 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Vision + Language Models to Predict Item Difficulty
Mar 04, 2026This project investigates the capabilities of large language models (LLMs) to determine the difficulty of data visualization literacy test items. We explore whether features derived from item text (question and answer options), the visualization image, or a combination of both can predict item difficulty (proportion of correct responses) for U.S. adults. We use GPT-4.1-nano to analyze items and generate predictions based on these distinct feature sets. The multimodal approach, using both visual and text features, yields the lowest mean absolute error (MAE) (0.224), outperforming the unimodal vision-only (0.282) and text-only (0.338) approaches. The best-performing multimodal model was applied to a held-out test set for external evaluation and achieved a mean squared error of 0.10805, demonstrating the potential of LLMs for psychometric analysis and automated item development.
Unlimited Road-scene Synthetic Annotation (URSA) Dataset
Jul 16, 2018
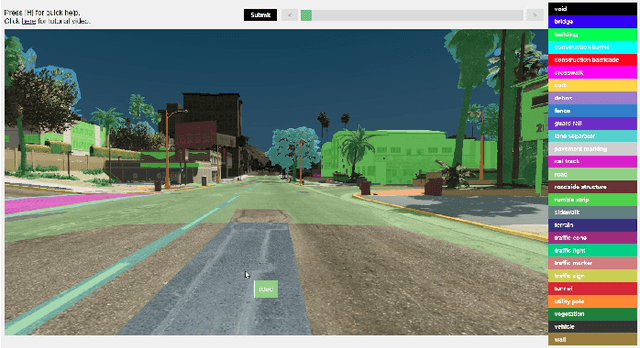

In training deep neural networks for semantic segmentation, the main limiting factor is the low amount of ground truth annotation data that is available in currently existing datasets. The limited availability of such data is due to the time cost and human effort required to accurately and consistently label real images on a pixel level. Modern sandbox video game engines provide open world environments where traffic and pedestrians behave in a pseudo-realistic manner. This caters well to the collection of a believable road-scene dataset. Utilizing open-source tools and resources found in single-player modding communities, we provide a method for persistent, ground truth, asset annotation of a game world. By collecting a synthetic dataset containing upwards of $1,000,000$ images, we demonstrate real-time, on-demand, ground truth data annotation capability of our method. Supplementing this synthetic data to Cityscapes dataset, we show that our data generation method provides qualitative as well as quantitative improvements---for training networks---over previous methods that use video games as surrogate.