 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELMoE-3D: Leveraging Intrinsic Elasticity of MoE for Hybrid-Bonding-Enabled Self-Speculative Decoding in On-Premises Serving
Apr 16, 2026Mixture-of-Experts (MoE) models have become the dominant architecture for large-scale language models, yet on-premises serving remains fundamentally memory-bound as batching turns sparse per-token compute into dense memory activation. Memory-centric architectures (PIM, NMP) improve bandwidth but leave compute underutilized under MoE's low arithmetic intensity at high batch sizes. Speculative decoding (SD) trades idle compute for fewer target invocations, yet verification must load experts even for rejected tokens, severely limiting its benefit in MoE especially at low batch sizes. We propose ELMoE-3D, a hybrid-bonding (HB)-based HW-SW co-designed framework that unifies cache-based acceleration and speculative decoding to offer overall speedup across batch sizes. We identify two intrinsic elasticity axes of MoE-expert and bit-and jointly scale them to construct Elastic Self-Speculative Decoding (Elastic-SD), which serves as both an expert cache and a strongly aligned self-draft model accelerated by high HB bandwidth. Our LSB-augmented bit-sliced architecture exploits inherent redundancy in bit-slice representations to natively support bit-nested execution. On our 3D-stacked hardware, ELMoE-3D achieves an average $6.6\times$ speedup and $4.4\times$ energy efficiency gain over naive MoE serving on xPU across batch sizes 1-16, and delivers $2.2\times$ speedup and $1.4\times$ energy efficiency gain over the best-performing prior accelerator baseline.
A.X K1 Technical Report
Jan 15, 2026We introduce A.X K1, a 519B-parameter Mixture-of-Experts (MoE) language model trained from scratch. Our design leverages scaling laws to optimize training configurations and vocabulary size under fixed computational budgets. A.X K1 is pre-trained on a corpus of approximately 10T tokens, curated by a multi-stage data processing pipeline. Designed to bridge the gap between reasoning capability and inference efficiency, A.X K1 supports explicitly controllable reasoning to facilitate scalable deployment across diverse real-world scenarios. We propose a simple yet effective Think-Fusion training recipe, enabling user-controlled switching between thinking and non-thinking modes within a single unified model. Extensive evaluations demonstrate that A.X K1 achieves performance competitive with leading open-source models, while establishing a distinctive advantage in Korean-language benchmarks.
SeVeDo: A Heterogeneous Transformer Accelerator for Low-Bit Inference via Hierarchical Group Quantization and SVD-Guided Mixed Precision
Dec 15, 2025Low-bit quantization is a promising technique for efficient transformer inference by reducing computational and memory overhead. However, aggressive bitwidth reduction remains challenging due to activation outliers, leading to accuracy degradation. Existing methods, such as outlier-handling and group quantization, achieve high accuracy but incur substantial energy consumption. To address this, we propose SeVeDo, an energy-efficient SVD-based heterogeneous accelerator that structurally separates outlier-sensitive components into a high-precision low-rank path, while the remaining computations are executed in a low-bit residual datapath with group quantization. To further enhance efficiency, Hierarchical Group Quantization (HGQ) combines coarse-grained floating-point scaling with fine-grained shifting, effectively reducing dequantization cost. Also, SVD-guided mixed precision (SVD-MP) statically allocates higher bitwidths to precision-sensitive components identified through low-rank decomposition, thereby minimizing floating-point operation cost. Experimental results show that SeVeDo achieves a peak energy efficiency of 13.8TOPS/W, surpassing conventional designs, with 12.7TOPS/W on ViT-Base and 13.4TOPS/W on Llama2-7B benchmarks.
Encoding Speaker-Specific Latent Speech Feature for Speech Synthesis
Nov 20, 2023



In this work, we propose a novel method for modeling numerous speakers, which enables expressing the overall characteristics of speakers in detail like a trained multi-speaker model without additional training on the target speaker's dataset. Although various works with similar purposes have been actively studied, their performance has not yet reached that of trained multi-speaker models due to their fundamental limitations. To overcome previous limitations, we propose effective methods for feature learning and representing target speakers' speech characteristics by discretizing the features and conditioning them to a speech synthesis model. Our method obtained a significantly higher similarity mean opinion score (SMOS) in subjective similarity evaluation than seen speakers of a best-performing multi-speaker model, even with unseen speakers. The proposed method also outperforms a zero-shot method by significant margins. Furthermore, our method shows remarkable performance in generating new artificial speakers. In addition, we demonstrate that the encoded latent features are sufficiently informative to reconstruct an original speaker's speech completely. It implies that our method can be used as a general methodology to encode and reconstruct speakers' characteristics in various tasks.
VITS2: Improving Quality and Efficiency of Single-Stage Text-to-Speech with Adversarial Learning and Architecture Design
Jul 31, 2023



Single-stage text-to-speech models have been actively studied recently, and their results have outperformed two-stage pipeline systems. Although the previous single-stage model has made great progress, there is room for improvement in terms of its intermittent unnaturalness, computational efficiency, and strong dependence on phoneme conversion. In this work, we introduce VITS2, a single-stage text-to-speech model that efficiently synthesizes a more natural speech by improving several aspects of the previous work. We propose improved structures and training mechanisms and present that the proposed methods are effective in improving naturalness, similarity of speech characteristics in a multi-speaker model, and efficiency of training and inference. Furthermore, we demonstrate that the strong dependence on phoneme conversion in previous works can be significantly reduced with our method, which allows a fully end-to-end single-stage approach.
GST: Group-Sparse Training for Accelerating Deep Reinforcement Learning
Jan 24, 2021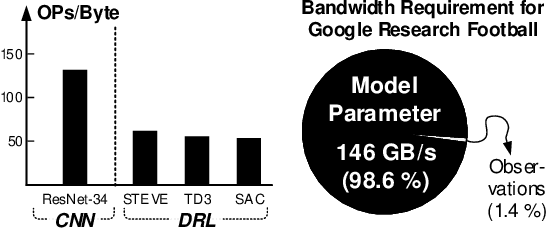
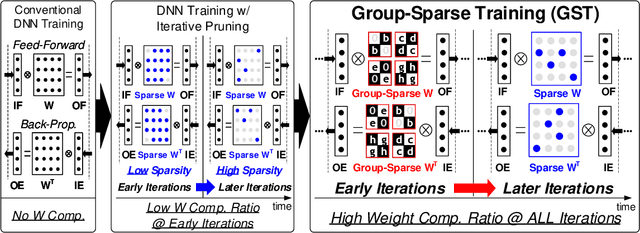
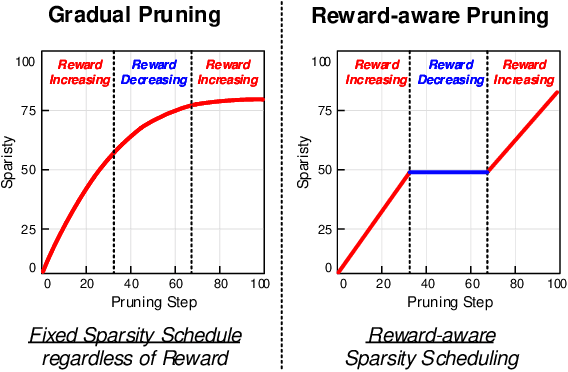
Deep reinforcement learning (DRL) has shown remarkable success in sequential decision-making problems but suffers from a long training time to obtain such good performance. Many parallel and distributed DRL training approaches have been proposed to solve this problem, but it is difficult to utilize them on resource-limited devices. In order to accelerate DRL in real-world edge devices, memory bandwidth bottlenecks due to large weight transactions have to be resolved. However, previous iterative pruning not only shows a low compression ratio at the beginning of training but also makes DRL training unstable. To overcome these shortcomings, we propose a novel weight compression method for DRL training acceleration, named group-sparse training (GST). GST selectively utilizes block-circulant compression to maintain a high weight compression ratio during all iterations of DRL training and dynamically adapt target sparsity through reward-aware pruning for stable training. Thanks to the features, GST achieves a 25 \%p $\sim$ 41.5 \%p higher average compression ratio than the iterative pruning method without reward drop in Mujoco Halfcheetah-v2 and Mujoco humanoid-v2 environment with TD3 training.