, 2023Simulation based learning often provides a cost-efficient recourse to reinforcement learning applications in robotics. However, simulators are generally incapable of accurately replicating real-world dynamics, and thus bridging the sim2real gap is an important problem in simulation based learning. Current solutions to bridge the sim2real gap involve hybrid simulators that are augmented with neural residual models. Unfortunately, they require a separate residual model for each individual environment configuration (i.e., a fixed setting of environment variables such as mass, friction etc.), and thus are not transferable to new environments quickly. To address this issue, we propose a Reverse Action Transformation (RAT) policy which learns to imitate simulated policies in the real-world. Once learnt from a single environment, RAT can then be deployed on top of a Universal Policy Network to achieve zero-shot adaptation to new environments. We empirically evaluate our approach in a set of continuous control tasks and observe its advantage as a few-shot and zero-shot learner over competing baselines.
Gradient Descent in Neural Networks as Sequential Learning in RKBS
Feb 01, 2023The study of Neural Tangent Kernels (NTKs) has provided much needed insight into convergence and generalization properties of neural networks in the over-parametrized (wide) limit by approximating the network using a first-order Taylor expansion with respect to its weights in the neighborhood of their initialization values. This allows neural network training to be analyzed from the perspective of reproducing kernel Hilbert spaces (RKHS), which is informative in the over-parametrized regime, but a poor approximation for narrower networks as the weights change more during training. Our goal is to extend beyond the limits of NTK toward a more general theory. We construct an exact power-series representation of the neural network in a finite neighborhood of the initial weights as an inner product of two feature maps, respectively from data and weight-step space, to feature space, allowing neural network training to be analyzed from the perspective of reproducing kernel {\em Banach} space (RKBS). We prove that, regardless of width, the training sequence produced by gradient descent can be exactly replicated by regularized sequential learning in RKBS. Using this, we present novel bound on uniform convergence where the iterations count and learning rate play a central role, giving new theoretical insight into neural network training.
Momentum Adversarial Distillation: Handling Large Distribution Shifts in Data-Free Knowledge Distillation
Sep 21, 2022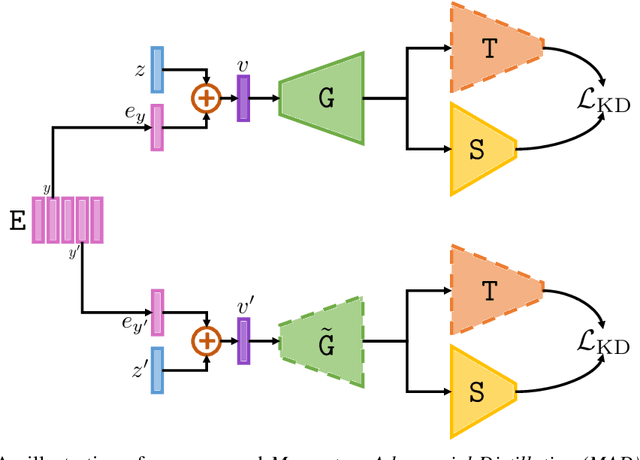


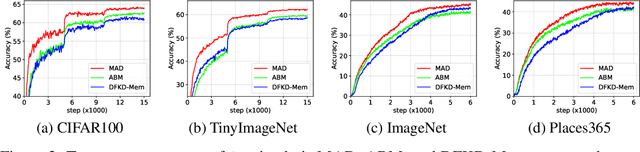
Data-free Knowledge Distillation (DFKD) has attracted attention recently thanks to its appealing capability of transferring knowledge from a teacher network to a student network without using training data. The main idea is to use a generator to synthesize data for training the student. As the generator gets updated, the distribution of synthetic data will change. Such distribution shift could be large if the generator and the student are trained adversarially, causing the student to forget the knowledge it acquired at previous steps. To alleviate this problem, we propose a simple yet effective method called Momentum Adversarial Distillation (MAD) which maintains an exponential moving average (EMA) copy of the generator and uses synthetic samples from both the generator and the EMA generator to train the student. Since the EMA generator can be considered as an ensemble of the generator's old versions and often undergoes a smaller change in updates compared to the generator, training on its synthetic samples can help the student recall the past knowledge and prevent the student from adapting too quickly to new updates of the generator. Our experiments on six benchmark datasets including big datasets like ImageNet and Places365 demonstrate the superior performance of MAD over competing methods for handling the large distribution shift problem. Our method also compares favorably to existing DFKD methods and even achieves state-of-the-art results in some cases.
Defense Against Multi-target Trojan Attacks
Jul 08, 2022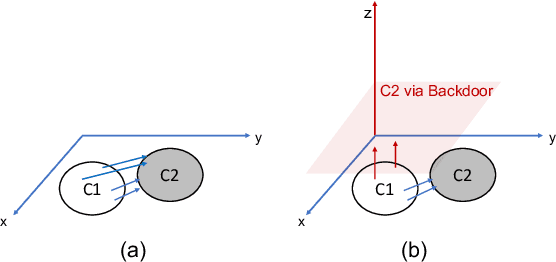
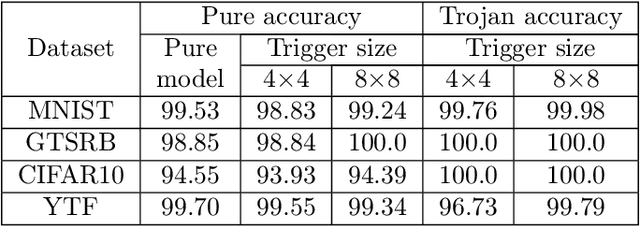
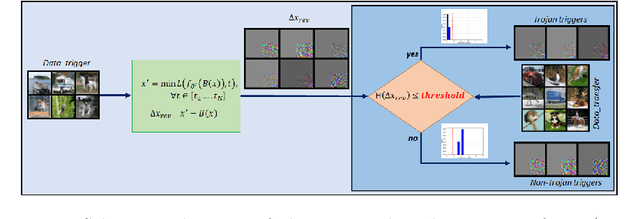

Adversarial attacks on deep learning-based models pose a significant threat to the current AI infrastructure. Among them, Trojan attacks are the hardest to defend against. In this paper, we first introduce a variation of the Badnet kind of attacks that introduces Trojan backdoors to multiple target classes and allows triggers to be placed anywhere in the image. The former makes it more potent and the latter makes it extremely easy to carry out the attack in the physical space. The state-of-the-art Trojan detection methods fail with this threat model. To defend against this attack, we first introduce a trigger reverse-engineering mechanism that uses multiple images to recover a variety of potential triggers. We then propose a detection mechanism by measuring the transferability of such recovered triggers. A Trojan trigger will have very high transferability i.e. they make other images also go to the same class. We study many practical advantages of our attack method and then demonstrate the detection performance using a variety of image datasets. The experimental results show the superior detection performance of our method over the state-of-the-arts.
Fast Conditional Network Compression Using Bayesian HyperNetworks
May 13, 2022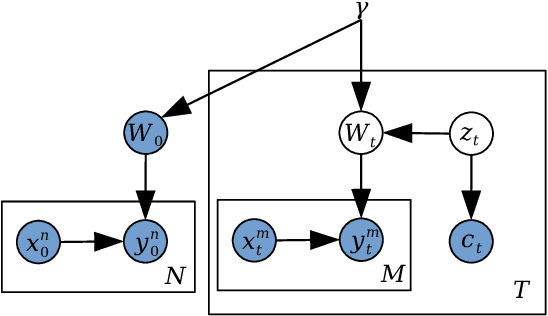
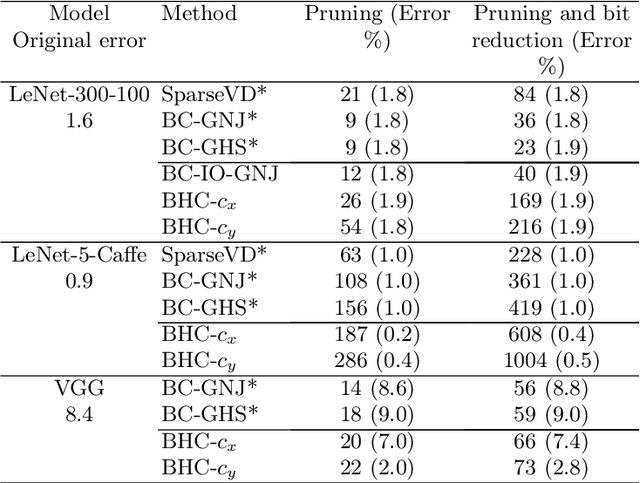
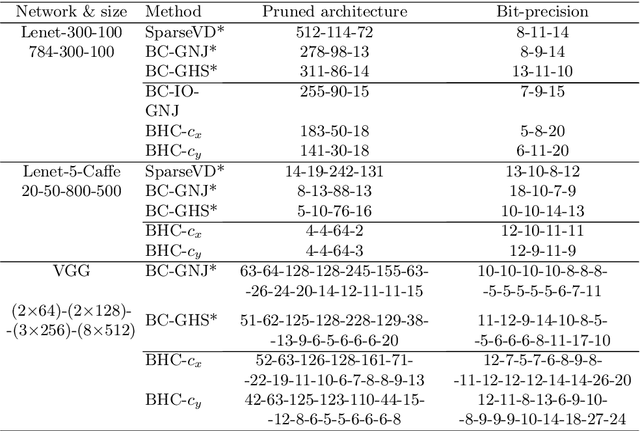
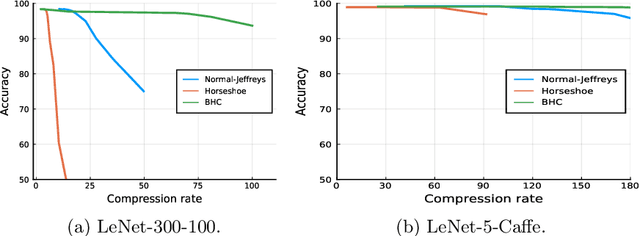
We introduce a conditional compression problem and propose a fast framework for tackling it. The problem is how to quickly compress a pretrained large neural network into optimal smaller networks given target contexts, e.g. a context involving only a subset of classes or a context where only limited compute resource is available. To solve this, we propose an efficient Bayesian framework to compress a given large network into much smaller size tailored to meet each contextual requirement. We employ a hypernetwork to parameterize the posterior distribution of weights given conditional inputs and minimize a variational objective of this Bayesian neural network. To further reduce the network sizes, we propose a new input-output group sparsity factorization of weights to encourage more sparseness in the generated weights. Our methods can quickly generate compressed networks with significantly smaller sizes than baseline methods.
Regret Bounds for Expected Improvement Algorithms in Gaussian Process Bandit Optimization
Mar 15, 2022

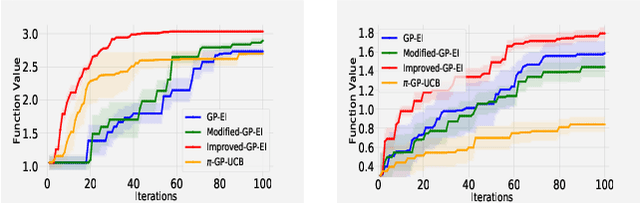
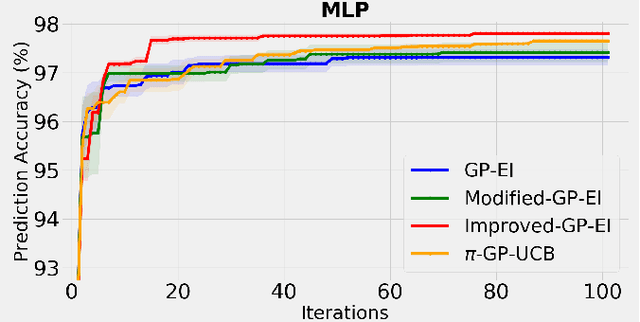
The expected improvement (EI) algorithm is one of the most popular strategies for optimization under uncertainty due to its simplicity and efficiency. Despite its popularity, the theoretical aspects of this algorithm have not been properly analyzed. In particular, whether in the noisy setting, the EI strategy with a standard incumbent converges is still an open question of the Gaussian process bandit optimization problem. We aim to answer this question by proposing a variant of EI with a standard incumbent defined via the GP predictive mean. We prove that our algorithm converges, and achieves a cumulative regret bound of $\mathcal O(\gamma_T\sqrt{T})$, where $\gamma_T$ is the maximum information gain between $T$ observations and the Gaussian process model. Based on this variant of EI, we further propose an algorithm called Improved GP-EI that converges faster than previous counterparts. In particular, our proposed variants of EI do not require the knowledge of the RKHS norm and the noise's sub-Gaussianity parameter as in previous works. Empirical validation in our paper demonstrates the effectiveness of our algorithms compared to several baselines.
Towards Effective and Robust Neural Trojan Defenses via Input Filtering
Mar 08, 2022


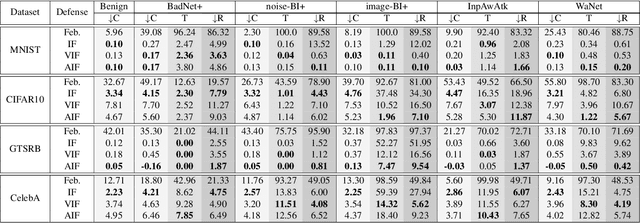
Trojan attacks on deep neural networks are both dangerous and surreptitious. Over the past few years, Trojan attacks have advanced from using only a single input-agnostic trigger and targeting only one class to using multiple, input-specific triggers and targeting multiple classes. However, Trojan defenses have not caught up with this development. Most defense methods still make out-of-date assumptions about Trojan triggers and target classes, thus, can be easily circumvented by modern Trojan attacks. To deal with this problem, we propose two novel "filtering" defenses called Variational Input Filtering (VIF) and Adversarial Input Filtering (AIF) which leverage lossy data compression and adversarial learning respectively to effectively purify all potential Trojan triggers in the input at run time without making assumptions about the number of triggers/target classes or the input dependence property of triggers. In addition, we introduce a new defense mechanism called "Filtering-then-Contrasting" (FtC) which helps avoid the drop in classification accuracy on clean data caused by "filtering", and combine it with VIF/AIF to derive new defenses of this kind. Extensive experimental results and ablation studies show that our proposed defenses significantly outperform well-known baseline defenses in mitigating five advanced Trojan attacks including two recent state-of-the-art while being quite robust to small amounts of training data and large-norm triggers.
Uncertainty Aware System Identification with Universal Policies
Feb 11, 2022Sim2real transfer is primarily concerned with transferring policies trained in simulation to potentially noisy real world environments. A common problem associated with sim2real transfer is estimating the real-world environmental parameters to ground the simulated environment to. Although existing methods such as Domain Randomisation (DR) can produce robust policies by sampling from a distribution of parameters during training, there is no established method for identifying the parameters of the corresponding distribution for a given real-world setting. In this work, we propose Uncertainty-aware policy search (UncAPS), where we use Universal Policy Network (UPN) to store simulation-trained task-specific policies across the full range of environmental parameters and then subsequently employ robust Bayesian optimisation to craft robust policies for the given environment by combining relevant UPN policies in a DR like fashion. Such policy-driven grounding is expected to be more efficient as it estimates only task-relevant sets of parameters. Further, we also account for the estimation uncertainties in the search process to produce policies that are robust against both aleatoric and epistemic uncertainties. We empirically evaluate our approach in a range of noisy, continuous control environments, and show its improved performance compared to competing baselines.
Fast Model-based Policy Search for Universal Policy Networks
Feb 11, 2022Adapting an agent's behaviour to new environments has been one of the primary focus areas of physics based reinforcement learning. Although recent approaches such as universal policy networks partially address this issue by enabling the storage of multiple policies trained in simulation on a wide range of dynamic/latent factors, efficiently identifying the most appropriate policy for a given environment remains a challenge. In this work, we propose a Gaussian Process-based prior learned in simulation, that captures the likely performance of a policy when transferred to a previously unseen environment. We integrate this prior with a Bayesian Optimisation-based policy search process to improve the efficiency of identifying the most appropriate policy from the universal policy network. We empirically evaluate our approach in a range of continuous and discrete control environments, and show that it outperforms other competing baselines.
Balanced Q-learning: Combining the Influence of Optimistic and Pessimistic Targets
Nov 03, 2021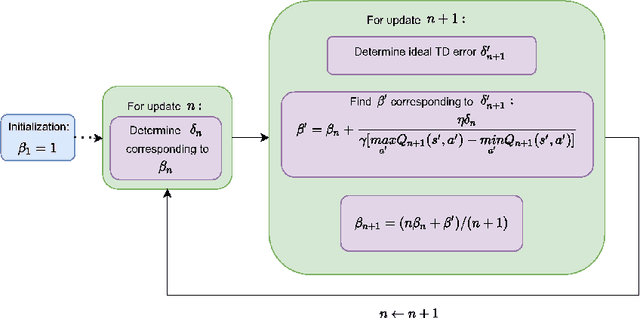
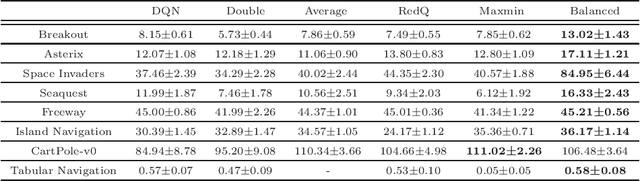
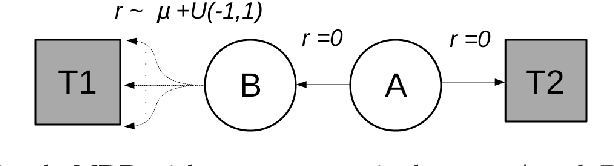
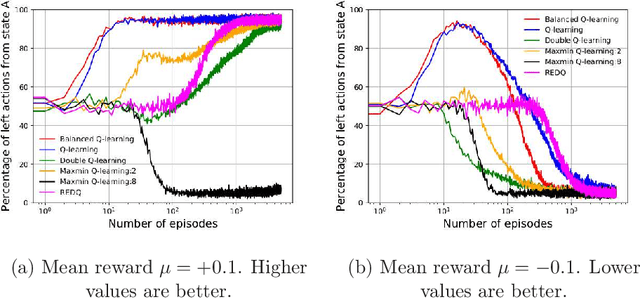
The optimistic nature of the Q-learning target leads to an overestimation bias, which is an inherent problem associated with standard $Q-$learning. Such a bias fails to account for the possibility of low returns, particularly in risky scenarios. However, the existence of biases, whether overestimation or underestimation, need not necessarily be undesirable. In this paper, we analytically examine the utility of biased learning, and show that specific types of biases may be preferable, depending on the scenario. Based on this finding, we design a novel reinforcement learning algorithm, Balanced Q-learning, in which the target is modified to be a convex combination of a pessimistic and an optimistic term, whose associated weights are determined online, analytically. We prove the convergence of this algorithm in a tabular setting, and empirically demonstrate its superior learning performance in various environments.