 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffsetBias: Leveraging Debiased Data for Tuning Evaluators
Jul 09, 2024



Employing Large Language Models (LLMs) to assess the quality of generated responses, such as prompting instruct-tuned models or fine-tuning judge models, has become a widely adopted evaluation method. It is also known that such evaluators are vulnerable to biases, such as favoring longer responses. While it is important to overcome this problem, the specifics of these biases remain under-explored. In this work, we qualitatively identify six types of biases inherent in various judge models. We propose EvalBiasBench as a meta-evaluation collection of hand-crafted test cases for each bias type. Additionally, we present de-biasing dataset construction methods and the associated preference dataset OffsetBias. Experimental results demonstrate that fine-tuning on our dataset significantly enhances the robustness of judge models against biases and improves performance across most evaluation scenarios. We release our datasets and the fine-tuned judge model to public.
May the Force Be with Your Copy Mechanism: Enhanced Supervised-Copy Method for Natural Language Generation
Dec 20, 2021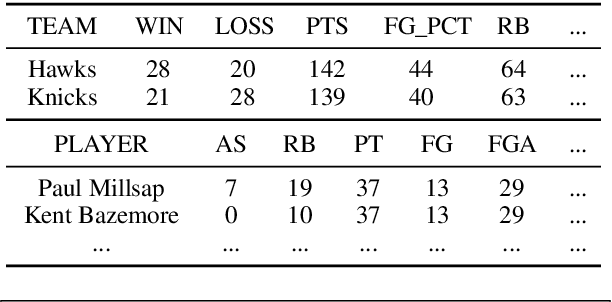
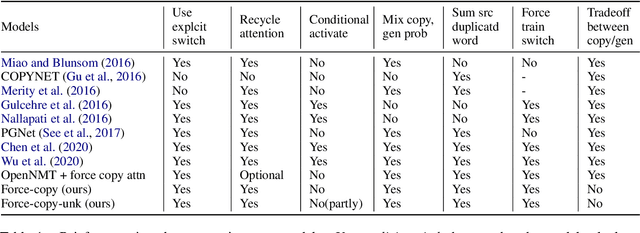
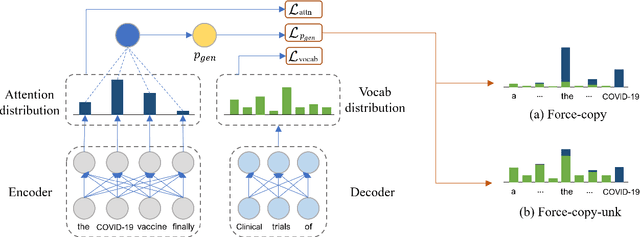
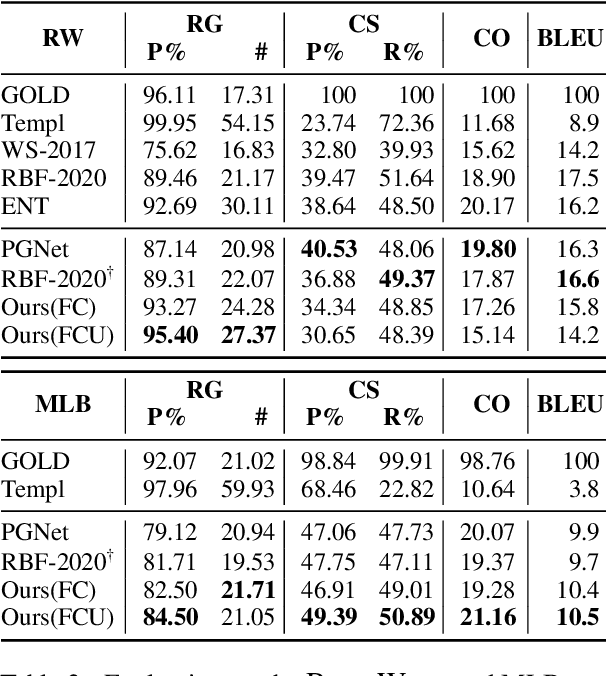
Recent neural sequence-to-sequence models with a copy mechanism have achieved remarkable progress in various text generation tasks. These models addressed out-of-vocabulary problems and facilitated the generation of rare words. However, the identification of the word which needs to be copied is difficult, as observed by prior copy models, which suffer from incorrect generation and lacking abstractness. In this paper, we propose a novel supervised approach of a copy network that helps the model decide which words need to be copied and which need to be generated. Specifically, we re-define the objective function, which leverages source sequences and target vocabularies as guidance for copying. The experimental results on data-to-text generation and abstractive summarization tasks verify that our approach enhances the copying quality and improves the degree of abstractness.
A Syllable-based Technique for Word Embeddings of Korean Words
Aug 05, 2017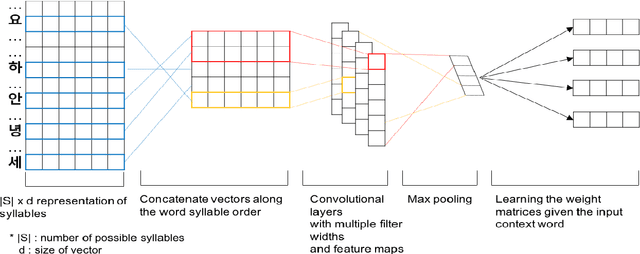

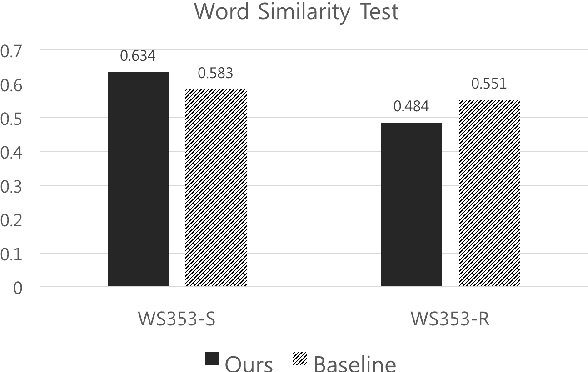
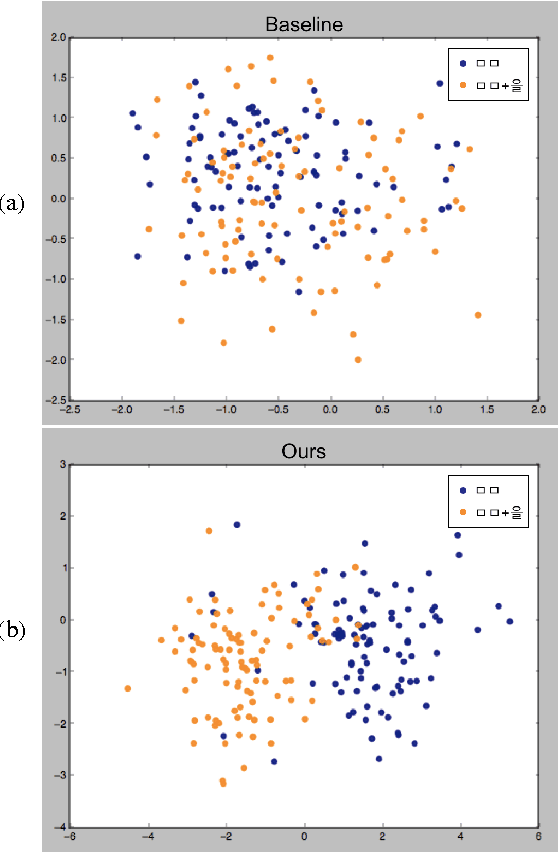
Word embedding has become a fundamental component to many NLP tasks such as named entity recognition and machine translation. However, popular models that learn such embeddings are unaware of the morphology of words, so it is not directly applicable to highly agglutinative languages such as Korean. We propose a syllable-based learning model for Korean using a convolutional neural network, in which word representation is composed of trained syllable vectors. Our model successfully produces morphologically meaningful representation of Korean words compared to the original Skip-gram embeddings. The results also show that it is quite robust to the Out-of-Vocabulary problem.