 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Social Biases Using Templates is Unreliable
Oct 09, 2022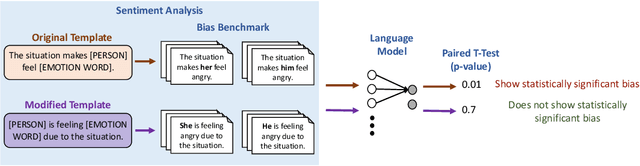

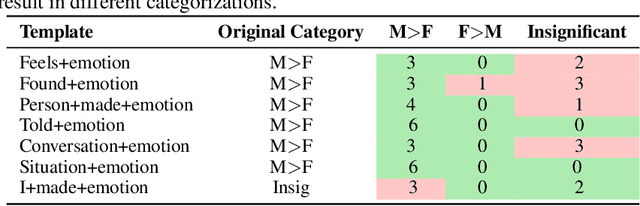

Recently, there has been an increase in efforts to understand how large language models (LLMs) propagate and amplify social biases. Several works have utilized templates for fairness evaluation, which allow researchers to quantify social biases in the absence of test sets with protected attribute labels. While template evaluation can be a convenient and helpful diagnostic tool to understand model deficiencies, it often uses a simplistic and limited set of templates. In this paper, we study whether bias measurements are sensitive to the choice of templates used for benchmarking. Specifically, we investigate the instability of bias measurements by manually modifying templates proposed in previous works in a semantically-preserving manner and measuring bias across these modifications. We find that bias values and resulting conclusions vary considerably across template modifications on four tasks, ranging from an 81% reduction (NLI) to a 162% increase (MLM) in (task-specific) bias measurements. Our results indicate that quantifying fairness in LLMs, as done in current practice, can be brittle and needs to be approached with more care and caution.
TalkToModel: Understanding Machine Learning Models With Open Ended Dialogues
Jul 08, 2022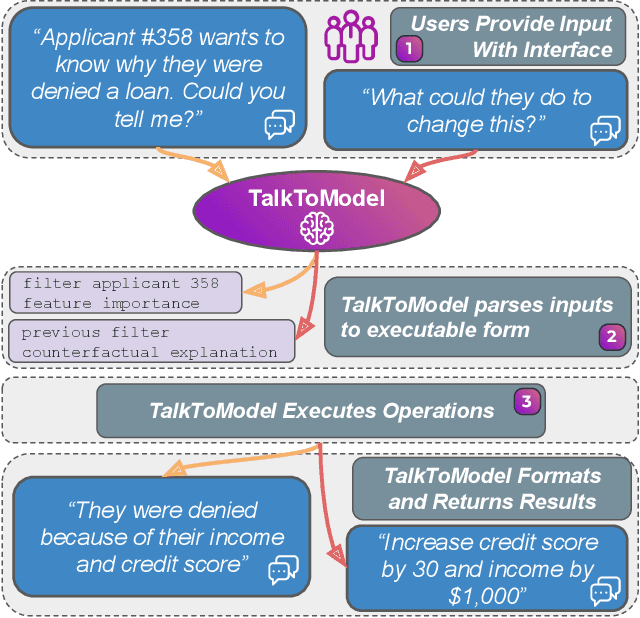



Machine Learning (ML) models are increasingly used to make critical decisions in real-world applications, yet they have also become more complex, making them harder to understand. To this end, several techniques to explain model predictions have been proposed. However, practitioners struggle to leverage explanations because they often do not know which to use, how to interpret the results, and may have insufficient data science experience to obtain explanations. In addition, most current works focus on generating one-shot explanations and do not allow users to follow up and ask fine-grained questions about the explanations, which can be frustrating. In this work, we address these challenges by introducing TalkToModel: an open-ended dialogue system for understanding machine learning models. Specifically, TalkToModel comprises three key components: 1) a natural language interface for engaging in dialogues, making understanding ML models highly accessible, 2) a dialogue engine that adapts to any tabular model and dataset, interprets natural language, maps it to appropriate operations (e.g., feature importance explanations, counterfactual explanations, showing model errors), and generates text responses, and 3) an execution component that run the operations and ensures explanations are accurate. We carried out quantitative and human subject evaluations of TalkToModel. We found the system understands user questions on novel datasets and models with high accuracy, demonstrating the system's capacity to generalize to new situations. In human evaluations, 73% of healthcare workers (e.g., doctors and nurses) agreed they would use TalkToModel over baseline point-and-click systems, and 84.6% of ML graduate students agreed TalkToModel was easier to use.
Learning to Query Internet Text for Informing Reinforcement Learning Agents
May 25, 2022
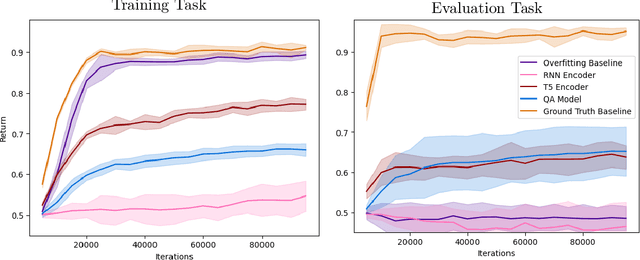

Generalization to out of distribution tasks in reinforcement learning is a challenging problem. One successful approach improves generalization by conditioning policies on task or environment descriptions that provide information about the current transition or reward functions. Previously, these descriptions were often expressed as generated or crowd sourced text. In this work, we begin to tackle the problem of extracting useful information from natural language found in the wild (e.g. internet forums, documentation, and wikis). These natural, pre-existing sources are especially challenging, noisy, and large and present novel challenges compared to previous approaches. We propose to address these challenges by training reinforcement learning agents to learn to query these sources as a human would, and we experiment with how and when an agent should query. To address the \textit{how}, we demonstrate that pretrained QA models perform well at executing zero-shot queries in our target domain. Using information retrieved by a QA model, we train an agent to learn \textit{when} it should execute queries. We show that our method correctly learns to execute queries to maximize reward in a reinforcement learning setting.
ReCLIP: A Strong Zero-Shot Baseline for Referring Expression Comprehension
Apr 12, 2022
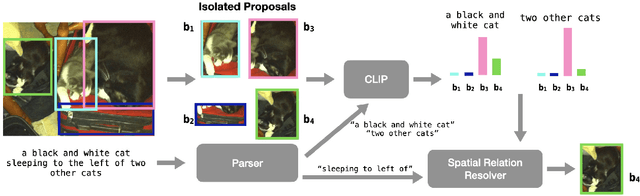
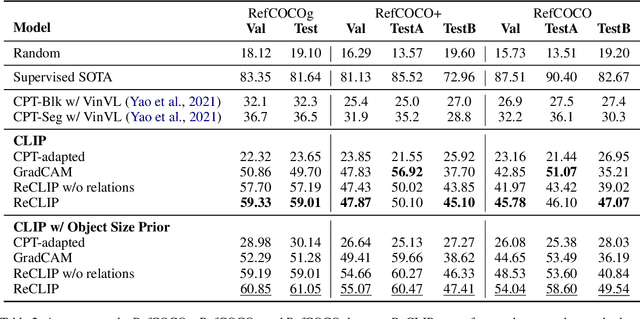
Training a referring expression comprehension (ReC) model for a new visual domain requires collecting referring expressions, and potentially corresponding bounding boxes, for images in the domain. While large-scale pre-trained models are useful for image classification across domains, it remains unclear if they can be applied in a zero-shot manner to more complex tasks like ReC. We present ReCLIP, a simple but strong zero-shot baseline that repurposes CLIP, a state-of-the-art large-scale model, for ReC. Motivated by the close connection between ReC and CLIP's contrastive pre-training objective, the first component of ReCLIP is a region-scoring method that isolates object proposals via cropping and blurring, and passes them to CLIP. However, through controlled experiments on a synthetic dataset, we find that CLIP is largely incapable of performing spatial reasoning off-the-shelf. Thus, the second component of ReCLIP is a spatial relation resolver that handles several types of spatial relations. We reduce the gap between zero-shot baselines from prior work and supervised models by as much as 29% on RefCOCOg, and on RefGTA (video game imagery), ReCLIP's relative improvement over supervised ReC models trained on real images is 8%.
Structurally Diverse Sampling Reduces Spurious Correlations in Semantic Parsing Datasets
Mar 16, 2022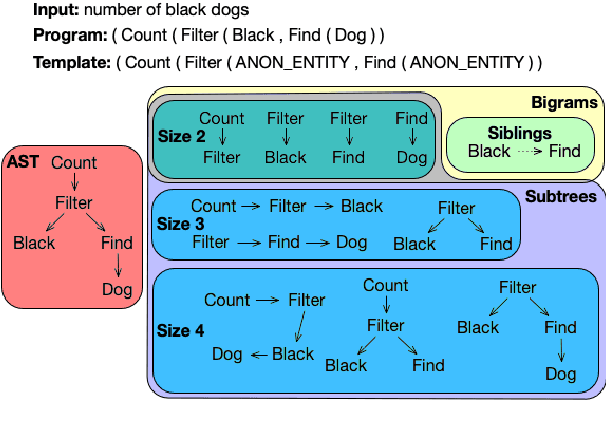
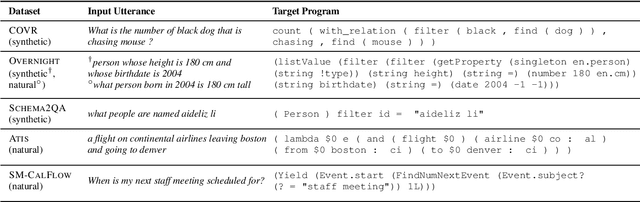
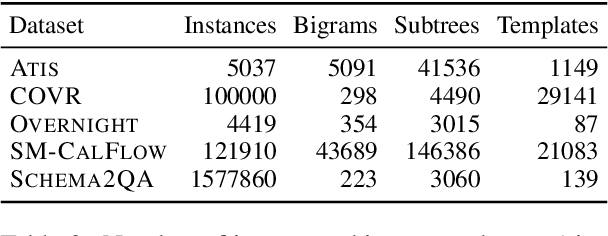
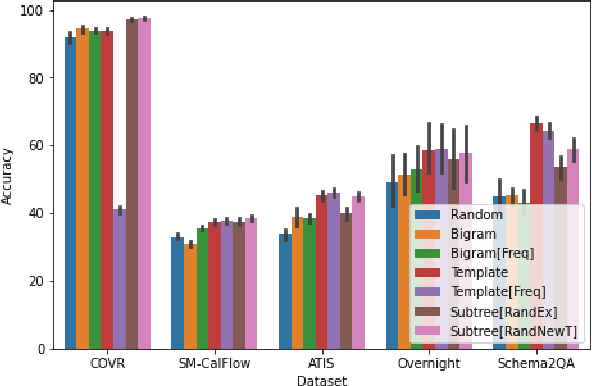
A rapidly growing body of research has demonstrated the inability of NLP models to generalize compositionally and has tried to alleviate it through specialized architectures, training schemes, and data augmentation, among other approaches. In this work, we study a different relatively under-explored approach: sampling diverse train sets that encourage compositional generalization. We propose a novel algorithm for sampling a structurally diverse set of instances from a labeled instance pool with structured outputs. Evaluating on 5 semantic parsing datasets of varying complexity, we show that our algorithm performs competitively with or better than prior algorithms in not only compositional template splits but also traditional IID splits of all but the least structurally diverse datasets. In general, we find that diverse train sets lead to better generalization than random training sets of the same size in 9 out of 10 dataset-split pairs, with over 10% absolute improvement in 5, providing further evidence to their sample efficiency. Moreover, we show that structural diversity also makes for more comprehensive test sets that require diverse training to succeed on. Finally, we use information theory to show that reduction in spurious correlations between substructures may be one reason why diverse training sets improve generalization.
Impact of Pretraining Term Frequencies on Few-Shot Reasoning
Feb 15, 2022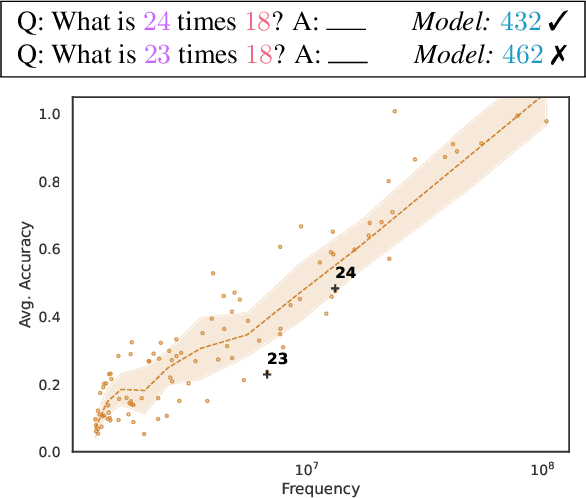



Pretrained Language Models (LMs) have demonstrated ability to perform numerical reasoning by extrapolating from a few examples in few-shot settings. However, the extent to which this extrapolation relies on robust reasoning is unclear. In this paper, we investigate how well these models reason with terms that are less frequent in the pretraining data. In particular, we examine the correlations between the model performance on test instances and the frequency of terms from those instances in the pretraining data. We measure the strength of this correlation for a number of GPT-based language models (pretrained on the Pile dataset) on various numerical deduction tasks (e.g., arithmetic and unit conversion). Our results consistently demonstrate that models are more accurate on instances whose terms are more prevalent, in some cases above $70\%$ (absolute) more accurate on the top 10\% frequent terms in comparison to the bottom 10\%. Overall, although LMs exhibit strong performance at few-shot numerical reasoning tasks, our results raise the question of how much models actually generalize beyond pretraining data, and we encourage researchers to take the pretraining data into account when interpreting evaluation results.
Rethinking Explainability as a Dialogue: A Practitioner's Perspective
Feb 03, 2022
As practitioners increasingly deploy machine learning models in critical domains such as health care, finance, and policy, it becomes vital to ensure that domain experts function effectively alongside these models. Explainability is one way to bridge the gap between human decision-makers and machine learning models. However, most of the existing work on explainability focuses on one-off, static explanations like feature importances or rule lists. These sorts of explanations may not be sufficient for many use cases that require dynamic, continuous discovery from stakeholders. In the literature, few works ask decision-makers about the utility of existing explanations and other desiderata they would like to see in an explanation going forward. In this work, we address this gap and carry out a study where we interview doctors, healthcare professionals, and policymakers about their needs and desires for explanations. Our study indicates that decision-makers would strongly prefer interactive explanations in the form of natural language dialogues. Domain experts wish to treat machine learning models as "another colleague", i.e., one who can be held accountable by asking why they made a particular decision through expressive and accessible natural language interactions. Considering these needs, we outline a set of five principles researchers should follow when designing interactive explanations as a starting place for future work. Further, we show why natural language dialogues satisfy these principles and are a desirable way to build interactive explanations. Next, we provide a design of a dialogue system for explainability and discuss the risks, trade-offs, and research opportunities of building these systems. Overall, we hope our work serves as a starting place for researchers and engineers to design interactive explainability systems.
Identifying Adversarial Attacks on Text Classifiers
Jan 21, 2022

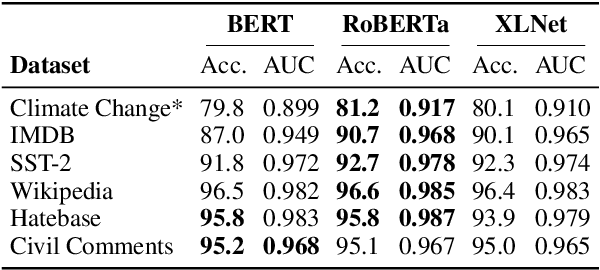
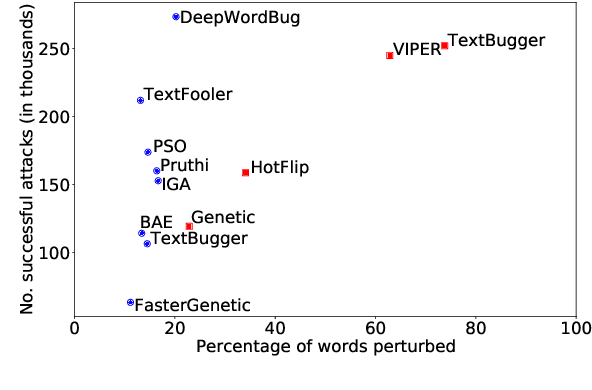
The landscape of adversarial attacks against text classifiers continues to grow, with new attacks developed every year and many of them available in standard toolkits, such as TextAttack and OpenAttack. In response, there is a growing body of work on robust learning, which reduces vulnerability to these attacks, though sometimes at a high cost in compute time or accuracy. In this paper, we take an alternate approach -- we attempt to understand the attacker by analyzing adversarial text to determine which methods were used to create it. Our first contribution is an extensive dataset for attack detection and labeling: 1.5~million attack instances, generated by twelve adversarial attacks targeting three classifiers trained on six source datasets for sentiment analysis and abuse detection in English. As our second contribution, we use this dataset to develop and benchmark a number of classifiers for attack identification -- determining if a given text has been adversarially manipulated and by which attack. As a third contribution, we demonstrate the effectiveness of three classes of features for these tasks: text properties, capturing content and presentation of text; language model properties, determining which tokens are more or less probable throughout the input; and target model properties, representing how the text classifier is influenced by the attack, including internal node activations. Overall, this represents a first step towards forensics for adversarial attacks against text classifiers.
BottleFit: Learning Compressed Representations in Deep Neural Networks for Effective and Efficient Split Computing
Jan 07, 2022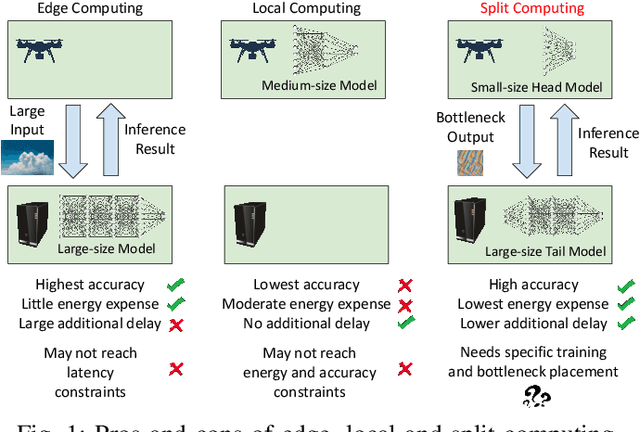
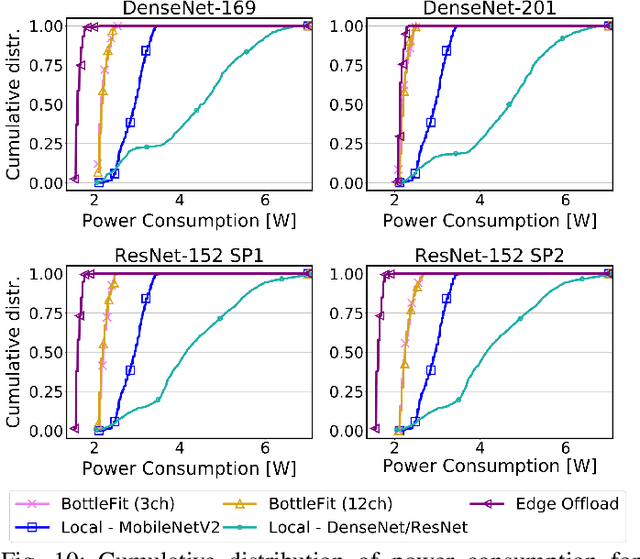
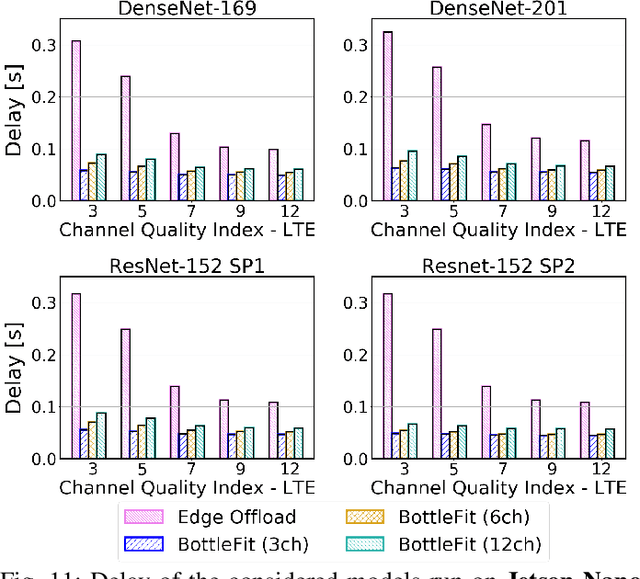
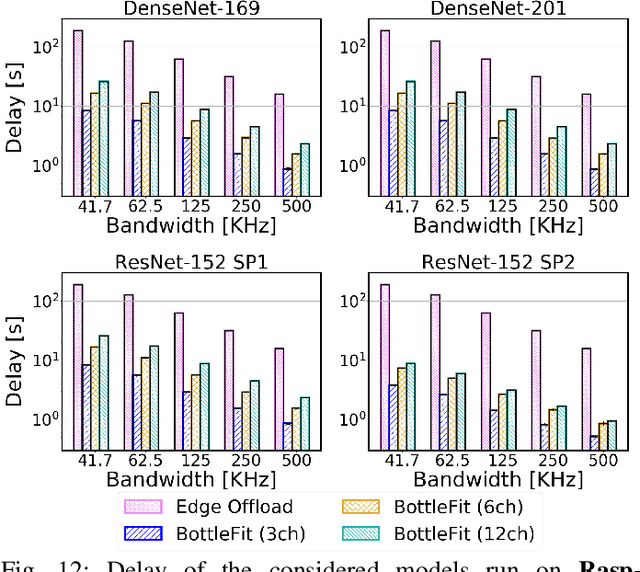
Although mission-critical applications require the use of deep neural networks (DNNs), their continuous execution at mobile devices results in a significant increase in energy consumption. While edge offloading can decrease energy consumption, erratic patterns in channel quality, network and edge server load can lead to severe disruption of the system's key operations. An alternative approach, called split computing, generates compressed representations within the model (called "bottlenecks"), to reduce bandwidth usage and energy consumption. Prior work has proposed approaches that introduce additional layers, to the detriment of energy consumption and latency. For this reason, we propose a new framework called BottleFit, which, in addition to targeted DNN architecture modifications, includes a novel training strategy to achieve high accuracy even with strong compression rates. We apply BottleFit on cutting-edge DNN models in image classification, and show that BottleFit achieves 77.1% data compression with up to 0.6% accuracy loss on ImageNet dataset, while state of the art such as SPINN loses up to 6% in accuracy. We experimentally measure the power consumption and latency of an image classification application running on an NVIDIA Jetson Nano board (GPU-based) and a Raspberry PI board (GPU-less). We show that BottleFit decreases power consumption and latency respectively by up to 49% and 89% with respect to (w.r.t.) local computing and by 37% and 55% w.r.t. edge offloading. We also compare BottleFit with state-of-the-art autoencoders-based approaches, and show that (i) BottleFit reduces power consumption and execution time respectively by up to 54% and 44% on the Jetson and 40% and 62% on Raspberry PI; (ii) the size of the head model executed on the mobile device is 83 times smaller. The code repository will be published for full reproducibility of the results.
FRUIT: Faithfully Reflecting Updated Information in Text
Dec 16, 2021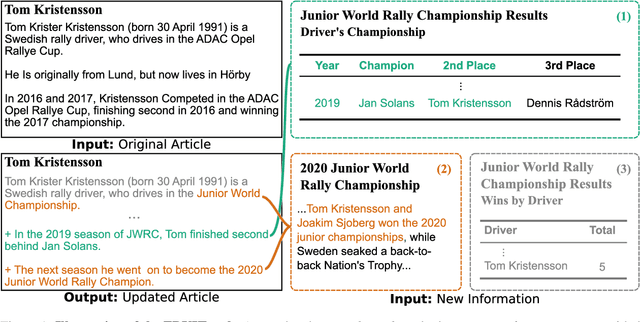
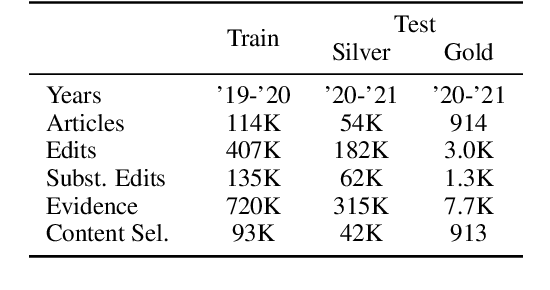

Textual knowledge bases such as Wikipedia require considerable effort to keep up to date and consistent. While automated writing assistants could potentially ease this burden, the problem of suggesting edits grounded in external knowledge has been under-explored. In this paper, we introduce the novel generation task of *faithfully reflecting updated information in text*(FRUIT) where the goal is to update an existing article given new evidence. We release the FRUIT-WIKI dataset, a collection of over 170K distantly supervised data produced from pairs of Wikipedia snapshots, along with our data generation pipeline and a gold evaluation set of 914 instances whose edits are guaranteed to be supported by the evidence. We provide benchmark results for popular generation systems as well as EDIT5 -- a T5-based approach tailored to editing we introduce that establishes the state of the art. Our analysis shows that developing models that can update articles faithfully requires new capabilities for neural generation models, and opens doors to many new applications.