 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Evaluation of Deep Learning Model Compression Techniques on the WaveNet Vocoder
Nov 20, 2020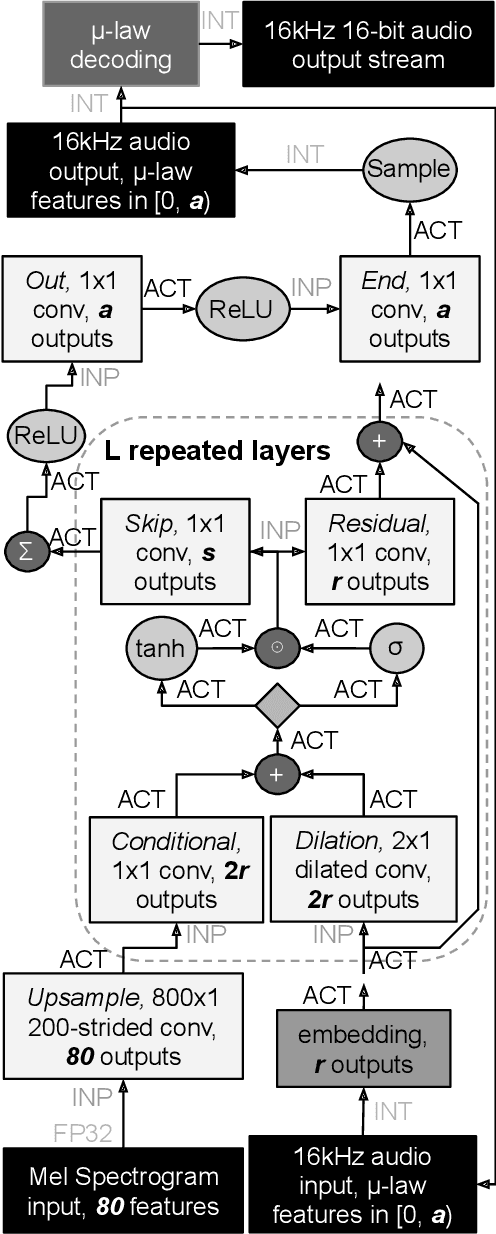
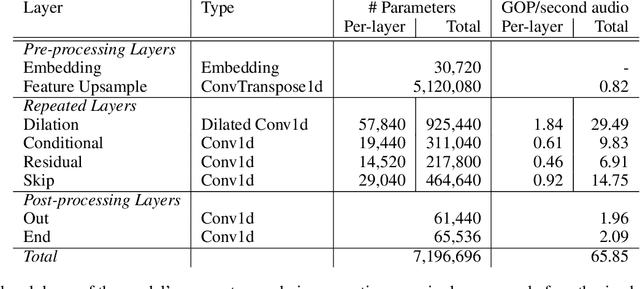
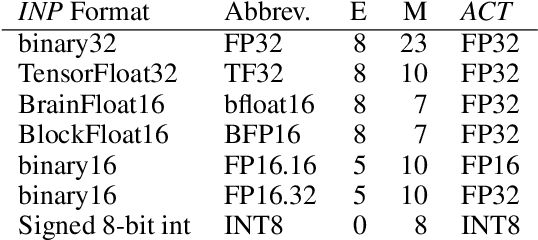
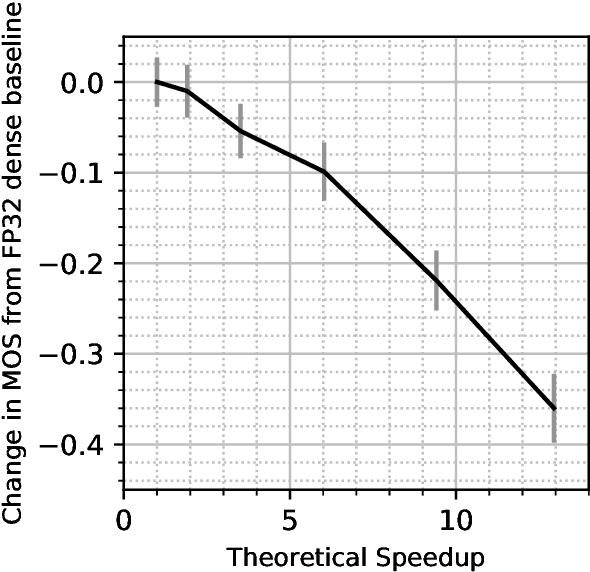
WaveNet is a state-of-the-art text-to-speech vocoder that remains challenging to deploy due to its autoregressive loop. In this work we focus on ways to accelerate the original WaveNet architecture directly, as opposed to modifying the architecture, such that the model can be deployed as part of a scalable text-to-speech system. We survey a wide variety of model compression techniques that are amenable to deployment on a range of hardware platforms. In particular, we compare different model sparsity methods and levels, and seven widely used precisions as targets for quantization; and are able to achieve models with a compression ratio of up to 13.84 without loss in audio fidelity compared to a dense, single-precision floating-point baseline. All techniques are implemented using existing open source deep learning frameworks and libraries to encourage their wider adoption.
MLPerf Inference Benchmark
Nov 06, 2019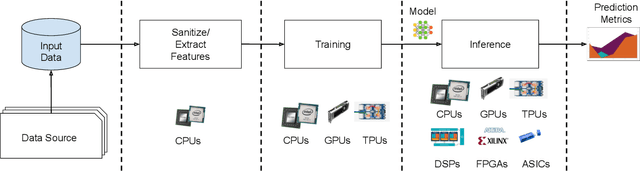
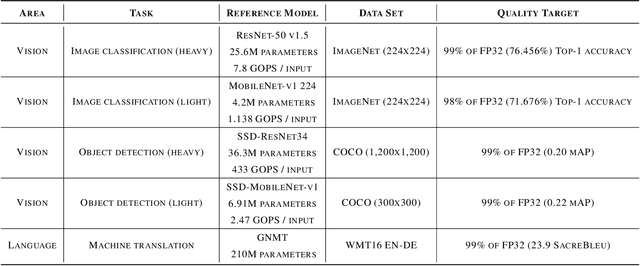
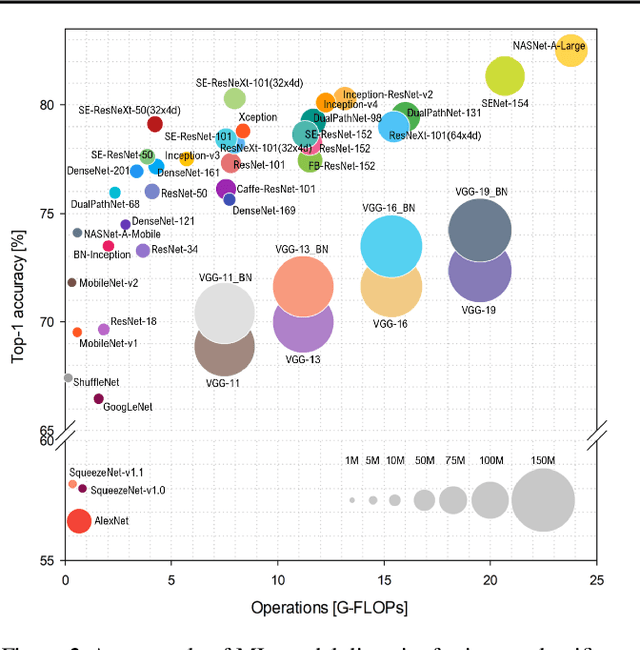
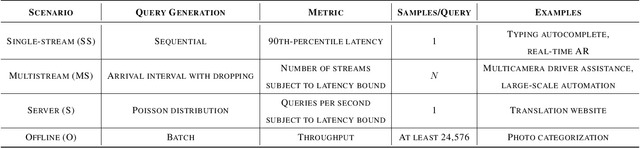
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.