 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDAVET: Traffic Vehicle Anomaly Detection Mechanism based on spatial and temporal structures in vehicle traffic
Oct 28, 2023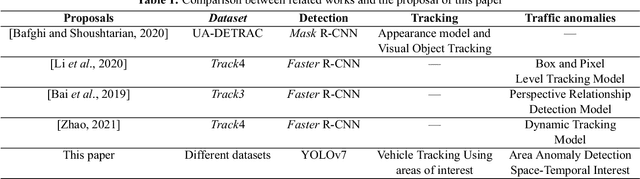

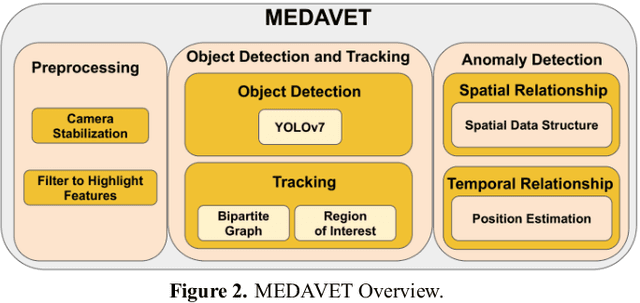
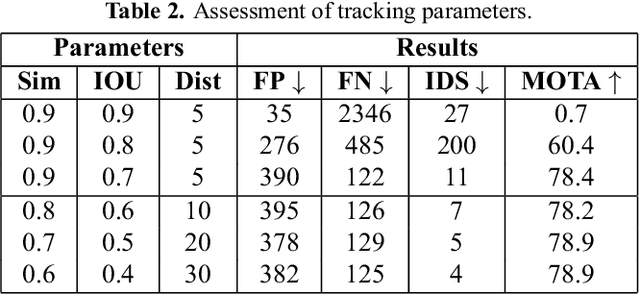
Currently, there are computer vision systems that help us with tasks that would be dull for humans, such as surveillance and vehicle tracking. An important part of this analysis is to identify traffic anomalies. An anomaly tells us that something unusual has happened, in this case on the highway. This paper aims to model vehicle tracking using computer vision to detect traffic anomalies on a highway. We develop the steps of detection, tracking, and analysis of traffic: the detection of vehicles from video of urban traffic, the tracking of vehicles using a bipartite graph and the Convex Hull algorithm to delimit moving areas. Finally for anomaly detection we use two data structures to detect the beginning and end of the anomaly. The first is the QuadTree that groups vehicles that are stopped for a long time on the road and the second that approaches vehicles that are occluded. Experimental results show that our method is acceptable on the Track4 test set, with an F1 score of 85.7% and a mean squared error of 25.432.
Continuous Outlier Mining of Streaming Data in Flink
Feb 21, 2019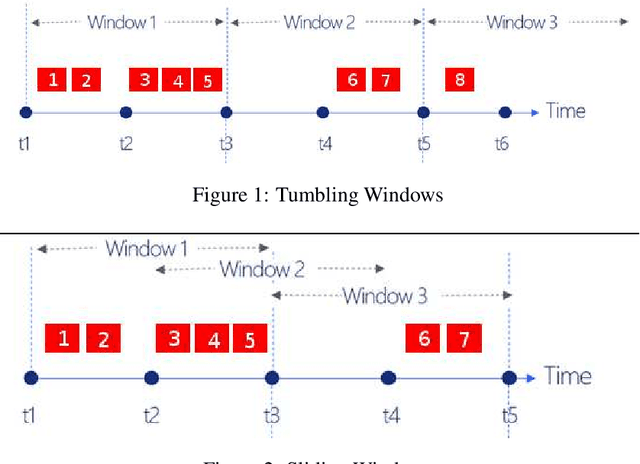
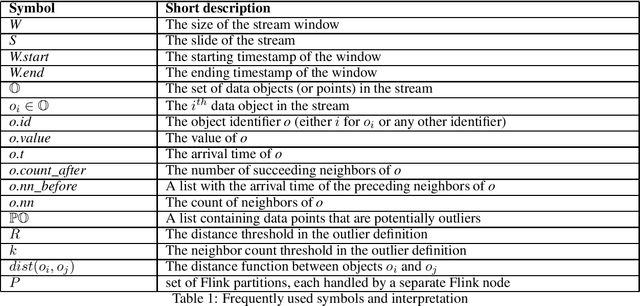
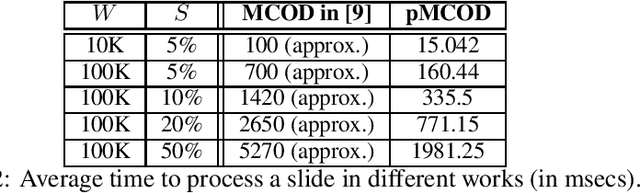
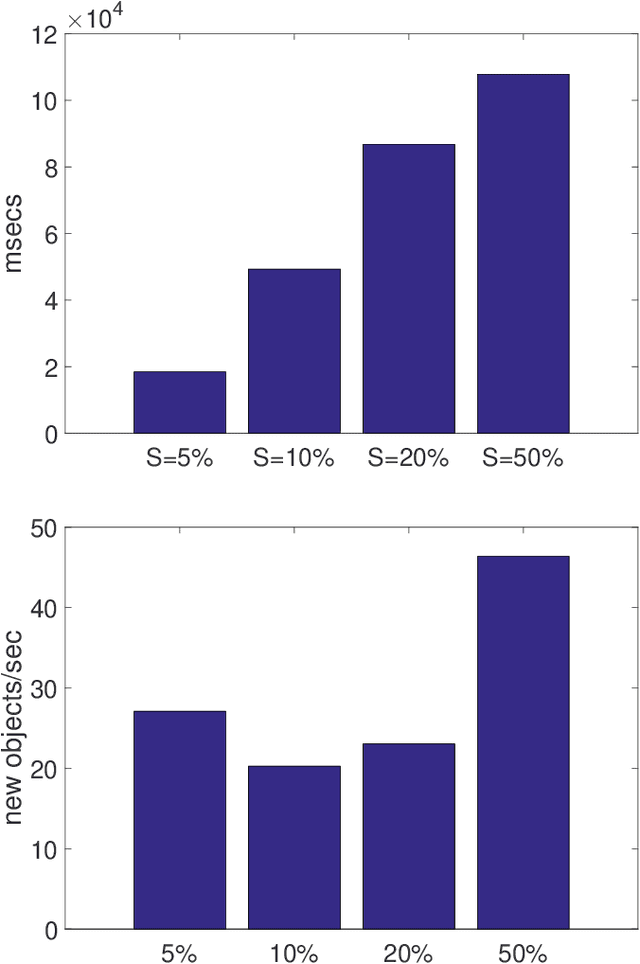
In this work, we focus on distance-based outliers in a metric space, where the status of an entity as to whether it is an outlier is based on the number of other entities in its neighborhood. In recent years, several solutions have tackled the problem of distance-based outliers in data streams, where outliers must be mined continuously as new elements become available. An interesting research problem is to combine the streaming environment with massively parallel systems to provide scalable streambased algorithms. However, none of the previously proposed techniques refer to a massively parallel setting. Our proposal fills this gap and investigates the challenges in transferring state-of-the-art techniques to Apache Flink, a modern platform for intensive streaming analytics. We thoroughly present the technical challenges encountered and the alternatives that may be applied. We show speed-ups of up to 117 (resp. 2076) times over a naive parallel (resp. non-parallel) solution in Flink, by using just an ordinary four-core machine and a real-world dataset. When moving to a three-machine cluster, due to less contention, we manage to achieve both better scalability in terms of the window slide size and the data dimensionality, and even higher speed-ups, e.g., by a factor of 510. Overall, our results demonstrate that oulier mining can be achieved in an efficient and scalable manner. The resulting techniques have been made publicly available as open-source software.