 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeARC: Adversarially Robust Control Policies for Autonomous Vehicles
Jul 09, 2021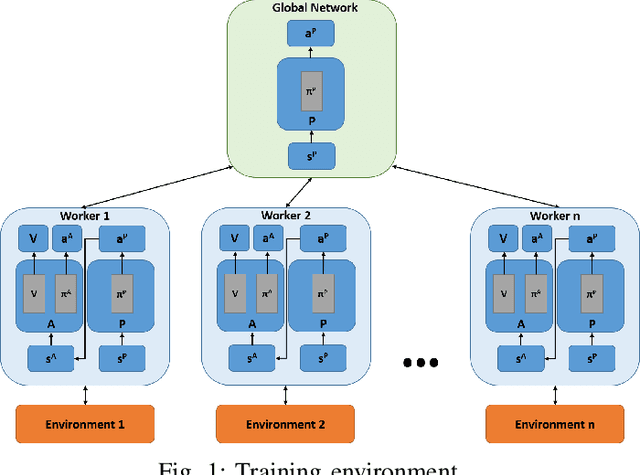
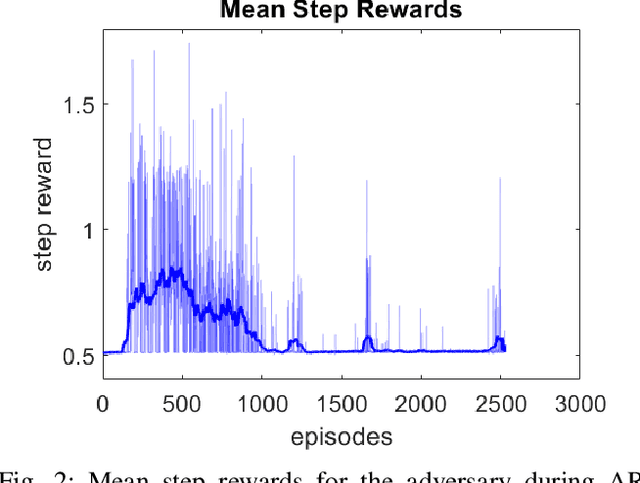
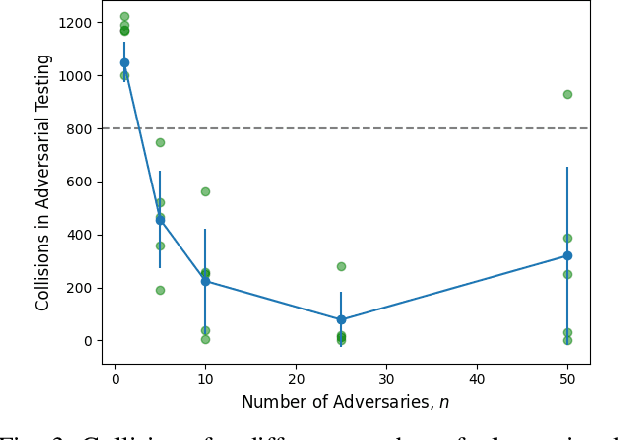
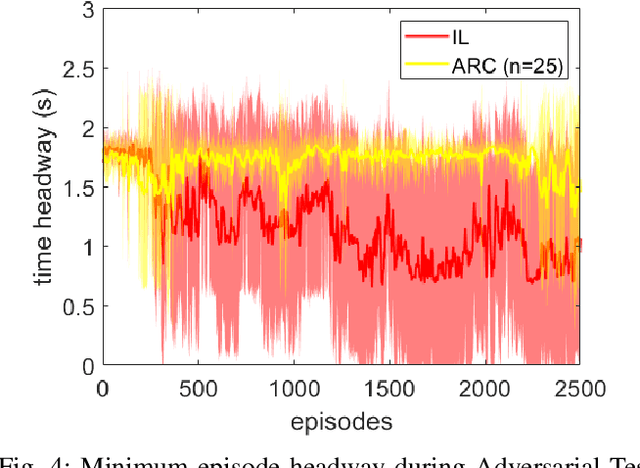
Deep neural networks have demonstrated their capability to learn control policies for a variety of tasks. However, these neural network-based policies have been shown to be susceptible to exploitation by adversarial agents. Therefore, there is a need to develop techniques to learn control policies that are robust against adversaries. We introduce Adversarially Robust Control (ARC), which trains the protagonist policy and the adversarial policy end-to-end on the same loss. The aim of the protagonist is to maximise this loss, whilst the adversary is attempting to minimise it. We demonstrate the proposed ARC training in a highway driving scenario, where the protagonist controls the follower vehicle whilst the adversary controls the lead vehicle. By training the protagonist against an ensemble of adversaries, it learns a significantly more robust control policy, which generalises to a variety of adversarial strategies. The approach is shown to reduce the amount of collisions against new adversaries by up to 90.25%, compared to the original policy. Moreover, by utilising an auxiliary distillation loss, we show that the fine-tuned control policy shows no drop in performance across its original training distribution.
Adversarial Mixture Density Networks: Learning to Drive Safely from Collision Data
Jul 09, 2021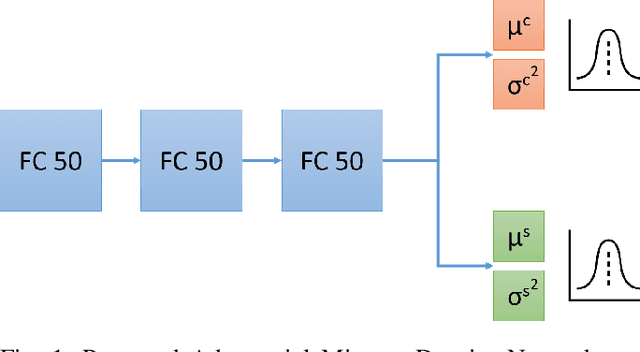
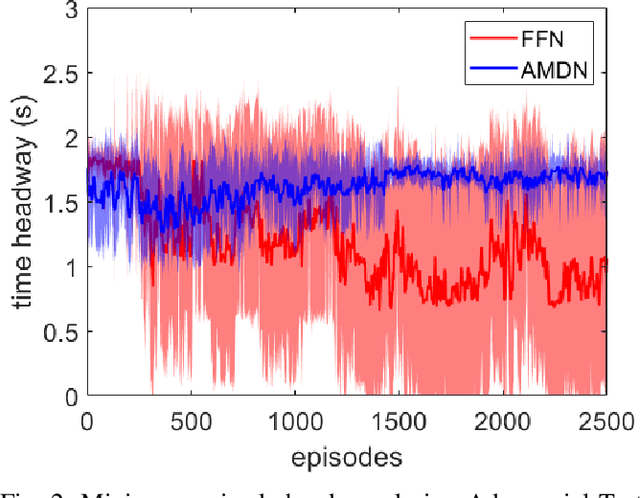
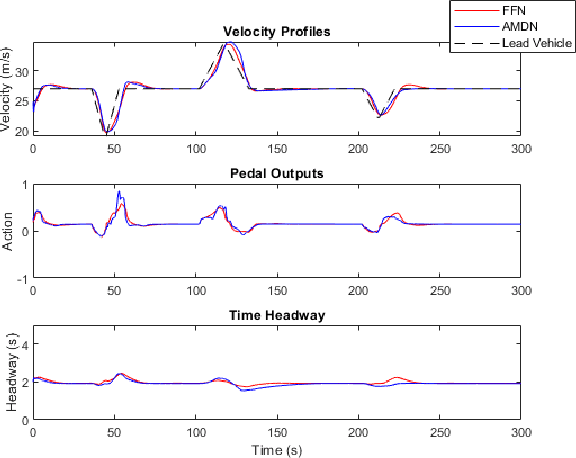
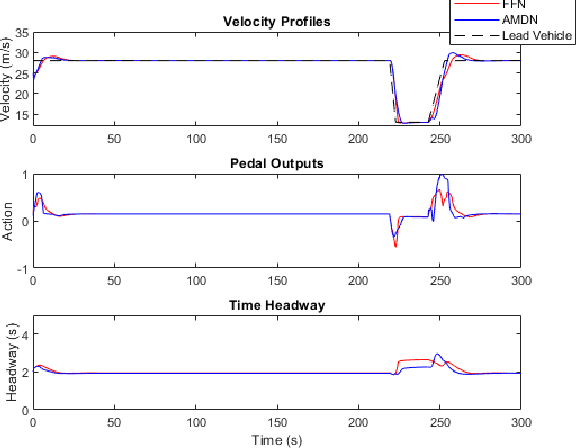
Imitation learning has been widely used to learn control policies for autonomous driving based on pre-recorded data. However, imitation learning based policies have been shown to be susceptible to compounding errors when encountering states outside of the training distribution. Further, these agents have been demonstrated to be easily exploitable by adversarial road users aiming to create collisions. To overcome these shortcomings, we introduce Adversarial Mixture Density Networks (AMDN), which learns two distributions from separate datasets. The first is a distribution of safe actions learned from a dataset of naturalistic human driving. The second is a distribution representing unsafe actions likely to lead to collision, learned from a dataset of collisions. During training, we leverage these two distributions to provide an additional loss based on the similarity of the two distributions. By penalising the safe action distribution based on its similarity to the unsafe action distribution when training on the collision dataset, a more robust and safe control policy is obtained. We demonstrate the proposed AMDN approach in a vehicle following use-case, and evaluate under naturalistic and adversarial testing environments. We show that despite its simplicity, AMDN provides significant benefits for the safety of the learned control policy, when compared to pure imitation learning or standard mixture density network approaches.
Deep Learning Traversability Estimator for Mobile Robots in Unstructured Environments
May 23, 2021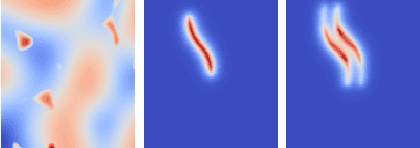


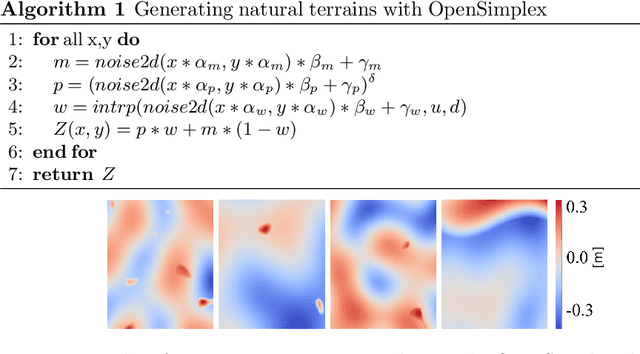
Terrain traversability analysis plays a major role in ensuring safe robotic navigation in unstructured environments. However, real-time constraints frequently limit the accuracy of online tests, especially in scenarios where realistic robot-terrain interactions are complex to model. In this context, we propose a deep learning framework, trained in an end-to-end fashion from elevation maps and trajectories, to estimate the occurrence of failure events. The network is first trained and tested in simulation over synthetic maps generated by the OpenSimplex algorithm. The prediction performance of the Deep Learning framework is illustrated by being able to retain over 94% recall of the original simulator at 30% of the computational time. Finally, the network is transferred and tested on real elevation maps collected by the SEEKER consortium during the Martian rover test trial in the Atacama desert in Chile. We show that transferring and fine-tuning of an application-independent pre-trained model retains better performance than training uniquely on scarcely available real data.
Self-adaptive Torque Vectoring Controller Using Reinforcement Learning
Mar 27, 2021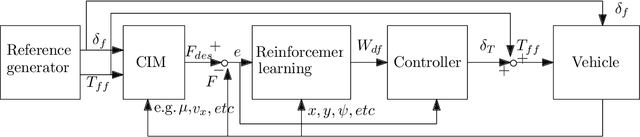
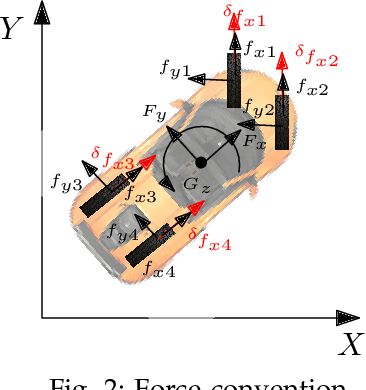
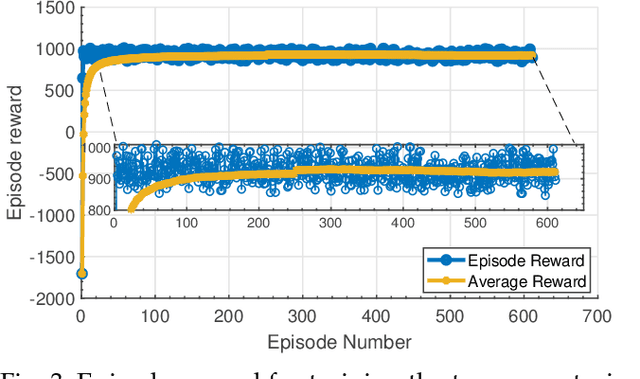
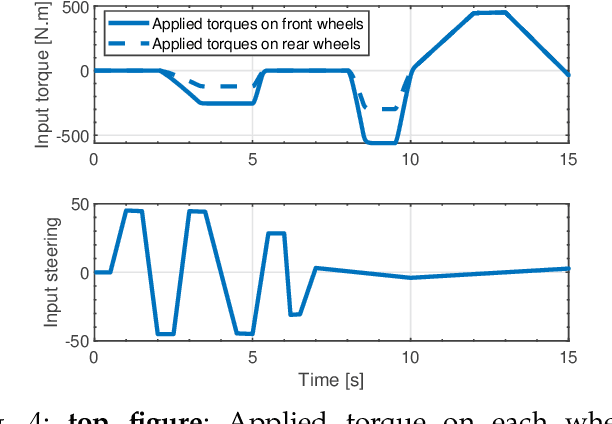
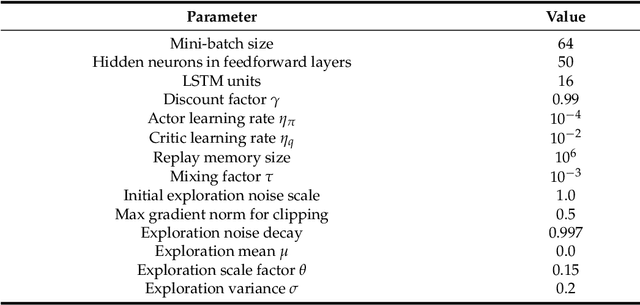
Continuous direct yaw moment control systems such as torque-vectoring controller are an essential part for vehicle stabilization. This controller has been extensively researched with the central objective of maintaining the vehicle stability by providing consistent stable cornering response. The ability of careful tuning of the parameters in a torque-vectoring controller can significantly enhance vehicle's performance and stability. However, without any re-tuning of the parameters, especially in extreme driving conditions e.g. low friction surface or high velocity, the vehicle fails to maintain the stability. In this paper, the utility of Reinforcement Learning (RL) based on Deep Deterministic Policy Gradient (DDPG) as a parameter tuning algorithm for torque-vectoring controller is presented. It is shown that, torque-vectoring controller with parameter tuning via reinforcement learning performs well on a range of different driving environment e.g., wide range of friction conditions and different velocities, which highlight the advantages of reinforcement learning as an adaptive algorithm for parameter tuning. Moreover, the robustness of DDPG algorithm are validated under scenarios which are beyond the training environment of the reinforcement learning algorithm. The simulation has been carried out using a four wheels vehicle model with nonlinear tire characteristics. We compare our DDPG based parameter tuning against a genetic algorithm and a conventional trial-and-error tunning of the torque vectoring controller, and the results demonstrated that the reinforcement learning based parameter tuning significantly improves the stability of the vehicle.
Weakly Supervised Reinforcement Learning for Autonomous Highway Driving via Virtual Safety Cages
Mar 17, 2021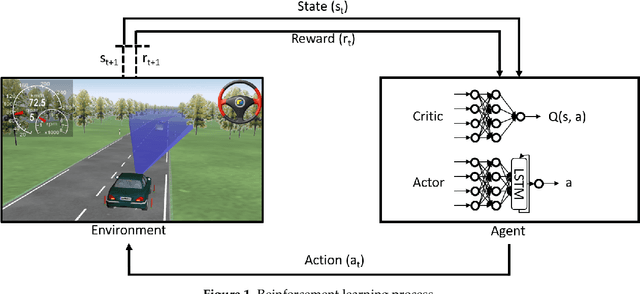
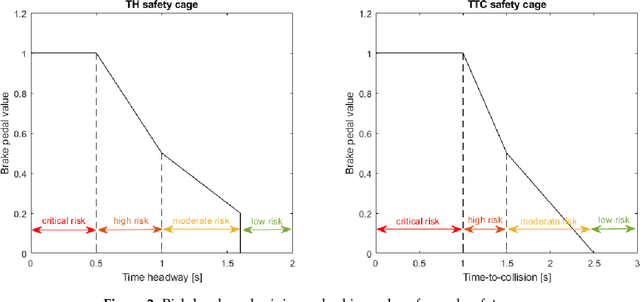
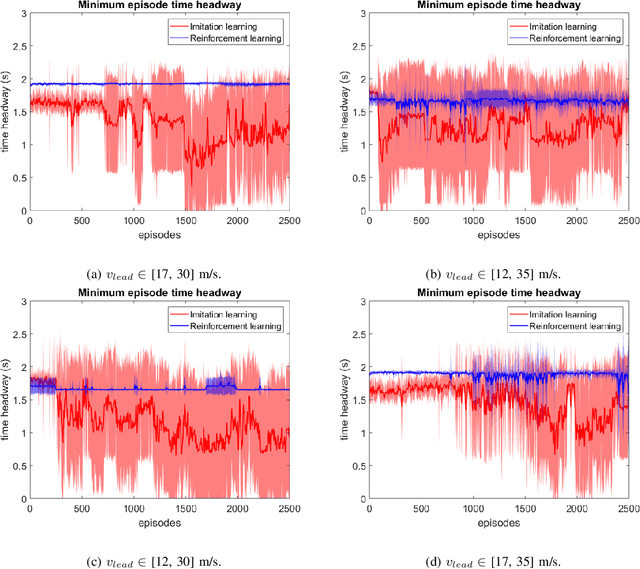
The use of neural networks and reinforcement learning has become increasingly popular in autonomous vehicle control. However, the opaqueness of the resulting control policies presents a significant barrier to deploying neural network-based control in autonomous vehicles. In this paper, we present a reinforcement learning based approach to autonomous vehicle longitudinal control, where the rule-based safety cages provide enhanced safety for the vehicle as well as weak supervision to the reinforcement learning agent. By guiding the agent to meaningful states and actions, this weak supervision improves the convergence during training and enhances the safety of the final trained policy. This rule-based supervisory controller has the further advantage of being fully interpretable, thereby enabling traditional validation and verification approaches to ensure the safety of the vehicle. We compare models with and without safety cages, as well as models with optimal and constrained model parameters, and show that the weak supervision consistently improves the safety of exploration, speed of convergence, and model performance. Additionally, we show that when the model parameters are constrained or sub-optimal, the safety cages can enable a model to learn a safe driving policy even when the model could not be trained to drive through reinforcement learning alone.
* Published in Sensors
Training Adversarial Agents to Exploit Weaknesses in Deep Control Policies
Feb 27, 2020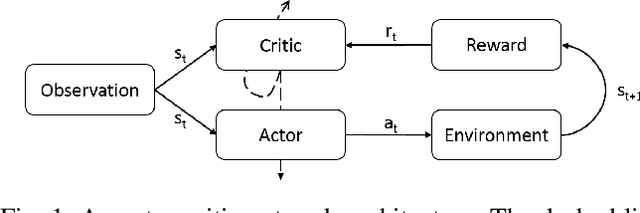
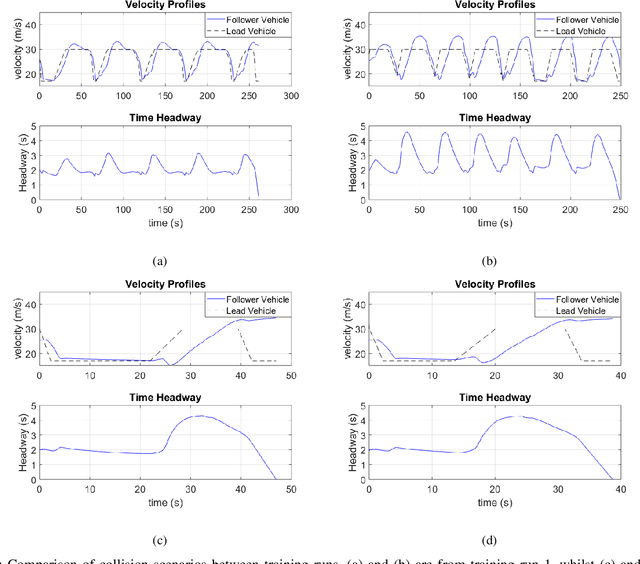
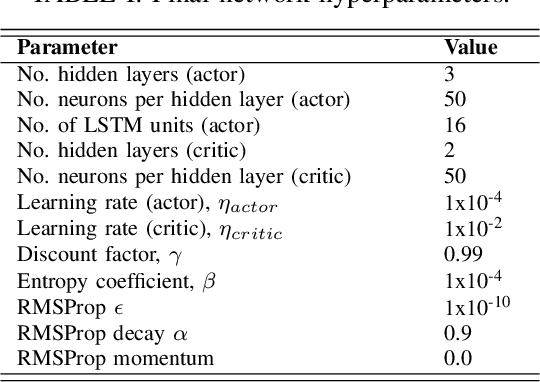
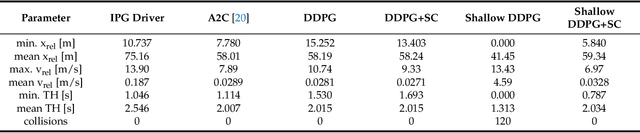
Deep learning has become an increasingly common technique for various control problems, such as robotic arm manipulation, robot navigation, and autonomous vehicles. However, the downside of using deep neural networks to learn control policies is their opaque nature and the difficulties of validating their safety. As the networks used to obtain state-of-the-art results become increasingly deep and complex, the rules they have learned and how they operate become more challenging to understand. This presents an issue, since in safety-critical applications the safety of the control policy must be ensured to a high confidence level. In this paper, we propose an automated black box testing framework based on adversarial reinforcement learning. The technique uses an adversarial agent, whose goal is to degrade the performance of the target model under test. We test the approach on an autonomous vehicle problem, by training an adversarial reinforcement learning agent, which aims to cause a deep neural network-driven autonomous vehicle to collide. Two neural networks trained for autonomous driving are compared, and the results from the testing are used to compare the robustness of their learned control policies. We show that the proposed framework is able to find weaknesses in both control policies that were not evident during online testing and therefore, demonstrate a significant benefit over manual testing methods.
A Survey of Deep Learning Applications to Autonomous Vehicle Control
Dec 23, 2019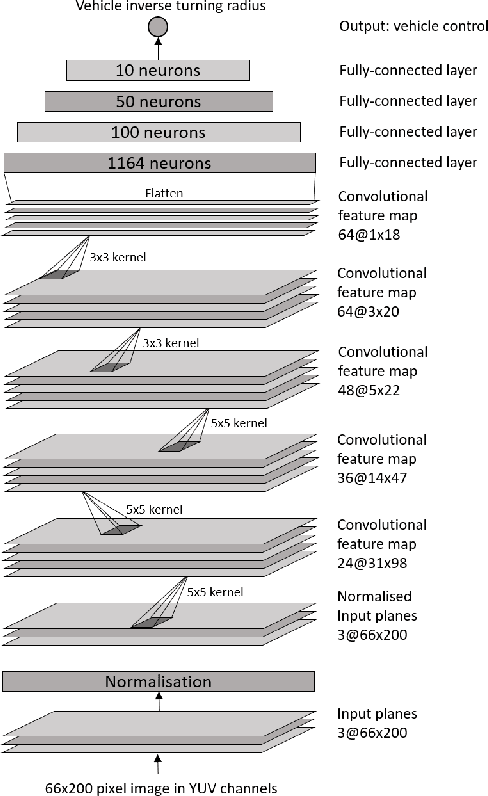
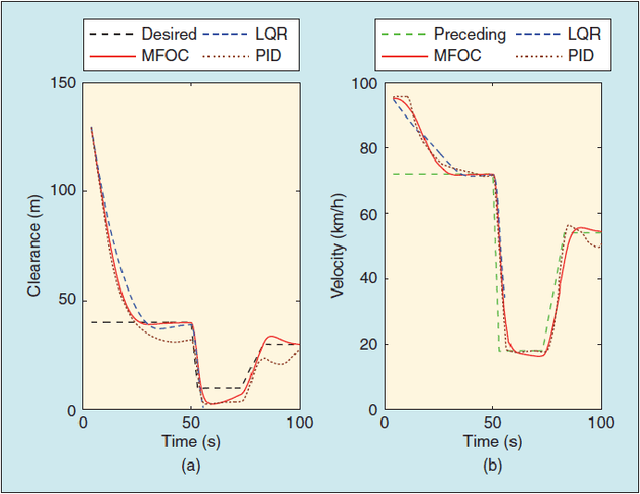

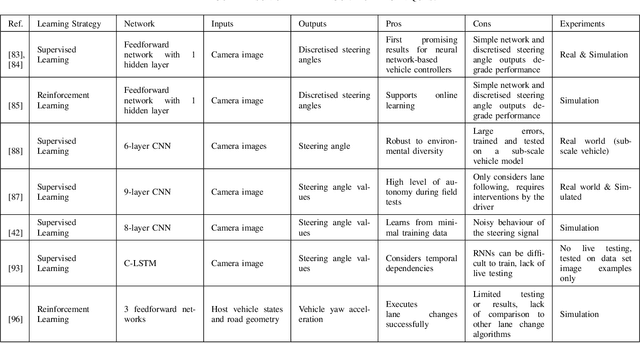
Designing a controller for autonomous vehicles capable of providing adequate performance in all driving scenarios is challenging due to the highly complex environment and inability to test the system in the wide variety of scenarios which it may encounter after deployment. However, deep learning methods have shown great promise in not only providing excellent performance for complex and non-linear control problems, but also in generalising previously learned rules to new scenarios. For these reasons, the use of deep learning for vehicle control is becoming increasingly popular. Although important advancements have been achieved in this field, these works have not been fully summarised. This paper surveys a wide range of research works reported in the literature which aim to control a vehicle through deep learning methods. Although there exists overlap between control and perception, the focus of this paper is on vehicle control, rather than the wider perception problem which includes tasks such as semantic segmentation and object detection. The paper identifies the strengths and limitations of available deep learning methods through comparative analysis and discusses the research challenges in terms of computation, architecture selection, goal specification, generalisation, verification and validation, as well as safety. Overall, this survey brings timely and topical information to a rapidly evolving field relevant to intelligent transportation systems.