 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonalized electric vehicle energy consumption estimation framework that integrates driver behavior with map data
Apr 22, 2026This paper presents a personalized Battery Electric Vehicle (BEV) energy consumption estimation framework that integrates map-based contextual features with driver-specific velocity prediction and physics-based energy consumption modeling. The system combines route selection, detailed road feature processing, a rule-based reference velocity generator, a PID controller-based vehicle dynamics simulator, and a Bidirectional LSTM model trained to reproduce individual driving behavior. The predicted individual-specific velocity profiles are coupled with a quasi-steady backward energy consumption model to compute tractive power, regenerative braking, and State-of-Charge (SOC) evolution. Evaluation across urban, freeway, and hilly routes demonstrates that the proposed approach captures key driver behavioral patterns such as deceleration at intersections, speed-limit tracking, and road grade-dependent responses, while producing accurate power and SOC trajectories. The results highlight the effectiveness of combining learned driver behavior with map-based context and physics-based energy consumption modeling to produce accurate, personalized BEV SOC depletion profiles.
GPU-Accelerated Optimization of Transformer-Based Neural Networks for Real-Time Inference
Mar 30, 2026This paper presents the design and evaluation of a GPU-accelerated inference pipeline for transformer models using NVIDIA TensorRT with mixed-precision optimization. We evaluate BERT-base (110M parameters) and GPT-2 (124M parameters) across batch sizes from 1 to 32 and sequence lengths from 32 to 512. The system achieves up to 64.4x speedup over CPU baselines, sub-10 ms latency for single-sample inference, and a 63 percent reduction in memory usage. We introduce a hybrid precision strategy that preserves FP32 for numerically sensitive operations such as softmax and layer normalization, while applying FP16 to linear layers. This approach maintains high numerical fidelity (cosine similarity >= 0.9998 relative to baseline outputs) and eliminates NaN instability. The pipeline is implemented as a modular, containerized system that enables reproducible benchmarking across more than 360 configurations. Cross-GPU validation on an NVIDIA A100 shows consistent FP16 speedup ratios between 1.84x and 2.00x, along with stable numerical behavior. Downstream evaluation on SST-2 demonstrates no accuracy degradation under hybrid precision. Validation on WikiText-2 shows that random inputs underestimate NaN instability by up to 6x for full FP16, while confirming the robustness of the hybrid approach (0.0 percent NaN, cosine similarity >= 0.9998). These results provide a detailed characterization of performance and accuracy trade-offs across GPU architectures and offer practical guidance for deploying transformer models in latency-critical environments.
Face Recognition System
Jan 08, 2019



Deep learning is one of the new and important branches in machine learning. Deep learning refers to a set of algorithms that solve various problems such as images and texts by using various machine learning algorithms in multi-layer neural networks. Deep learning can be classified as a neural network from the general category, but there are many changes in the concrete realization. At the core of deep learning is feature learning, which is designed to obtain hierarchical information through hierarchical networks, so as to solve the important problems that previously required artificial design features. Deep Learning is a framework that contains several important algorithms. For different applications (images, voice, text), you need to use different network models to achieve better results. With the development of deep learning and the introduction of deep convolutional neural networks, the accuracy and speed of face recognition have made great strides. However, as we said above, the results from different networks and models are very different. In this paper, facial features are extracted by merging and comparing multiple models, and then a deep neural network is constructed to train and construct the combined features. In this way, the advantages of multiple models can be combined to mention the recognition accuracy. After getting a model with high accuracy, we build a product model. This article compares the pure-client model with the server-client model, analyzes the pros and cons of the two models, and analyzes the various commercial products that are required for the server-client model.
Implementation of Robust Face Recognition System Using Live Video Feed Based on CNN
Nov 18, 2018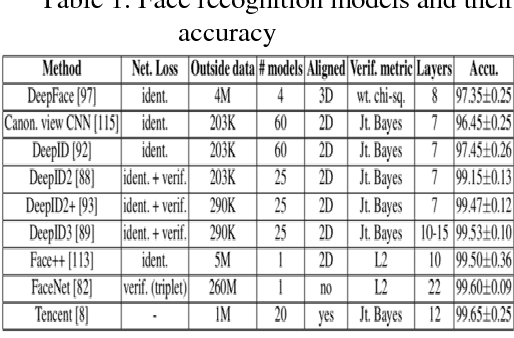
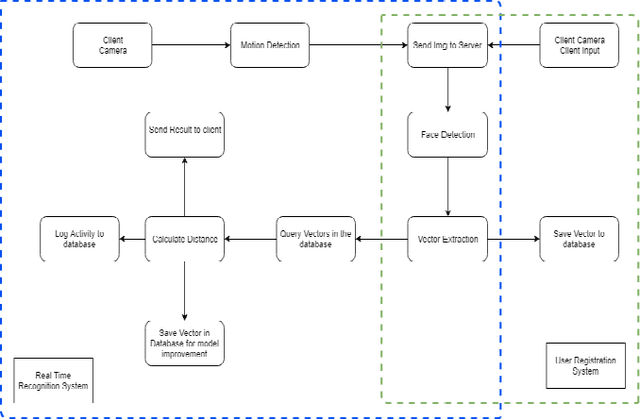

The way to accurately and effectively identify people has always been an interesting topic in research and industry. With the rapid development of artificial intelligence in recent years, facial recognition gains lots of attention due to prompting the development of emerging identification methods. Compared to traditional card recognition, fingerprint recognition and iris recognition, face recognition has many advantages including non-contact interface, high concurrency, and user-friendly usage. It has high potential to be used in government, public facilities, security, e-commerce, retailing, education and many other fields. With the development of deep learning and the introduction of deep convolutional neural networks, the accuracy and speed of face recognition have made great strides. However, the results from different networks and models are very different with different system architecture. Furthermore, it could take significant amount of data storage space and data processing time for the face recognition system with video feed, if the system stores images and features of human faces. In this paper, facial features are extracted by merging and comparing multiple models, and then a deep neural network is constructed to train and construct the combined features. In this way, the advantages of multiple models can be combined to mention the recognition accuracy. After getting a model with high accuracy, we build a product model. The model will take a human face image and extract it into a vector. Then the distance between vectors are compared to determine if two faces on different picture belongs to the same person. The proposed approach reduces data storage space and data processing time for the face recognition system with video feed scientifically with our proposed system architecture.