 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaking MoE-based LLM Inference Resilient with Tarragon
Jan 06, 2026Mixture-of-Experts (MoE) models are increasingly used to serve LLMs at scale, but failures become common as deployment scale grows. Existing systems exhibit poor failure resilience: even a single worker failure triggers a coarse-grained, service-wide restart, discarding accumulated progress and halting the entire inference pipeline during recovery--an approach clearly ill-suited for latency-sensitive, LLM services. We present Tarragon, a resilient MoE inference framework that confines the failures impact to individual workers while allowing the rest of the pipeline to continue making forward progress. Tarragon exploits the natural separation between the attention and expert computation in MoE-based transformers, treating attention workers (AWs) and expert workers (EWs) as distinct failure domains. Tarragon introduces a reconfigurable datapath to mask failures by rerouting requests to healthy workers. On top of this datapath, Tarragon implements a self-healing mechanism that relaxes the tightly synchronized execution of existing MoE frameworks. For stateful AWs, Tarragon performs asynchronous, incremental KV cache checkpointing with per-request restoration, and for stateless EWs, it leverages residual GPU memory to deploy shadow experts. These together keep recovery cost and recomputation overhead extremely low. Our evaluation shows that, compared to state-of-the-art MegaScale-Infer, Tarragon reduces failure-induced stalls by 160-213x (from ~64 s down to 0.3-0.4 s) while preserving performance when no failures occur.
Spatial Sharing of GPU for Autotuning DNN models
Aug 08, 2020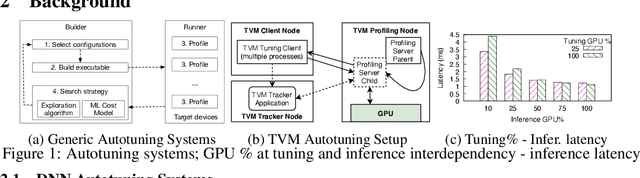
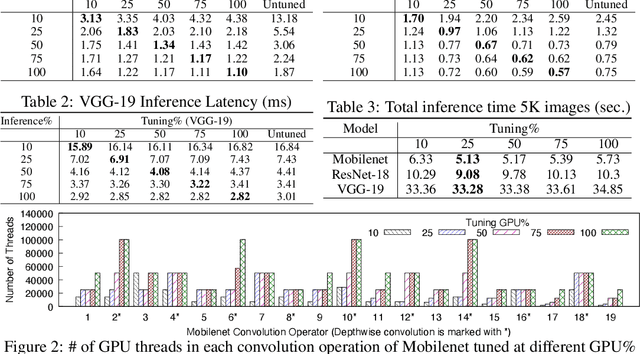
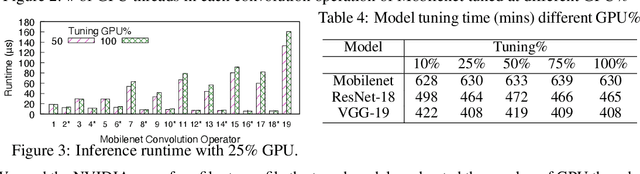
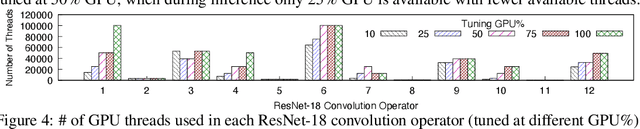
GPUs are used for training, inference, and tuning the machine learning models. However, Deep Neural Network (DNN) vary widely in their ability to exploit the full power of high-performance GPUs. Spatial sharing of GPU enables multiplexing several DNNs on the GPU and can improve GPU utilization, thus improving throughput and lowering latency. DNN models given just the right amount of GPU resources can still provide low inference latency, just as much as dedicating all of the GPU for their inference task. An approach to improve DNN inference is tuning of the DNN model. Autotuning frameworks find the optimal low-level implementation for a certain target device based on the trained machine learning model, thus reducing the DNN's inference latency and increasing inference throughput. We observe an interdependency between the tuned model and its inference latency. A DNN model tuned with specific GPU resources provides the best inference latency when inferred with close to the same amount of GPU resources. While a model tuned with the maximum amount of the GPU's resources has poorer inference latency once the GPU resources are limited for inference. On the other hand, a model tuned with an appropriate amount of GPU resources still achieves good inference latency across a wide range of GPU resource availability. We explore the causes that impact the tuning of a model at different amounts of GPU resources. We present many techniques to maximize resource utilization and improve tuning performance. We enable controlled spatial sharing of GPU to multiplex several tuning applications on the GPU. We scale the tuning server instances and shard the tuning model across multiple client instances for concurrent tuning of different operators of a model, achieving better GPU multiplexing. With our improvements, we decrease DNN autotuning time by up to 75 percent and increase throughput by a factor of 5.