 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpmixing via style transfer: a variational autoencoder for disentangling spatial images and musical content
Mar 22, 2022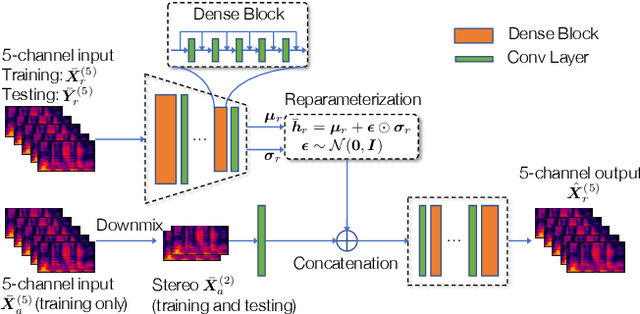

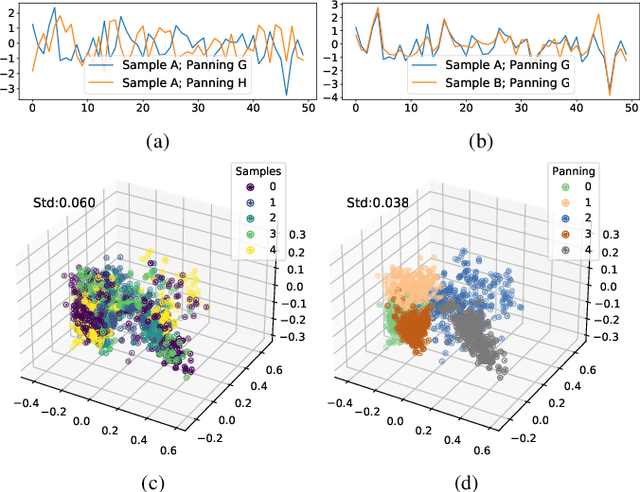
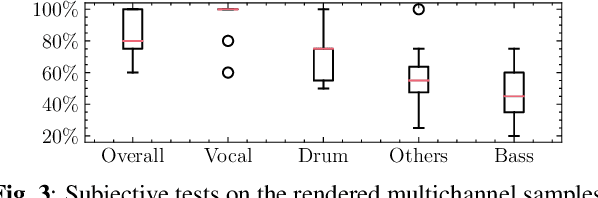
In the stereo-to-multichannel upmixing problem for music, one of the main tasks is to set the directionality of the instrument sources in the multichannel rendering results. In this paper, we propose a modified variational autoencoder model that learns a latent space to describe the spatial images in multichannel music. We seek to disentangle the spatial images and music content, so the learned latent variables are invariant to the music. At test time, we use the latent variables to control the panning of sources. We propose two upmixing use cases: transferring the spatial images from one song to another and blind panning based on the generative model. We report objective and subjective evaluation results to empirically show that our model captures spatial images separately from music content and achieves transfer-based interactive panning.
Dereverberation using joint estimation of dry speech signal and acoustic system
Jul 24, 2020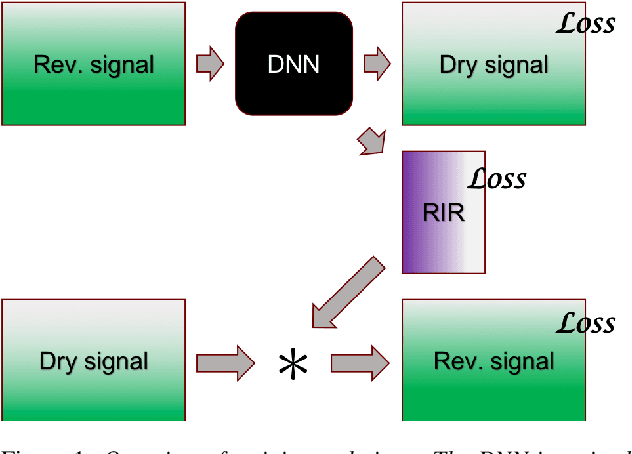
The purpose of speech dereverberation is to remove quality-degrading effects of a time-invariant impulse response filter from the signal. In this report, we describe an approach to speech dereverberation that involves joint estimation of the dry speech signal and of the room impulse response. We explore deep learning models that apply to each task separately, and how these can be combined in a joint model with shared parameters.
Deep Autotuner: a Pitch Correcting Network for Singing Performances
Feb 12, 2020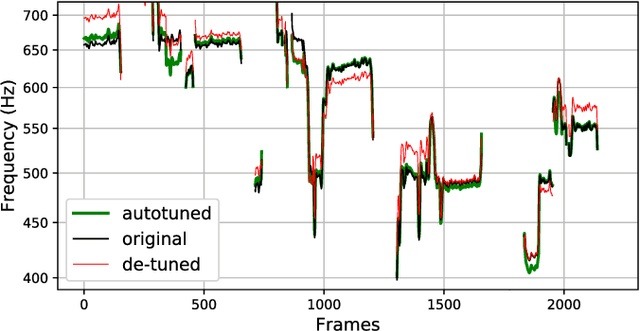
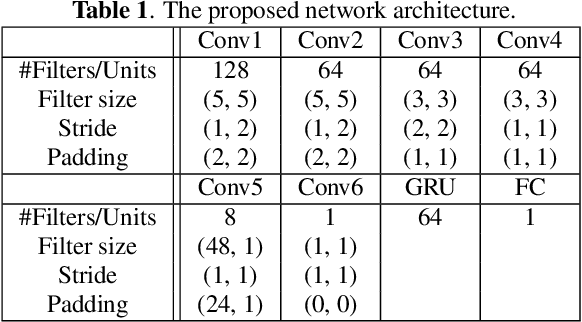
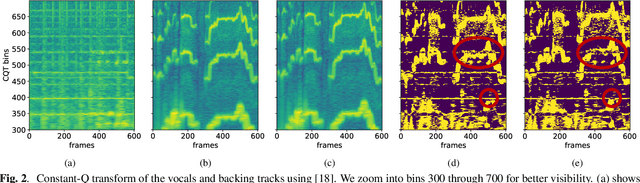
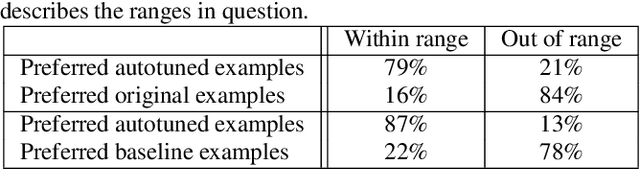
We introduce a data-driven approach to automatic pitch correction of solo singing performances. The proposed approach predicts note-wise pitch shifts from the relationship between the respective spectrograms of the singing and accompaniment. This approach differs from commercial systems, where vocal track notes are usually shifted to be centered around pitches in a user-defined score, or mapped to the closest pitch among the twelve equal-tempered scale degrees. The proposed system treats pitch as a continuous value rather than relying on a set of discretized notes found in musical scores, thus allowing for improvisation and harmonization in the singing performance. We train our neural network model using a dataset of 4,702 amateur karaoke performances selected for good intonation. Our model is trained on both incorrect intonation, for which it learns a correction, and intentional pitch variation, which it learns to preserve. The proposed deep neural network with gated recurrent units on top of convolutional layers shows promising performance on the real-world score-free singing pitch correction task of autotuning.
Fully Learnable Front-End for Multi-Channel Acoustic Modeling using Semi-Supervised Learning
Feb 01, 2020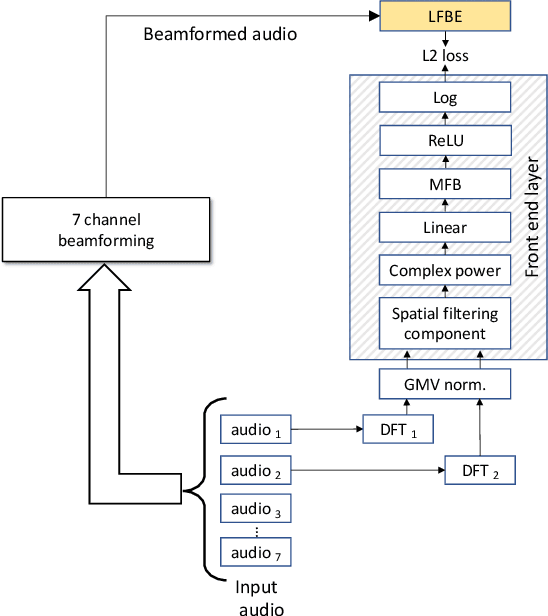
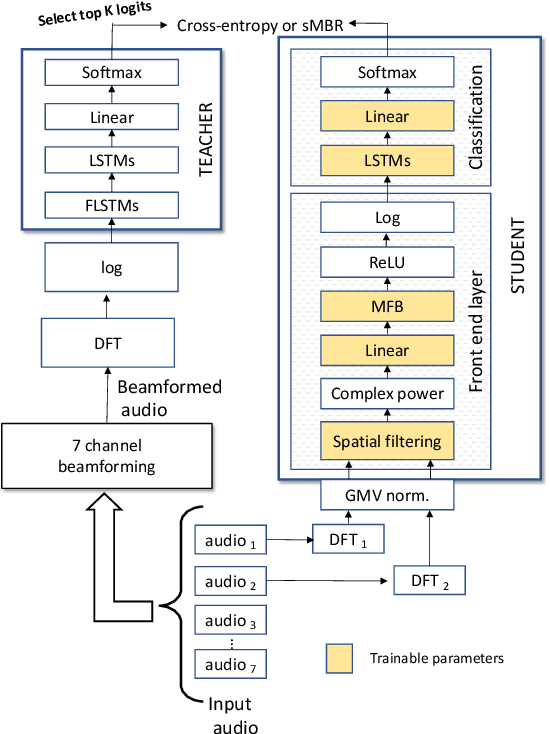

In this work, we investigated the teacher-student training paradigm to train a fully learnable multi-channel acoustic model for far-field automatic speech recognition (ASR). Using a large offline teacher model trained on beamformed audio, we trained a simpler multi-channel student acoustic model used in the speech recognition system. For the student, both multi-channel feature extraction layers and the higher classification layers were jointly trained using the logits from the teacher model. In our experiments, compared to a baseline model trained on about 600 hours of transcribed data, a relative word-error rate (WER) reduction of about 27.3% was achieved when using an additional 1800 hours of untranscribed data. We also investigated the benefit of pre-training the multi-channel front end to output the beamformed log-mel filter bank energies (LFBE) using L2 loss. We find that pre-training improves the word error rate by 10.7% when compared to a multi-channel model directly initialized with a beamformer and mel-filter bank coefficients for the front end. Finally, combining pre-training and teacher-student training produces a WER reduction of 31% compared to our baseline.
Deep Autotuner: A Data-Driven Approach to Natural-Sounding Pitch Correction for Singing Voice in Karaoke Performances
Feb 03, 2019
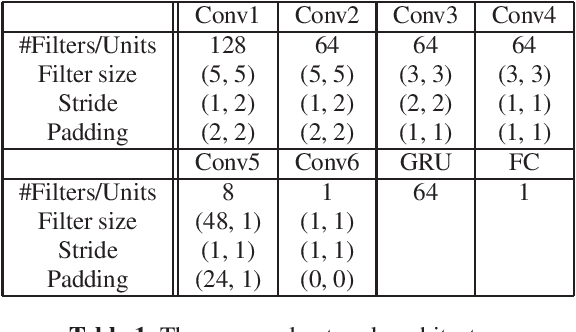
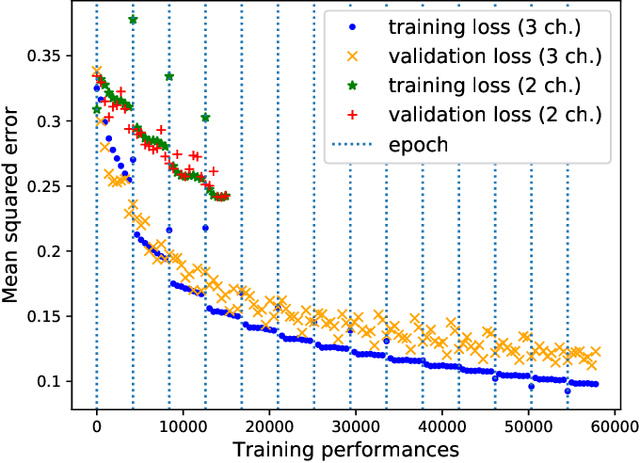
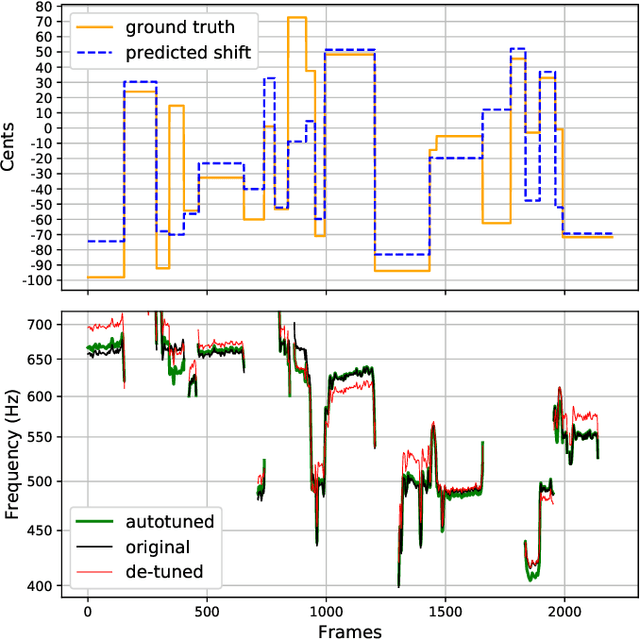
We describe a machine-learning approach to pitch correcting a solo singing performance in a karaoke setting, where the solo voice and accompaniment are on separate tracks. The proposed approach addresses the situation where no musical score of the vocals nor the accompaniment exists: It predicts the amount of correction from the relationship between the spectral contents of the vocal and accompaniment tracks. Hence, the pitch shift in cents suggested by the model can be used to make the voice sound in tune with the accompaniment. This approach differs from commercially used automatic pitch correction systems, where notes in the vocal tracks are shifted to be centered around notes in a user-defined score or mapped to the closest pitch among the twelve equal-tempered scale degrees. We train the model using a dataset of 4,702 amateur karaoke performances selected for good intonation. We present a Convolutional Gated Recurrent Unit (CGRU) model to accomplish this task. This method can be extended into unsupervised pitch correction of a vocal performance, popularly referred to as autotuning.