 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of key flavors of event-driven predictive maintenance using logs of phenomena described by Weibull distributions
Jan 18, 2021
This work explores two approaches to event-driven predictive maintenance in Industry 4.0 that cast the problem at hand as a classification or a regression one, respectively, using as a starting point two state-of-the-art solutions. For each of the two approaches, we examine different data preprocessing techniques, different prediction algorithms and the impact of ensemble and sampling methods. Through systematic experiments regarding the aspectsmentioned above,we aimto understand the strengths of the alternatives, and more importantly, shed light on how to navigate through the vast number of such alternatives in an informed manner. Our work constitutes a key step towards understanding the true potential of this type of data-driven predictive maintenance as of to date, and assist practitioners in focusing on the aspects that have the greatest impact.
Continuous Outlier Mining of Streaming Data in Flink
Feb 21, 2019
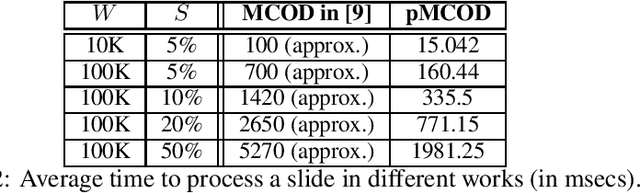
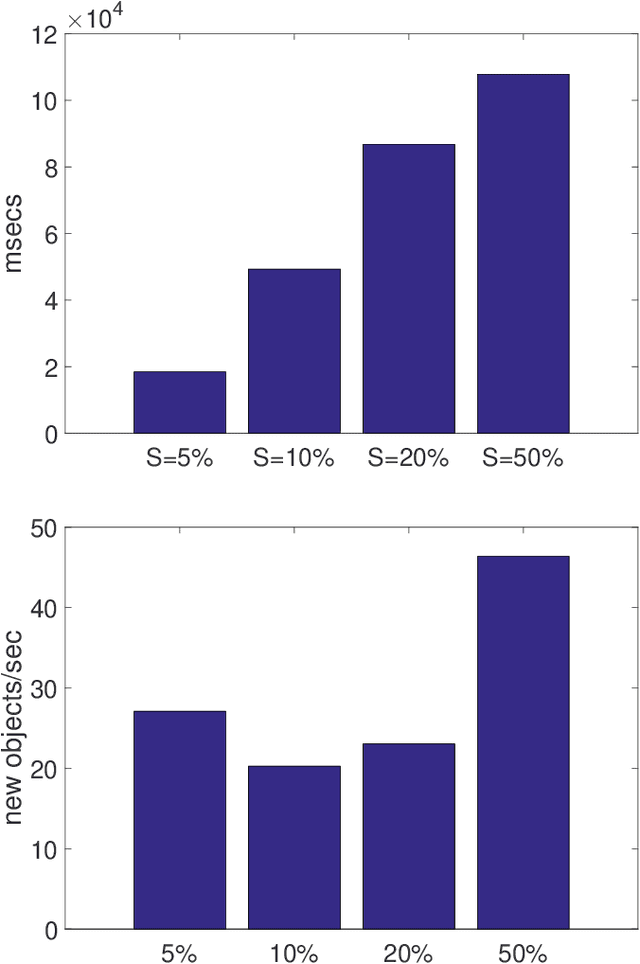
In this work, we focus on distance-based outliers in a metric space, where the status of an entity as to whether it is an outlier is based on the number of other entities in its neighborhood. In recent years, several solutions have tackled the problem of distance-based outliers in data streams, where outliers must be mined continuously as new elements become available. An interesting research problem is to combine the streaming environment with massively parallel systems to provide scalable streambased algorithms. However, none of the previously proposed techniques refer to a massively parallel setting. Our proposal fills this gap and investigates the challenges in transferring state-of-the-art techniques to Apache Flink, a modern platform for intensive streaming analytics. We thoroughly present the technical challenges encountered and the alternatives that may be applied. We show speed-ups of up to 117 (resp. 2076) times over a naive parallel (resp. non-parallel) solution in Flink, by using just an ordinary four-core machine and a real-world dataset. When moving to a three-machine cluster, due to less contention, we manage to achieve both better scalability in terms of the window slide size and the data dimensionality, and even higher speed-ups, e.g., by a factor of 510. Overall, our results demonstrate that oulier mining can be achieved in an efficient and scalable manner. The resulting techniques have been made publicly available as open-source software.