 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Out-of-Distribution Robustness of Language Models with Parameter-Efficient Transfer Learning
Jan 30, 2023



As the size of the pre-trained language model (PLM) continues to increase, numerous parameter-efficient transfer learning methods have been proposed recently to compensate for the tremendous cost of fine-tuning. Despite the impressive results achieved by large pre-trained language models (PLMs) and various parameter-efficient transfer learning (PETL) methods on sundry benchmarks, it remains unclear if they can handle inputs that have been distributionally shifted effectively. In this study, we systematically explore how the ability to detect out-of-distribution (OOD) changes as the size of the PLM grows or the transfer methods are altered. Specifically, we evaluated various PETL techniques, including fine-tuning, Adapter, LoRA, and prefix-tuning, on three different intention classification tasks, each utilizing various language models with different scales.
Prompt-Augmented Linear Probing: Scaling Beyond The Limit of Few-shot In-Context Learners
Dec 28, 2022Through in-context learning (ICL), large-scale language models are effective few-shot learners without additional model fine-tuning. However, the ICL performance does not scale well with the number of available training samples as it is limited by the inherent input length constraint of the underlying language model. Meanwhile, many studies have revealed that language models are also powerful feature extractors, allowing them to be utilized in a black-box manner and enabling the linear probing paradigm, where lightweight discriminators are trained on top of the pre-extracted input representations. This paper proposes prompt-augmented linear probing (PALP), a hybrid of linear probing and ICL, which leverages the best of both worlds. PALP inherits the scalability of linear probing and the capability of enforcing language models to derive more meaningful representations via tailoring input into a more conceivable form. Throughout in-depth investigations on various datasets, we verified that PALP significantly enhances the input representations closing the gap between ICL in the data-hungry scenario and fine-tuning in the data-abundant scenario with little training overhead, potentially making PALP a strong alternative in a black-box scenario.
Self-Generated In-Context Learning: Leveraging Auto-regressive Language Models as a Demonstration Generator
Jun 16, 2022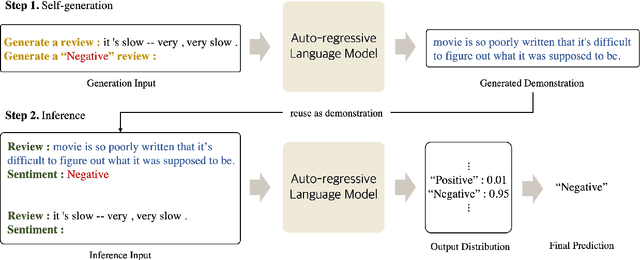
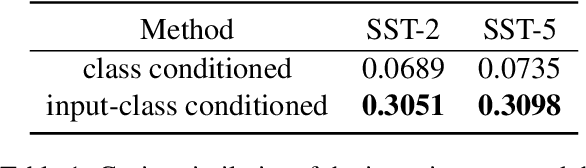
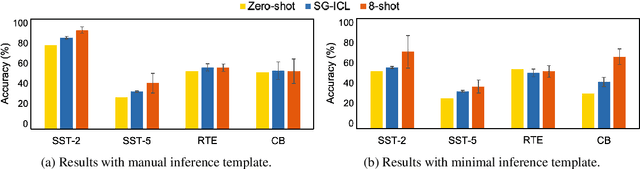
Large-scale pre-trained language models (PLMs) are well-known for being capable of solving a task simply by conditioning a few input-label pairs dubbed demonstrations on a prompt without being explicitly tuned for the desired downstream task. Such a process (i.e., in-context learning), however, naturally leads to high reliance on the demonstrations which are usually selected from external datasets. In this paper, we propose self-generated in-context learning (SG-ICL), which generates demonstrations for in-context learning from PLM itself to minimize the reliance on the external demonstration. We conduct experiments on four different text classification tasks and show SG-ICL significantly outperforms zero-shot learning and is generally worth approximately 0.6 gold training samples. Moreover, our generated demonstrations show more consistent performance with low variance compared to randomly selected demonstrations from the training dataset.
Ground-Truth Labels Matter: A Deeper Look into Input-Label Demonstrations
May 25, 2022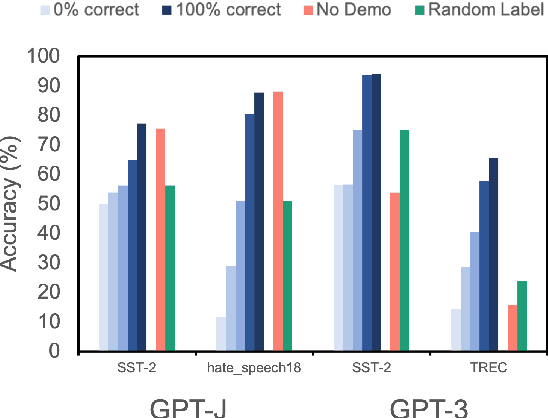
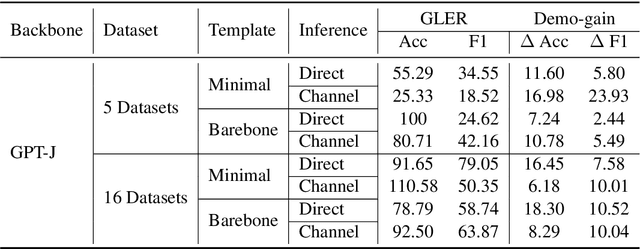
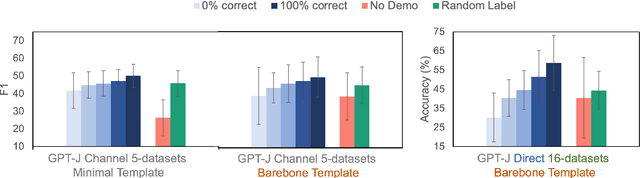
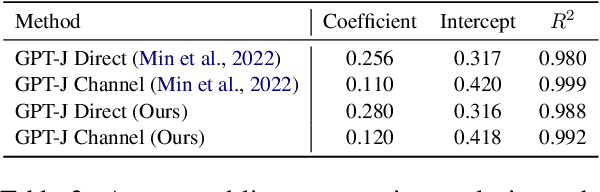
Despite recent explosion in research interests, in-context learning and the precise impact of the quality of demonstrations remain elusive. While, based on current literature, it is expected that in-context learning shares a similar mechanism to supervised learning, Min et al. (2022) recently reported that, surprisingly, input-label correspondence is less important than other aspects of prompt demonstrations. Inspired by this counter-intuitive observation, we re-examine the importance of ground truth labels on in-context learning from diverse and statistical points of view. With the aid of the newly introduced metrics, i.e., Ground-truth Label Effect Ratio (GLER), demo-gain, and label sensitivity, we find that the impact of the correct input-label matching can vary according to different configurations. Expanding upon the previous key finding on the role of demonstrations, the complementary and contrastive results suggest that one might need to take more care when estimating the impact of each component in in-context learning demonstrations.
Exploiting Session Information in BERT-based Session-aware Sequential Recommendation
May 04, 2022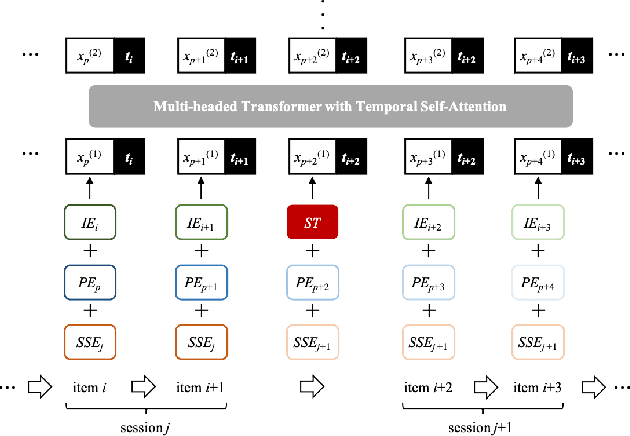
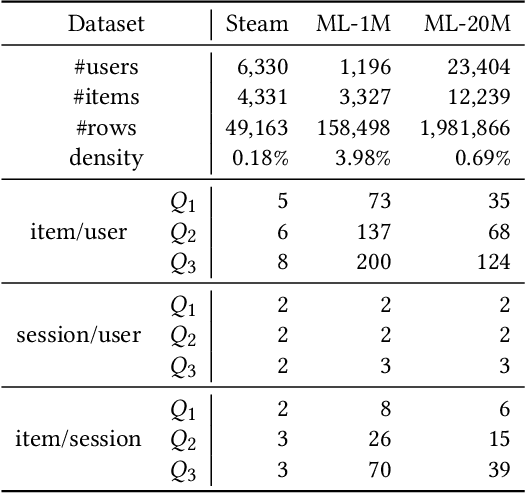
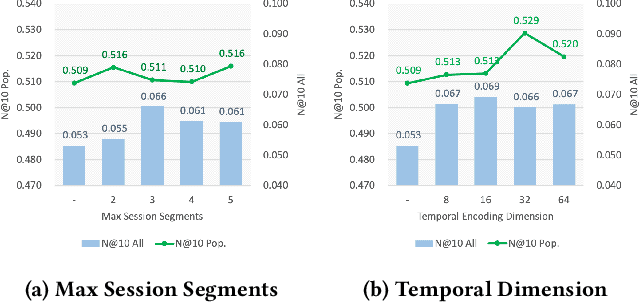
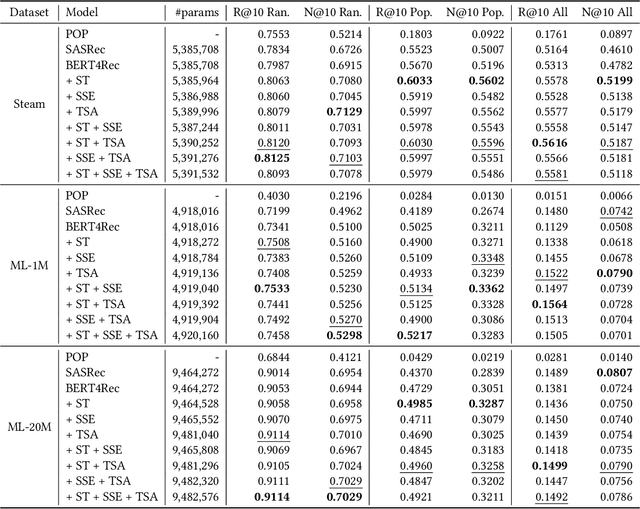
In recommendation systems, utilizing the user interaction history as sequential information has resulted in great performance improvement. However, in many online services, user interactions are commonly grouped by sessions that presumably share preferences, which requires a different approach from ordinary sequence representation techniques. To this end, sequence representation models with a hierarchical structure or various viewpoints have been developed but with a rather complex network structure. In this paper, we propose three methods to improve recommendation performance by exploiting session information while minimizing additional parameters in a BERT-based sequential recommendation model: using session tokens, adding session segment embeddings, and a time-aware self-attention. We demonstrate the feasibility of the proposed methods through experiments on widely used recommendation datasets.
Technologies for AI-Driven Fashion Social Networking Service with E-Commerce
Mar 11, 2022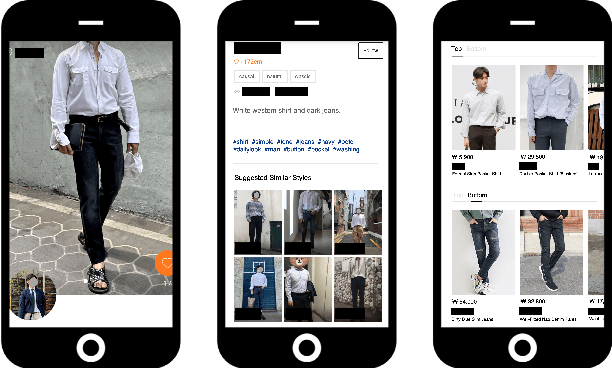
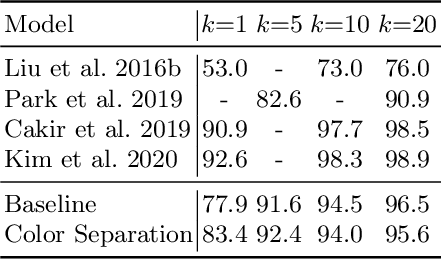
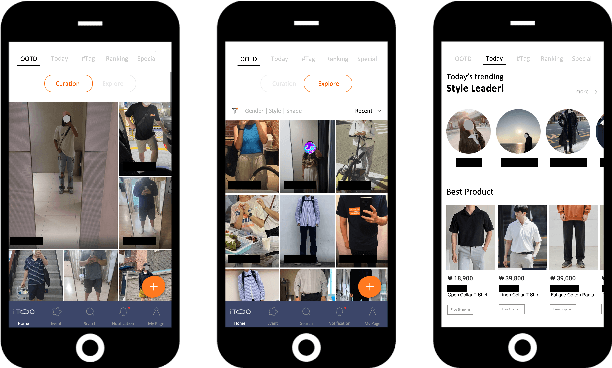

The rapid growth of the online fashion market brought demands for innovative fashion services and commerce platforms. With the recent success of deep learning, many applications employ AI technologies such as visual search and recommender systems to provide novel and beneficial services. In this paper, we describe applied technologies for AI-driven fashion social networking service that incorporate fashion e-commerce. In the application, people can share and browse their outfit-of-the-day (OOTD) photos, while AI analyzes them and suggests similar style OOTDs and related products. To this end, we trained deep learning based AI models for fashion and integrated them to build a fashion visual search system and a recommender system for OOTD. With aforementioned technologies, the AI-driven fashion SNS platform, iTOO, has been successfully launched.
False Negative Distillation and Contrastive Learning for Personalized Outfit Recommendation
Oct 13, 2021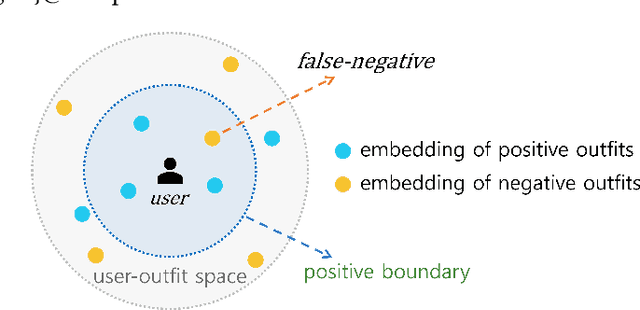
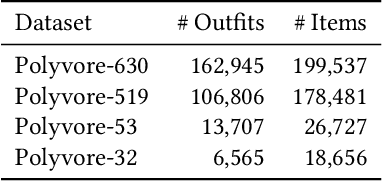
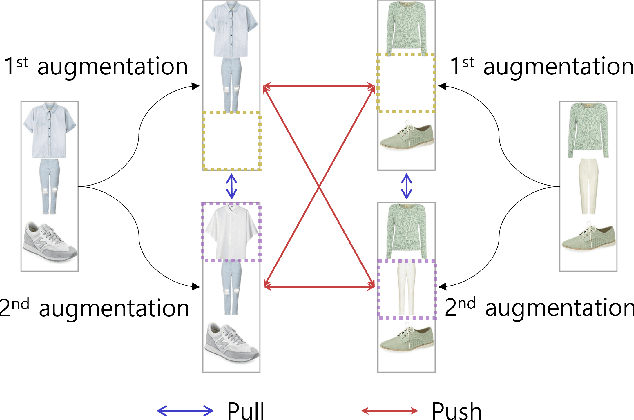
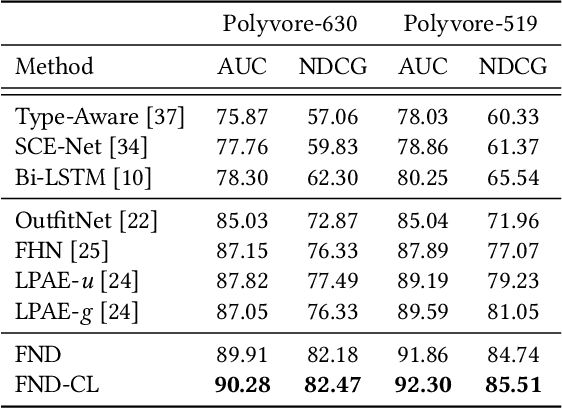
Personalized outfit recommendation has recently been in the spotlight with the rapid growth of the online fashion industry. However, recommending outfits has two significant challenges that should be addressed. The first challenge is that outfit recommendation often requires a complex and large model that utilizes visual information, incurring huge memory and time costs. One natural way to mitigate this problem is to compress such a cumbersome model with knowledge distillation (KD) techniques that leverage knowledge from a pretrained teacher model. However, it is hard to apply existing KD approaches in recommender systems (RS) to the outfit recommendation because they require the ranking of all possible outfits while the number of outfits grows exponentially to the number of consisting clothing items. Therefore, we propose a new KD framework for outfit recommendation, called False Negative Distillation (FND), which exploits false-negative information from the teacher model while not requiring the ranking of all candidates. The second challenge is that the explosive number of outfit candidates amplifying the data sparsity problem, often leading to poor outfit representation. To tackle this issue, inspired by the recent success of contrastive learning (CL), we introduce a CL framework for outfit representation learning with two proposed data augmentation methods. Quantitative and qualitative experiments on outfit recommendation datasets demonstrate the effectiveness and soundness of our proposed methods.
Self-Guided Contrastive Learning for BERT Sentence Representations
Jun 03, 2021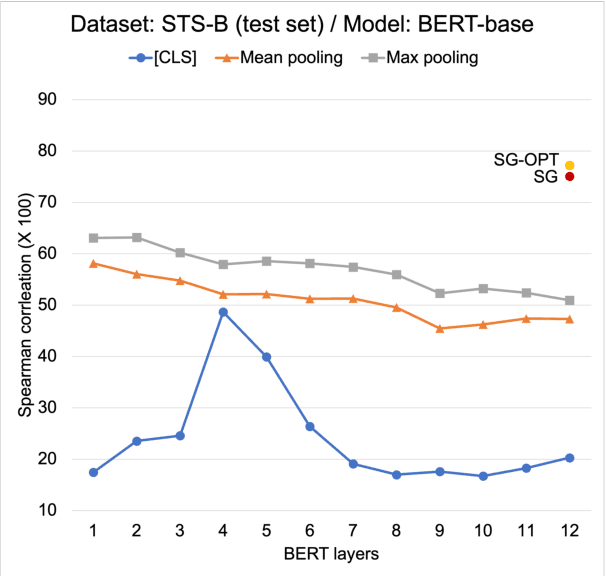
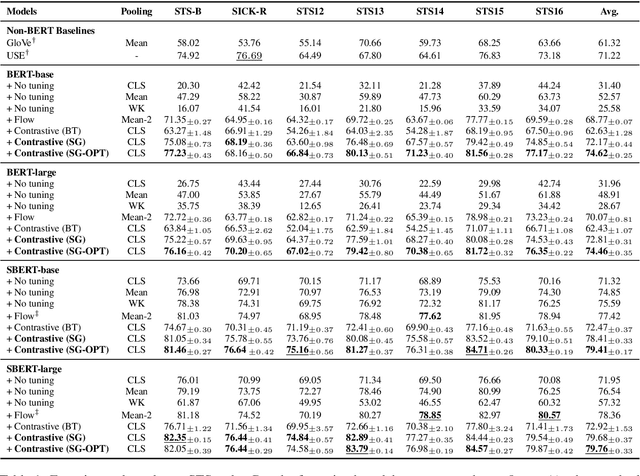
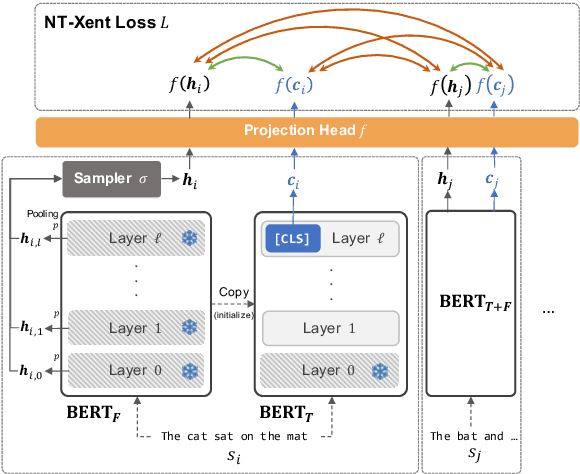
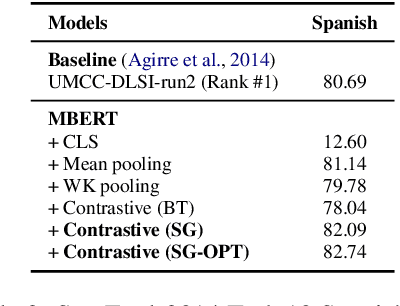
Although BERT and its variants have reshaped the NLP landscape, it still remains unclear how best to derive sentence embeddings from such pre-trained Transformers. In this work, we propose a contrastive learning method that utilizes self-guidance for improving the quality of BERT sentence representations. Our method fine-tunes BERT in a self-supervised fashion, does not rely on data augmentation, and enables the usual [CLS] token embeddings to function as sentence vectors. Moreover, we redesign the contrastive learning objective (NT-Xent) and apply it to sentence representation learning. We demonstrate with extensive experiments that our approach is more effective than competitive baselines on diverse sentence-related tasks. We also show it is efficient at inference and robust to domain shifts.
Masked Contrastive Learning for Anomaly Detection
May 18, 2021
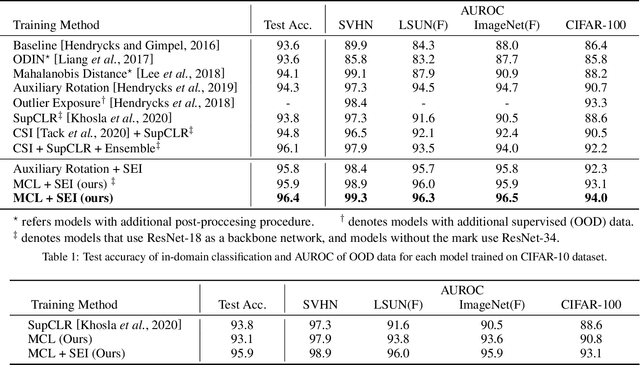

Detecting anomalies is one fundamental aspect of a safety-critical software system, however, it remains a long-standing problem. Numerous branches of works have been proposed to alleviate the complication and have demonstrated their efficiencies. In particular, self-supervised learning based methods are spurring interest due to their capability of learning diverse representations without additional labels. Among self-supervised learning tactics, contrastive learning is one specific framework validating their superiority in various fields, including anomaly detection. However, the primary objective of contrastive learning is to learn task-agnostic features without any labels, which is not entirely suited to discern anomalies. In this paper, we propose a task-specific variant of contrastive learning named masked contrastive learning, which is more befitted for anomaly detection. Moreover, we propose a new inference method dubbed self-ensemble inference that further boosts performance by leveraging the ability learned through auxiliary self-supervision tasks. By combining our models, we can outperform previous state-of-the-art methods by a significant margin on various benchmark datasets.
Contrastive Learning for Unsupervised Image-to-Image Translation
May 07, 2021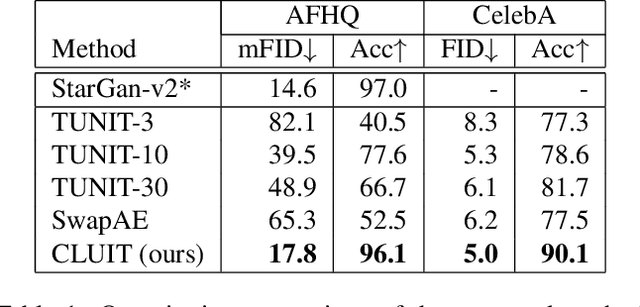
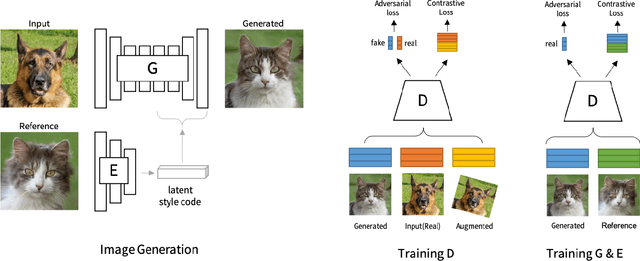
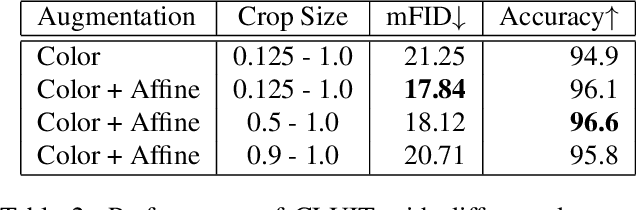

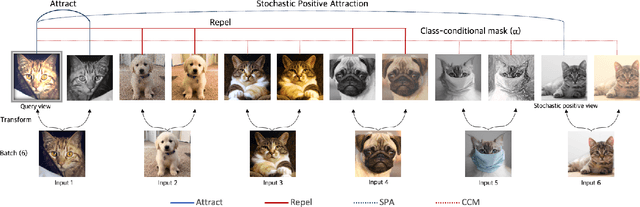
Image-to-image translation aims to learn a mapping between different groups of visually distinguishable images. While recent methods have shown impressive ability to change even intricate appearance of images, they still rely on domain labels in training a model to distinguish between distinct visual features. Such dependency on labels often significantly limits the scope of applications since consistent and high-quality labels are expensive. Instead, we wish to capture visual features from images themselves and apply them to enable realistic translation without human-generated labels. To this end, we propose an unsupervised image-to-image translation method based on contrastive learning. The key idea is to learn a discriminator that differentiates between distinctive styles and let the discriminator supervise a generator to transfer those styles across images. During training, we randomly sample a pair of images and train the generator to change the appearance of one towards another while keeping the original structure. Experimental results show that our method outperforms the leading unsupervised baselines in terms of visual quality and translation accuracy.