 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact and Evolutionary Algorithms for Sequential Multi-Objective Transmission Topology Planning
May 05, 2026We address day-ahead transmission topology planning and congestion management as a sequential, multi-objective optimization problem and develop two complementary algorithms for it: an exact enumeration method and a tailored evolutionary heuristic. The problem is formulated with four operational objectives reflecting real TSO decision criteria: worst-case line loading under $N-1$ security, topological depth, number of switching actions, and time spent in non-reference topologies, over a 24-hour horizon. We introduce the block algorithm, an exact method that exploits the temporal block structure of feasible strategies to enumerate the complete Pareto front; for fixed operational bounds on depth and switch count, its evaluation count grows polynomially with the planning horizon. We complement it with a multi-objective evolutionary algorithm based on NSGA-III, with structure-guided initialization and problem-specific variation operators tailored to the topology-planning structure. Using real operational data from the Dutch high-voltage grid operated by TenneT TSO, we show that the block algorithm computes the full Pareto front for a highly congested day in under three minutes, and that the evolutionary algorithm converges toward but does not recover the exact front. The block algorithm thus provides both a practical decision-support tool and a ground-truth benchmark for future heuristic and learning-based methods on this problem class.
Optimizing Power Grid Topologies with Reinforcement Learning: A Survey of Methods and Challenges
Apr 11, 2025Power grid operation is becoming increasingly complex due to the rising integration of renewable energy sources and the need for more adaptive control strategies. Reinforcement Learning (RL) has emerged as a promising approach to power network control (PNC), offering the potential to enhance decision-making in dynamic and uncertain environments. The Learning To Run a Power Network (L2RPN) competitions have played a key role in accelerating research by providing standardized benchmarks and problem formulations, leading to rapid advancements in RL-based methods. This survey provides a comprehensive and structured overview of RL applications for power grid topology optimization, categorizing existing techniques, highlighting key design choices, and identifying gaps in current research. Additionally, we present a comparative numerical study evaluating the impact of commonly applied RL-based methods, offering insights into their practical effectiveness. By consolidating existing research and outlining open challenges, this survey aims to provide a foundation for future advancements in RL-driven power grid optimization.
Multi-Agent Reinforcement Learning for Power Grid Topology Optimization
Oct 04, 2023Recent challenges in operating power networks arise from increasing energy demands and unpredictable renewable sources like wind and solar. While reinforcement learning (RL) shows promise in managing these networks, through topological actions like bus and line switching, efficiently handling large action spaces as networks grow is crucial. This paper presents a hierarchical multi-agent reinforcement learning (MARL) framework tailored for these expansive action spaces, leveraging the power grid's inherent hierarchical nature. Experimental results indicate the MARL framework's competitive performance with single-agent RL methods. We also compare different RL algorithms for lower-level agents alongside different policies for higher-order agents.
RangL: A Reinforcement Learning Competition Platform
Jul 28, 2022
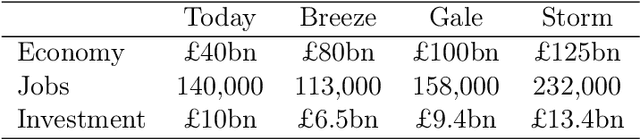
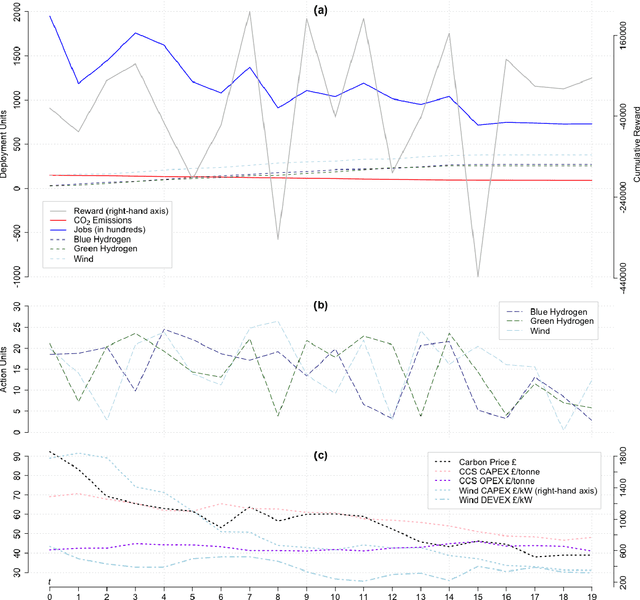
The RangL project hosted by The Alan Turing Institute aims to encourage the wider uptake of reinforcement learning by supporting competitions relating to real-world dynamic decision problems. This article describes the reusable code repository developed by the RangL team and deployed for the 2022 Pathways to Net Zero Challenge, supported by the UK Net Zero Technology Centre. The winning solutions to this particular Challenge seek to optimize the UK's energy transition policy to net zero carbon emissions by 2050. The RangL repository includes an OpenAI Gym reinforcement learning environment and code that supports both submission to, and evaluation in, a remote instance of the open source EvalAI platform as well as all winning learning agent strategies. The repository is an illustrative example of RangL's capability to provide a reusable structure for future challenges.