 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecodable but not structured: linear probing enables Underwater Acoustic Target Recognition with pretrained audio embeddings
Jan 13, 2026Increasing levels of anthropogenic noise from ships contribute significantly to underwater sound pollution, posing risks to marine ecosystems. This makes monitoring crucial to understand and quantify the impact of the ship radiated noise. Passive Acoustic Monitoring (PAM) systems are widely deployed for this purpose, generating years of underwater recordings across diverse soundscapes. Manual analysis of such large-scale data is impractical, motivating the need for automated approaches based on machine learning. Recent advances in automatic Underwater Acoustic Target Recognition (UATR) have largely relied on supervised learning, which is constrained by the scarcity of labeled data. Transfer Learning (TL) offers a promising alternative to mitigate this limitation. In this work, we conduct the first empirical comparative study of transfer learning for UATR, evaluating multiple pretrained audio models originating from diverse audio domains. The pretrained model weights are frozen, and the resulting embeddings are analyzed through classification, clustering, and similarity-based evaluations. The analysis shows that the geometrical structure of the embedding space is largely dominated by recording-specific characteristics. However, a simple linear probe can effectively suppress this recording-specific information and isolate ship-type features from these embeddings. As a result, linear probing enables effective automatic UATR using pretrained audio models at low computational cost, significantly reducing the need for a large amounts of high-quality labeled ship recordings.
Automated data curation for self-supervised learning in underwater acoustic analysis
May 26, 2025



The sustainability of the ocean ecosystem is threatened by increased levels of sound pollution, making monitoring crucial to understand its variability and impact. Passive acoustic monitoring (PAM) systems collect a large amount of underwater sound recordings, but the large volume of data makes manual analysis impossible, creating the need for automation. Although machine learning offers a potential solution, most underwater acoustic recordings are unlabeled. Self-supervised learning models have demonstrated success in learning from large-scale unlabeled data in various domains like computer vision, Natural Language Processing, and audio. However, these models require large, diverse, and balanced datasets for training in order to generalize well. To address this, a fully automated self-supervised data curation pipeline is proposed to create a diverse and balanced dataset from raw PAM data. It integrates Automatic Identification System (AIS) data with recordings from various hydrophones in the U.S. waters. Using hierarchical k-means clustering, the raw audio data is sampled and then combined with AIS samples to create a balanced and diverse dataset. The resulting curated dataset enables the development of self-supervised learning models, facilitating various tasks such as monitoring marine mammals and assessing sound pollution.
The Computation of Generalized Embeddings for Underwater Acoustic Target Recognition using Contrastive Learning
May 19, 2025



The increasing level of sound pollution in marine environments poses an increased threat to ocean health, making it crucial to monitor underwater noise. By monitoring this noise, the sources responsible for this pollution can be mapped. Monitoring is performed by passively listening to these sounds. This generates a large amount of data records, capturing a mix of sound sources such as ship activities and marine mammal vocalizations. Although machine learning offers a promising solution for automatic sound classification, current state-of-the-art methods implement supervised learning. This requires a large amount of high-quality labeled data that is not publicly available. In contrast, a massive amount of lower-quality unlabeled data is publicly available, offering the opportunity to explore unsupervised learning techniques. This research explores this possibility by implementing an unsupervised Contrastive Learning approach. Here, a Conformer-based encoder is optimized by the so-called Variance-Invariance-Covariance Regularization loss function on these lower-quality unlabeled data and the translation to the labeled data is made. Through classification tasks involving recognizing ship types and marine mammal vocalizations, our method demonstrates to produce robust and generalized embeddings. This shows to potential of unsupervised methods for various automatic underwater acoustic analysis tasks.
Optimizing Power Grid Topologies with Reinforcement Learning: A Survey of Methods and Challenges
Apr 11, 2025Power grid operation is becoming increasingly complex due to the rising integration of renewable energy sources and the need for more adaptive control strategies. Reinforcement Learning (RL) has emerged as a promising approach to power network control (PNC), offering the potential to enhance decision-making in dynamic and uncertain environments. The Learning To Run a Power Network (L2RPN) competitions have played a key role in accelerating research by providing standardized benchmarks and problem formulations, leading to rapid advancements in RL-based methods. This survey provides a comprehensive and structured overview of RL applications for power grid topology optimization, categorizing existing techniques, highlighting key design choices, and identifying gaps in current research. Additionally, we present a comparative numerical study evaluating the impact of commonly applied RL-based methods, offering insights into their practical effectiveness. By consolidating existing research and outlining open challenges, this survey aims to provide a foundation for future advancements in RL-driven power grid optimization.
Unveiling the Potential: Harnessing Deep Metric Learning to Circumvent Video Streaming Encryption
May 16, 2024Encryption on the internet with the shift to HTTPS has been an important step to improve the privacy of internet users. However, there is an increasing body of work about extracting information from encrypted internet traffic without having to decrypt it. Such attacks bypass security guarantees assumed to be given by HTTPS and thus need to be understood. Prior works showed that the variable bitrates of video streams are sufficient to identify which video someone is watching. These works generally have to make trade-offs in aspects such as accuracy, scalability, robustness, etc. These trade-offs complicate the practical use of these attacks. To that end, we propose a deep metric learning framework based on the triplet loss method. Through this framework, we achieve robust, generalisable, scalable and transferable encrypted video stream detection. First, the triplet loss is better able to deal with video streams not seen during training. Second, our approach can accurately classify videos not seen during training. Third, we show that our method scales well to a dataset of over 1000 videos. Finally, we show that a model trained on video streams over Chrome can also classify streams over Firefox. Our results suggest that this side-channel attack is more broadly applicable than originally thought. We provide our code alongside a diverse and up-to-date dataset for future research.
A Machine Learning Approach for Simultaneous Demapping of QAM and APSK Constellations
May 16, 2024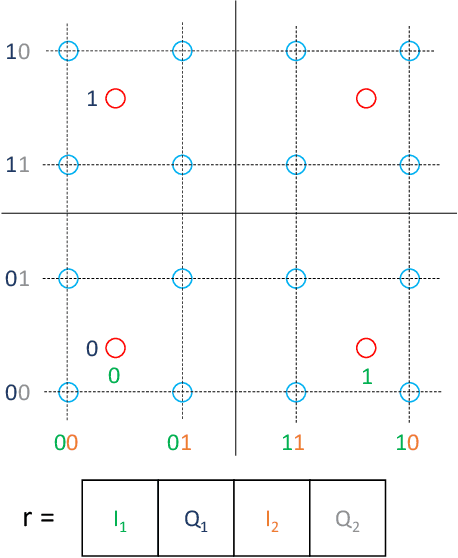
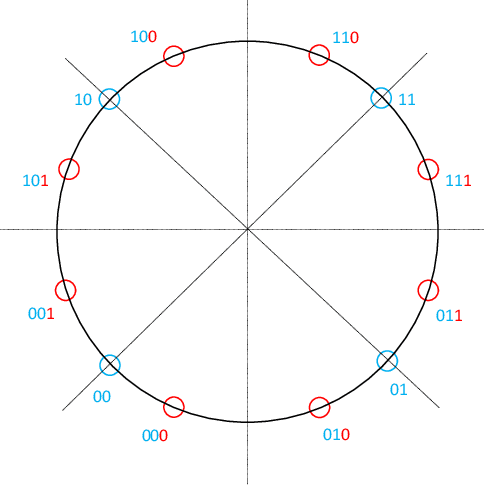
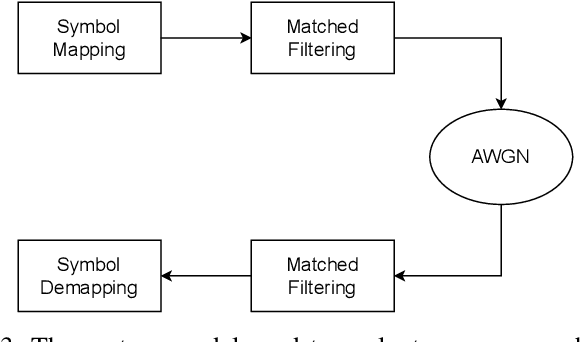
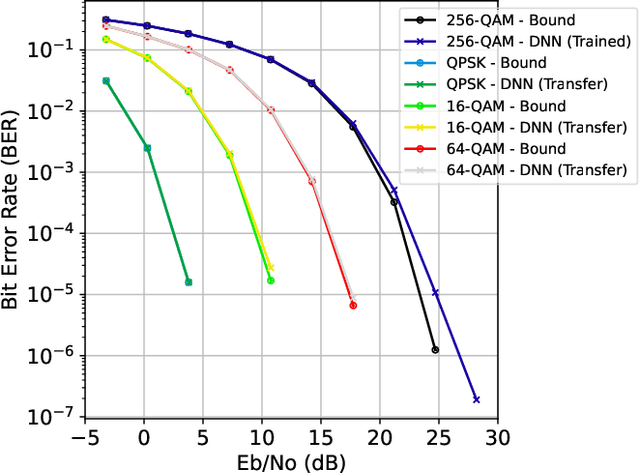
As telecommunication systems evolve to meet increasing demands, integrating deep neural networks (DNNs) has shown promise in enhancing performance. However, the trade-off between accuracy and flexibility remains challenging when replacing traditional receivers with DNNs. This paper introduces a novel probabilistic framework that allows a single DNN demapper to demap multiple QAM and APSK constellations simultaneously. We also demonstrate that our framework allows exploiting hierarchical relationships in families of constellations. The consequence is that we need fewer neural network outputs to encode the same function without an increase in Bit Error Rate (BER). Our simulation results confirm that our approach approaches the optimal demodulation error bound under an Additive White Gaussian Noise (AWGN) channel for multiple constellations. Thereby, we address multiple important issues in making DNNs flexible enough for practical use as receivers.
Robustly overfitting latents for flexible neural image compression
Jan 31, 2024Neural image compression has made a great deal of progress. State-of-the-art models are based on variational autoencoders and are outperforming classical models. Neural compression models learn to encode an image into a quantized latent representation that can be efficiently sent to the decoder, which decodes the quantized latent into a reconstructed image. While these models have proven successful in practice, they lead to sub-optimal results due to imperfect optimization and limitations in the encoder and decoder capacity. Recent work shows how to use stochastic Gumbel annealing (SGA) to refine the latents of pre-trained neural image compression models. We extend this idea by introducing SGA+, which contains three different methods that build upon SGA. Further, we give a detailed analysis of our proposed methods, show how they improve performance, and show that they are less sensitive to hyperparameter choices. Besides, we show how each method can be extended to three- instead of two-class rounding. Finally, we show how refinement of the latents with our best-performing method improves the compression performance on the Tecnick dataset and how it can be deployed to partly move along the rate-distortion curve.
Multi-Agent Reinforcement Learning for Power Grid Topology Optimization
Oct 04, 2023Recent challenges in operating power networks arise from increasing energy demands and unpredictable renewable sources like wind and solar. While reinforcement learning (RL) shows promise in managing these networks, through topological actions like bus and line switching, efficiently handling large action spaces as networks grow is crucial. This paper presents a hierarchical multi-agent reinforcement learning (MARL) framework tailored for these expansive action spaces, leveraging the power grid's inherent hierarchical nature. Experimental results indicate the MARL framework's competitive performance with single-agent RL methods. We also compare different RL algorithms for lower-level agents alongside different policies for higher-order agents.
The Berkelmans-Pries Feature Importance Method: A Generic Measure of Informativeness of Features
Jan 11, 2023Over the past few years, the use of machine learning models has emerged as a generic and powerful means for prediction purposes. At the same time, there is a growing demand for interpretability of prediction models. To determine which features of a dataset are important to predict a target variable $Y$, a Feature Importance (FI) method can be used. By quantifying how important each feature is for predicting $Y$, irrelevant features can be identified and removed, which could increase the speed and accuracy of a model, and moreover, important features can be discovered, which could lead to valuable insights. A major problem with evaluating FI methods, is that the ground truth FI is often unknown. As a consequence, existing FI methods do not give the exact correct FI values. This is one of the many reasons why it can be hard to properly interpret the results of an FI method. Motivated by this, we introduce a new global approach named the Berkelmans-Pries FI method, which is based on a combination of Shapley values and the Berkelmans-Pries dependency function. We prove that our method has many useful properties, and accurately predicts the correct FI values for several cases where the ground truth FI can be derived in an exact manner. We experimentally show for a large collection of FI methods (468) that existing methods do not have the same useful properties. This shows that the Berkelmans-Pries FI method is a highly valuable tool for analyzing datasets with complex interdependencies.
The Optimal Input-Independent Baseline for Binary Classification: The Dutch Draw
Jan 09, 2023Before any binary classification model is taken into practice, it is important to validate its performance on a proper test set. Without a frame of reference given by a baseline method, it is impossible to determine if a score is `good' or `bad'. The goal of this paper is to examine all baseline methods that are independent of feature values and determine which model is the `best' and why. By identifying which baseline models are optimal, a crucial selection decision in the evaluation process is simplified. We prove that the recently proposed Dutch Draw baseline is the best input-independent classifier (independent of feature values) for all positional-invariant measures (independent of sequence order) assuming that the samples are randomly shuffled. This means that the Dutch Draw baseline is the optimal baseline under these intuitive requirements and should therefore be used in practice.