 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSummScreen: A Dataset for Abstractive Screenplay Summarization
Apr 14, 2021
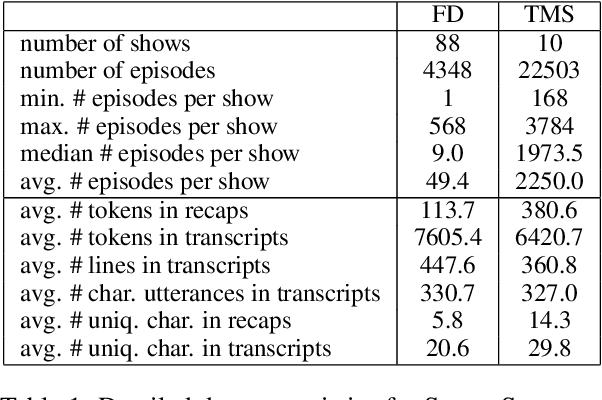
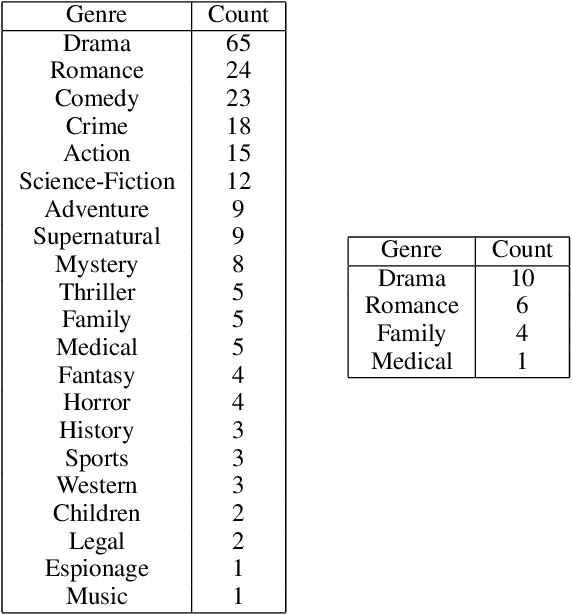
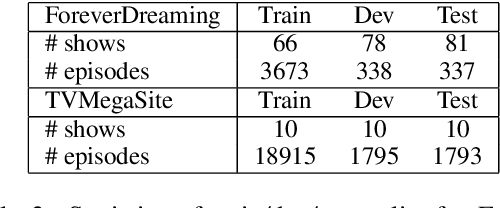
We introduce SummScreen, a summarization dataset comprised of pairs of TV series transcripts and human written recaps. The dataset provides a challenging testbed for abstractive summarization for several reasons. Plot details are often expressed indirectly in character dialogues and may be scattered across the entirety of the transcript. These details must be found and integrated to form the succinct plot descriptions in the recaps. Also, TV scripts contain content that does not directly pertain to the central plot but rather serves to develop characters or provide comic relief. This information is rarely contained in recaps. Since characters are fundamental to TV series, we also propose two entity-centric evaluation metrics. Empirically, we characterize the dataset by evaluating several methods, including neural models and those based on nearest neighbors. An oracle extractive approach outperforms all benchmarked models according to automatic metrics, showing that the neural models are unable to fully exploit the input transcripts. Human evaluation and qualitative analysis reveal that our non-oracle models are competitive with their oracle counterparts in terms of generating faithful plot events and can benefit from better content selectors. Both oracle and non-oracle models generate unfaithful facts, suggesting future research directions.
Learning Chess Blindfolded: Evaluating Language Models on State Tracking
Feb 26, 2021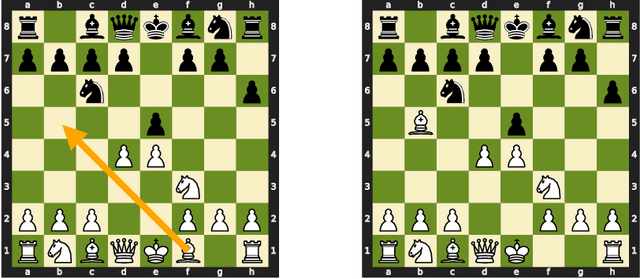


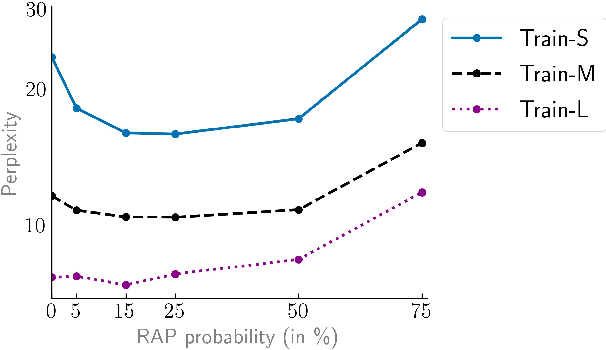
Transformer language models have made tremendous strides in natural language understanding tasks. However, the complexity of natural language makes it challenging to ascertain how accurately these models are tracking the world state underlying the text. Motivated by this issue, we consider the task of language modeling for the game of chess. Unlike natural language, chess notations describe a simple, constrained, and deterministic domain. Moreover, we observe that the appropriate choice of chess notation allows for directly probing the world state, without requiring any additional probing-related machinery. We find that: (a) With enough training data, transformer language models can learn to track pieces and predict legal moves with high accuracy when trained solely on move sequences. (b) For small training sets providing access to board state information during training can yield significant improvements. (c) The success of transformer language models is dependent on access to the entire game history i.e. "full attention". Approximating this full attention results in a significant performance drop. We propose this testbed as a benchmark for future work on the development and analysis of transformer language models.
Generating (Formulaic) Text by Splicing Together Nearest Neighbors
Jan 29, 2021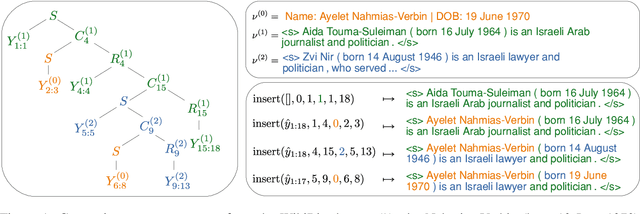
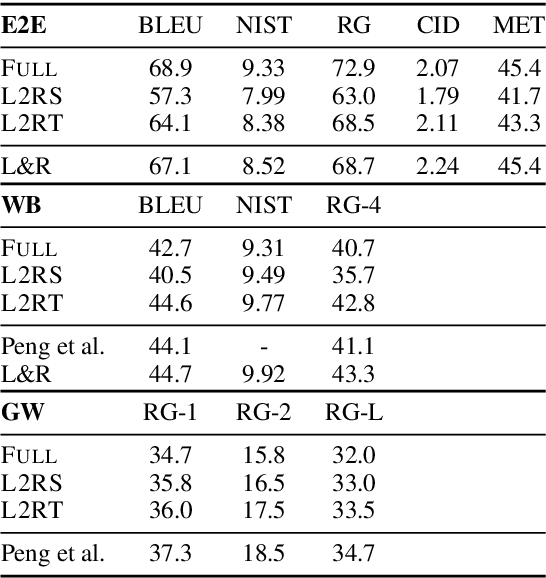
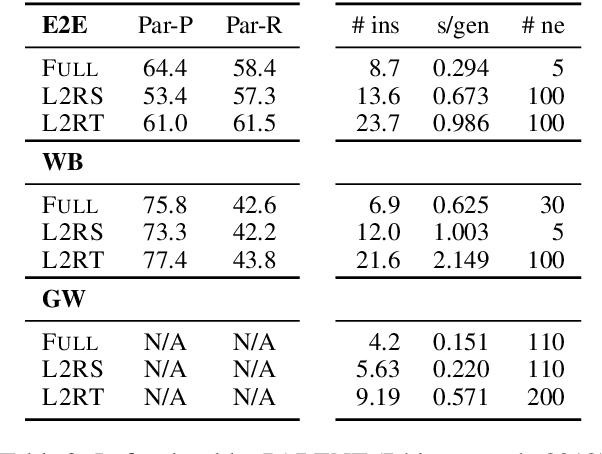
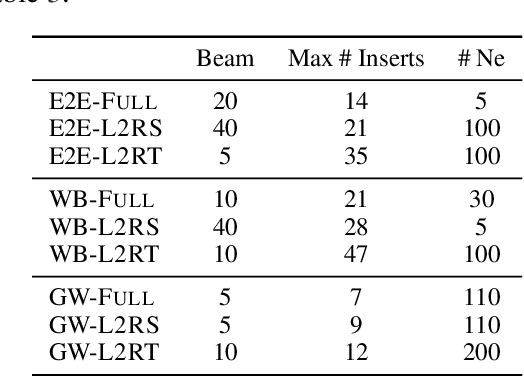
We propose to tackle conditional text generation tasks, especially those which require generating formulaic text, by splicing together segments of text from retrieved "neighbor" source-target pairs. Unlike recent work that conditions on retrieved neighbors in an encoder-decoder setting but generates text token-by-token, left-to-right, we learn a policy that directly manipulates segments of neighbor text (i.e., by inserting or replacing them) to form an output. Standard techniques for training such a policy require an oracle derivation for each generation, and we prove that finding the shortest such derivation can be reduced to parsing under a particular weighted context-free grammar. We find that policies learned in this way allow for interpretable table-to-text or headline generation that is competitive with neighbor-based token-level policies on automatic metrics, though on all but one dataset neighbor-based policies underperform a strong neighborless baseline. In all cases, however, generating by splicing is faster.
Generating Wikipedia Article Sections from Diverse Data Sources
Dec 29, 2020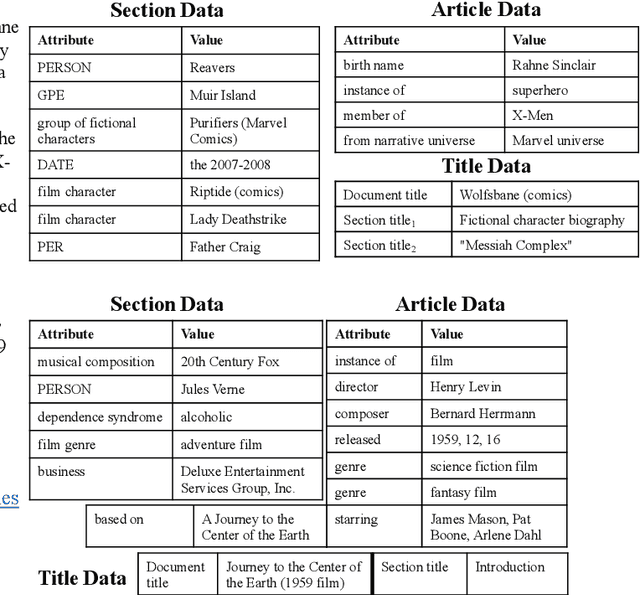
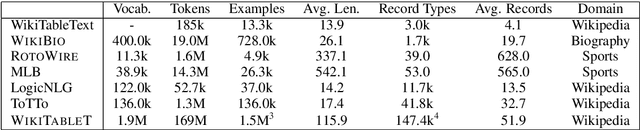

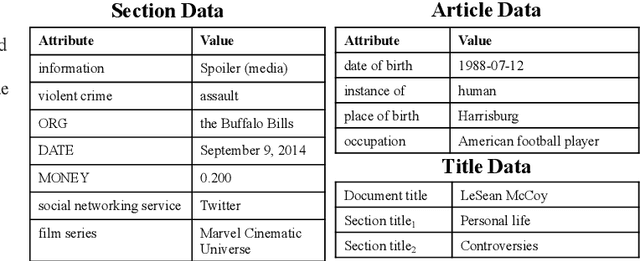
Datasets for data-to-text generation typically focus either on multi-domain, single-sentence generation or on single-domain, long-form generation. In this work, we create a large-scale dataset, WikiTableT, that pairs Wikipedia sections with their corresponding tabular data and various metadata. WikiTableT contains millions of instances, covering a broad range of topics, as well as a variety of flavors of generation tasks with different levels of flexibility. We benchmark several training and decoding strategies on WikiTableT. Our qualitative analysis shows that the best approaches can generate fluent and high quality texts but they sometimes struggle with coherence.
Controllable Paraphrasing and Translation with a Syntactic Exemplar
Oct 12, 2020
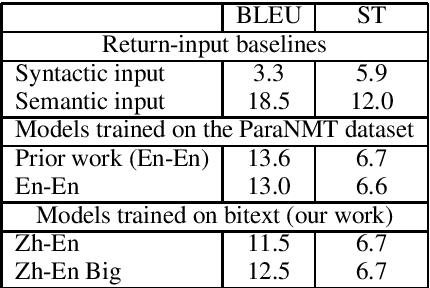

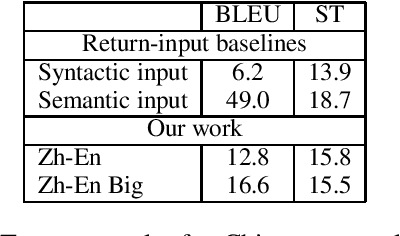
Most prior work on exemplar-based syntactically controlled paraphrase generation relies on automatically-constructed large-scale paraphrase datasets. We sidestep this prerequisite by adapting models from prior work to be able to learn solely from bilingual text (bitext). Despite only using bitext for training, and in near zero-shot conditions, our single proposed model can perform four tasks: controlled paraphrase generation in both languages and controlled machine translation in both language directions. To evaluate these tasks quantitatively, we create three novel evaluation datasets. Our experimental results show that our models achieve competitive results on controlled paraphrase generation and strong performance on controlled machine translation. Analysis shows that our models learn to disentangle semantics and syntax in their latent representations.
Learning to Ignore: Long Document Coreference with Bounded Memory Neural Networks
Oct 06, 2020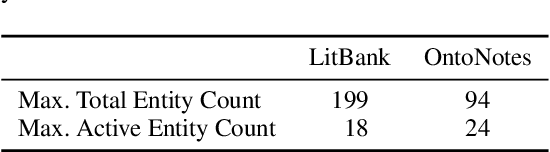
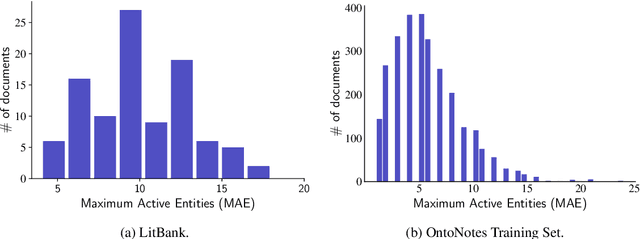
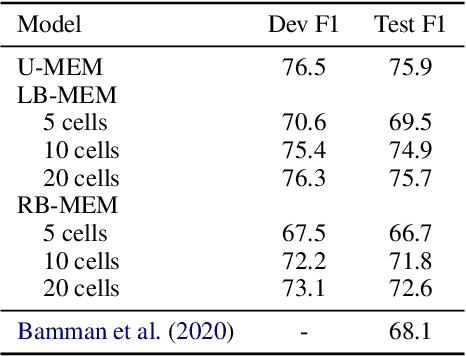
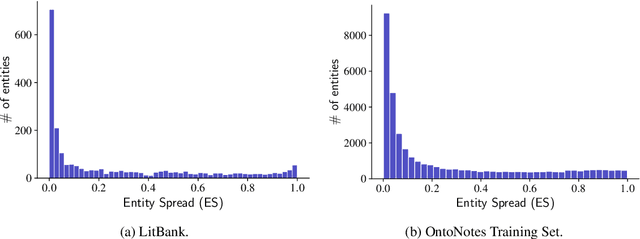
Long document coreference resolution remains a challenging task due to the large memory and runtime requirements of current models. Recent work doing incremental coreference resolution using just the global representation of entities shows practical benefits but requires keeping all entities in memory, which can be impractical for long documents. We argue that keeping all entities in memory is unnecessary, and we propose a memory-augmented neural network that tracks only a small bounded number of entities at a time, thus guaranteeing a linear runtime in length of document. We show that (a) the model remains competitive with models with high memory and computational requirements on OntoNotes and LitBank, and (b) the model learns an efficient memory management strategy easily outperforming a rule-based strategy.
Discrete Latent Variable Representations for Low-Resource Text Classification
Jun 11, 2020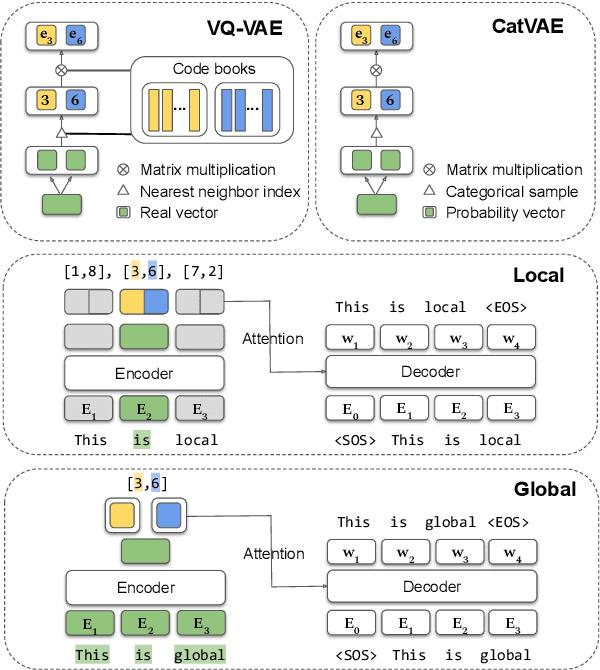
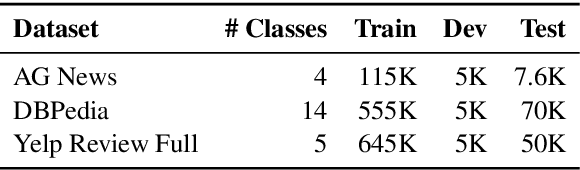
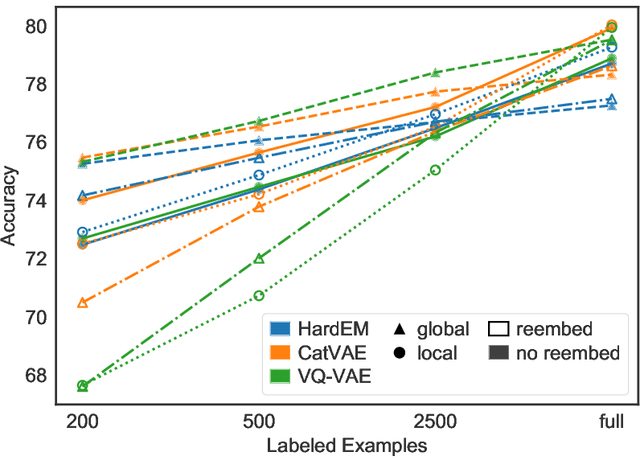
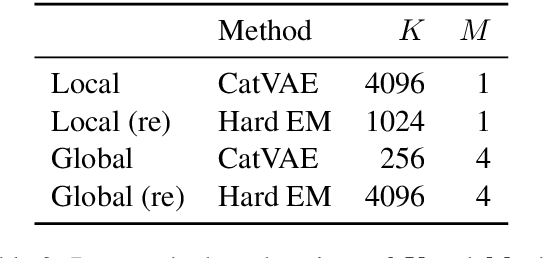
While much work on deep latent variable models of text uses continuous latent variables, discrete latent variables are interesting because they are more interpretable and typically more space efficient. We consider several approaches to learning discrete latent variable models for text in the case where exact marginalization over these variables is intractable. We compare the performance of the learned representations as features for low-resource document and sentence classification. Our best models outperform the previous best reported results with continuous representations in these low-resource settings, while learning significantly more compressed representations. Interestingly, we find that an amortized variant of Hard EM performs particularly well in the lowest-resource regimes.
ENGINE: Energy-Based Inference Networks for Non-Autoregressive Machine Translation
May 12, 2020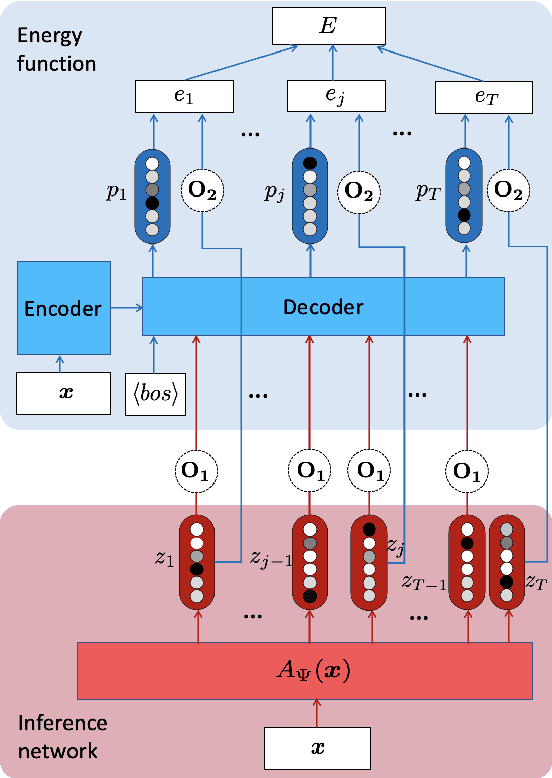
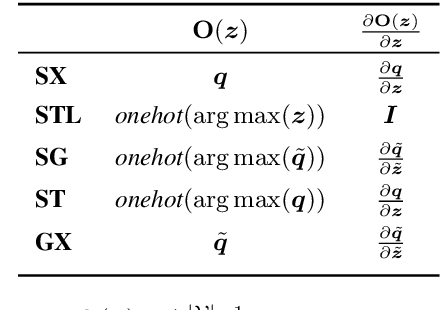

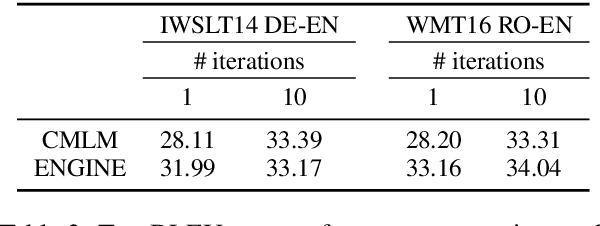
We propose to train a non-autoregressive machine translation model to minimize the energy defined by a pretrained autoregressive model. In particular, we view our non-autoregressive translation system as an inference network (Tu and Gimpel, 2018) trained to minimize the autoregressive teacher energy. This contrasts with the popular approach of training a non-autoregressive model on a distilled corpus consisting of the beam-searched outputs of such a teacher model. Our approach, which we call ENGINE (ENerGy-based Inference NEtworks), achieves state-of-the-art non-autoregressive results on the IWSLT 2014 DE-EN and WMT 2016 RO-EN datasets, approaching the performance of autoregressive models.
Learning Discrete Structured Representations by Adversarially Maximizing Mutual Information
Apr 08, 2020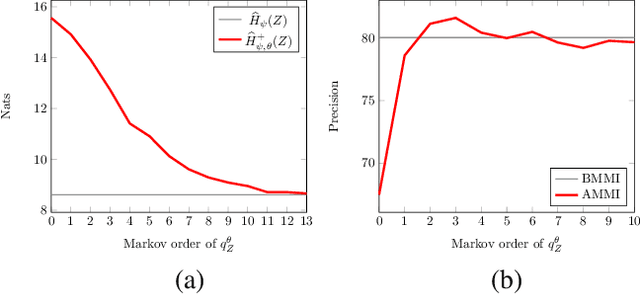
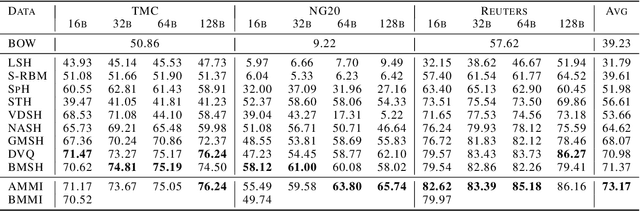

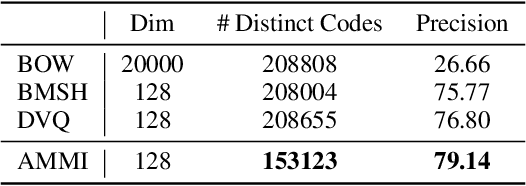
We propose learning discrete structured representations from unlabeled data by maximizing the mutual information between a structured latent variable and a target variable. Calculating mutual information is intractable in this setting. Our key technical contribution is an adversarial objective that can be used to tractably estimate mutual information assuming only the feasibility of cross entropy calculation. We develop a concrete realization of this general formulation with Markov distributions over binary encodings. We report critical and unexpected findings on practical aspects of the objective such as the choice of variational priors. We apply our model on document hashing and show that it outperforms current best baselines based on discrete and vector quantized variational autoencoders. It also yields highly compressed interpretable representations.
Amortized Bethe Free Energy Minimization for Learning MRFs
Jun 14, 2019

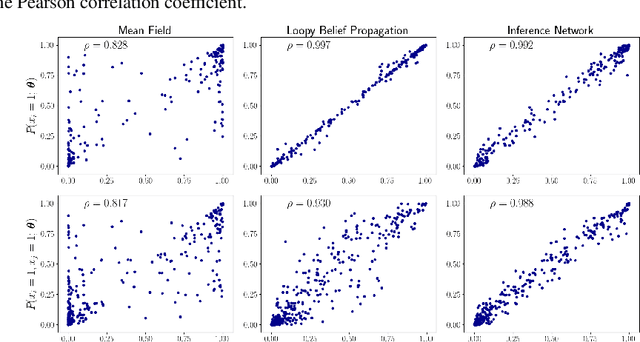

We propose to learn deep undirected graphical models (i.e., MRFs), with a non-ELBO objective for which we can calculate exact gradients. In particular, we optimize a saddle-point objective deriving from the Bethe free energy approximation to the partition function. Unlike much recent work in approximate inference, the derived objective requires no sampling, and can be efficiently computed even for very expressive MRFs. We furthermore amortize this optimization with trained inference networks. Experimentally, we find that the proposed approach compares favorably with loopy belief propagation, but is faster, and it allows for attaining better held out log likelihood than other recent approximate inference schemes.