 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCP-Diag: A Deterministic, Protocol-Driven Architecture for AI-Native Network Diagnostics
Jan 30, 2026The integration of Large Language Models (LLMs) into network operations (AIOps) is hindered by two fundamental challenges: the stochastic grounding problem, where LLMs struggle to reliably parse unstructured, vendor-specific CLI output, and the security gap of granting autonomous agents shell access. This paper introduces MCP-Diag, a hybrid neuro-symbolic architecture built upon the Model Context Protocol (MCP). We propose a deterministic translation layer that converts raw stdout from canonical utilities (dig, ping, traceroute) into rigorous JSON schemas before AI ingestion. We further introduce a mandatory "Elicitation Loop" that enforces Human-in-the-Loop (HITL) authorization at the protocol level. Our preliminary evaluation demonstrates that MCP-Diag achieving 100% entity extraction accuracy with less than 0.9% execution latency overhead and 3.7x increase in context token usage.
Leveraging eBPF and AI for Ransomware Nose Out
Jun 20, 2024In this work, we propose a two-phased approach for real-time detection and deterrence of ransomware. To achieve this, we leverage the capabilities of eBPF (Extended Berkeley Packet Filter) and artificial intelligence to develop both proactive and reactive methods. In the first phase, we utilize signature based detection, where we employ custom eBPF programs to trace the execution of new processes and perform hash-based analysis against a known ransomware dataset. In the second, we employ a behavior-based technique that focuses on monitoring the process activities using a custom eBPF program and the creation of ransom notes, a prominent indicator of ransomware activity through the use of Natural Language Processing (NLP). By leveraging low-level tracing capabilities of eBPF and integrating NLP based machine learning algorithms, our solution achieves an impressive 99.76% accuracy in identifying ransomware incidents within a few seconds on the onset of zero-day attacks.
Spatial Sharing of GPU for Autotuning DNN models
Aug 08, 2020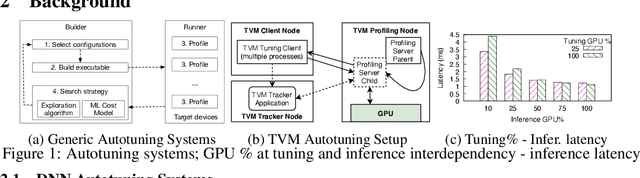
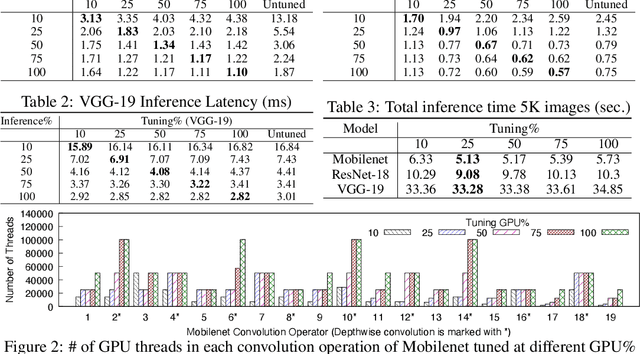
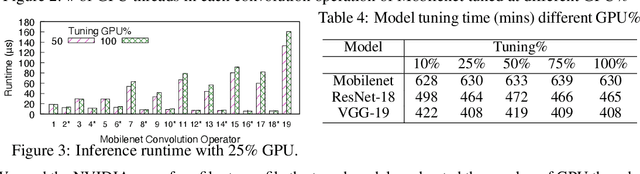
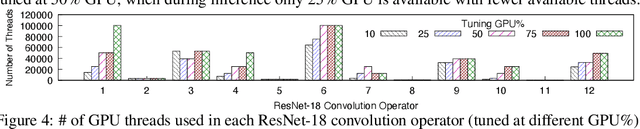
GPUs are used for training, inference, and tuning the machine learning models. However, Deep Neural Network (DNN) vary widely in their ability to exploit the full power of high-performance GPUs. Spatial sharing of GPU enables multiplexing several DNNs on the GPU and can improve GPU utilization, thus improving throughput and lowering latency. DNN models given just the right amount of GPU resources can still provide low inference latency, just as much as dedicating all of the GPU for their inference task. An approach to improve DNN inference is tuning of the DNN model. Autotuning frameworks find the optimal low-level implementation for a certain target device based on the trained machine learning model, thus reducing the DNN's inference latency and increasing inference throughput. We observe an interdependency between the tuned model and its inference latency. A DNN model tuned with specific GPU resources provides the best inference latency when inferred with close to the same amount of GPU resources. While a model tuned with the maximum amount of the GPU's resources has poorer inference latency once the GPU resources are limited for inference. On the other hand, a model tuned with an appropriate amount of GPU resources still achieves good inference latency across a wide range of GPU resource availability. We explore the causes that impact the tuning of a model at different amounts of GPU resources. We present many techniques to maximize resource utilization and improve tuning performance. We enable controlled spatial sharing of GPU to multiplex several tuning applications on the GPU. We scale the tuning server instances and shard the tuning model across multiple client instances for concurrent tuning of different operators of a model, achieving better GPU multiplexing. With our improvements, we decrease DNN autotuning time by up to 75 percent and increase throughput by a factor of 5.