 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared Representation for 3D Pose Estimation, Action Classification, and Progress Prediction from Tactile Signals
Mar 26, 2026Estimating human pose, classifying actions, and predicting movement progress are essential for human-robot interaction. While vision-based methods suffer from occlusion and privacy concerns in realistic environments, tactile sensing avoids these issues. However, prior tactile-based approaches handle each task separately, leading to suboptimal performance. In this study, we propose a Shared COnvolutional Transformer for Tactile Inference (SCOTTI) that learns a shared representation to simultaneously address three separate prediction tasks: 3D human pose estimation, action class categorization, and action completion progress estimation. To the best of our knowledge, this is the first work to explore action progress prediction using foot tactile signals from custom wireless insole sensors. This unified approach leverages the mutual benefits of multi-task learning, enabling the model to achieve improved performance across all three tasks compared to learning them independently. Experimental results demonstrate that SCOTTI outperforms existing approaches across all three tasks. Additionally, we introduce a novel dataset collected from 15 participants performing various activities and exercises, with 7 hours of total duration, across eight different activities.
The PokeAgent Challenge: Competitive and Long-Context Learning at Scale
Mar 17, 2026We present the PokeAgent Challenge, a large-scale benchmark for decision-making research built on Pokemon's multi-agent battle system and expansive role-playing game (RPG) environment. Partial observability, game-theoretic reasoning, and long-horizon planning remain open problems for frontier AI, yet few benchmarks stress all three simultaneously under realistic conditions. PokeAgent targets these limitations at scale through two complementary tracks: our Battling Track, which calls for strategic reasoning and generalization under partial observability in competitive Pokemon battles, and our Speedrunning Track, which requires long-horizon planning and sequential decision-making in the Pokemon RPG. Our Battling Track supplies a dataset of 20M+ battle trajectories alongside a suite of heuristic, RL, and LLM-based baselines capable of high-level competitive play. Our Speedrunning Track provides the first standardized evaluation framework for RPG speedrunning, including an open-source multi-agent orchestration system for modular, reproducible comparisons of harness-based LLM approaches. Our NeurIPS 2025 competition validates both the quality of our resources and the research community's interest in Pokemon, with over 100 teams competing across both tracks and winning solutions detailed in our paper. Participant submissions and our baselines reveal considerable gaps between generalist (LLM), specialist (RL), and elite human performance. Analysis against the BenchPress evaluation matrix shows that Pokemon battling is nearly orthogonal to standard LLM benchmarks, measuring capabilities not captured by existing suites and positioning Pokemon as an unsolved benchmark that can drive RL and LLM research forward. We transition to a living benchmark with a live leaderboard for Battling and self-contained evaluation for Speedrunning at https://pokeagentchallenge.com.
FIRE: Frobenius-Isometry Reinitialization for Balancing the Stability-Plasticity Tradeoff
Feb 08, 2026Deep neural networks trained on nonstationary data must balance stability (i.e., retaining prior knowledge) and plasticity (i.e., adapting to new tasks). Standard reinitialization methods, which reinitialize weights toward their original values, are widely used but difficult to tune: conservative reinitializations fail to restore plasticity, while aggressive ones erase useful knowledge. We propose FIRE, a principled reinitialization method that explicitly balances the stability-plasticity tradeoff. FIRE quantifies stability through Squared Frobenius Error (SFE), measuring proximity to past weights, and plasticity through Deviation from Isometry (DfI), reflecting weight isotropy. The reinitialization point is obtained by solving a constrained optimization problem, minimizing SFE subject to DfI being zero, which is efficiently approximated by Newton-Schulz iteration. FIRE is evaluated on continual visual learning (CIFAR-10 with ResNet-18), language modeling (OpenWebText with GPT-0.1B), and reinforcement learning (HumanoidBench with SAC and Atari games with DQN). Across all domains, FIRE consistently outperforms both naive training without intervention and standard reinitialization methods, demonstrating effective balancing of the stability-plasticity tradeoff.
Activation by Interval-wise Dropout: A Simple Way to Prevent Neural Networks from Plasticity Loss
Feb 03, 2025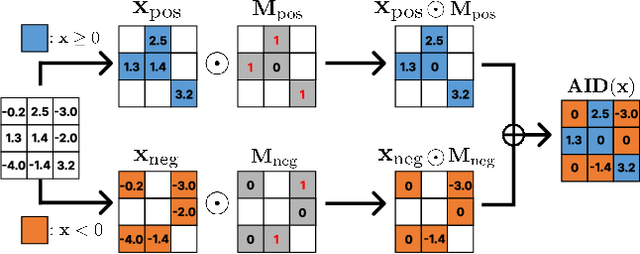



Plasticity loss, a critical challenge in neural network training, limits a model's ability to adapt to new tasks or shifts in data distribution. This paper introduces AID (Activation by Interval-wise Dropout), a novel method inspired by Dropout, designed to address plasticity loss. Unlike Dropout, AID generates subnetworks by applying Dropout with different probabilities on each preactivation interval. Theoretical analysis reveals that AID regularizes the network, promoting behavior analogous to that of deep linear networks, which do not suffer from plasticity loss. We validate the effectiveness of AID in maintaining plasticity across various benchmarks, including continual learning tasks on standard image classification datasets such as CIFAR10, CIFAR100, and TinyImageNet. Furthermore, we show that AID enhances reinforcement learning performance in the Arcade Learning Environment benchmark.