 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Consistent Endoscopic Representations for Image-Guided Navigation via Structured Foundation Model Adaptation
Jun 15, 2026Accurate vision-based navigation in monocular endoscopy is difficult due to limited depth cues, weak tissue texture, non-rigid deformation, and substantial appearance variation across domains, all of which complicate pose estimation, depth prediction, and image-to-anatomy alignment. Although recent vision foundation models have shown promise, their learned representations often remain insufficiently geometry-consistent, hindering stable feature correspondence and limiting their reliability for downstream navigation tasks. We propose a unified framework for learning geometry-consistent and domain-robust image representations for monocular endoscopy. The framework combines a synthetic data pipeline that provides accurate geometric supervision with Hierarchy-Aware Geometry-Semantic Adaptation, a structured alternative to standard LoRA that inserts low-rank adapters selectively across the transformer hierarchy and couples them with layer-wise training objectives to encourage geometric correspondence in intermediate features and semantic consistency in deeper features. Experiments on public and proprietary datasets show improved geometric and semantic representation quality, leading to better performance on downstream navigation tasks including pose estimation and monocular depth estimation. The learned representations show favorable synthetic-to-real transfer on clinical bronchoscopy and provide a useful initialization for adaptation to sinus endoscopy and colonoscopy under limited supervision. The framework also shows favorable scaling with model size and training data. These results support hierarchy-aware, geometry-guided adaptation as a practical approach for endoscopic representation learning.
BronchOpt : Vision-Based Pose Optimization with Fine-Tuned Foundation Models for Accurate Bronchoscopy Navigation
Nov 12, 2025



Accurate intra-operative localization of the bronchoscope tip relative to patient anatomy remains challenging due to respiratory motion, anatomical variability, and CT-to-body divergence that cause deformation and misalignment between intra-operative views and pre-operative CT. Existing vision-based methods often fail to generalize across domains and patients, leading to residual alignment errors. This work establishes a generalizable foundation for bronchoscopy navigation through a robust vision-based framework and a new synthetic benchmark dataset that enables standardized and reproducible evaluation. We propose a vision-based pose optimization framework for frame-wise 2D-3D registration between intra-operative endoscopic views and pre-operative CT anatomy. A fine-tuned modality- and domain-invariant encoder enables direct similarity computation between real endoscopic RGB frames and CT-rendered depth maps, while a differentiable rendering module iteratively refines camera poses through depth consistency. To enhance reproducibility, we introduce the first public synthetic benchmark dataset for bronchoscopy navigation, addressing the lack of paired CT-endoscopy data. Trained exclusively on synthetic data distinct from the benchmark, our model achieves an average translational error of 2.65 mm and a rotational error of 0.19 rad, demonstrating accurate and stable localization. Qualitative results on real patient data further confirm strong cross-domain generalization, achieving consistent frame-wise 2D-3D alignment without domain-specific adaptation. Overall, the proposed framework achieves robust, domain-invariant localization through iterative vision-based optimization, while the new benchmark provides a foundation for standardized progress in vision-based bronchoscopy navigation.
Deep Feature Tracker: A Novel Application for Deep Convolutional Neural Networks
Jul 30, 2021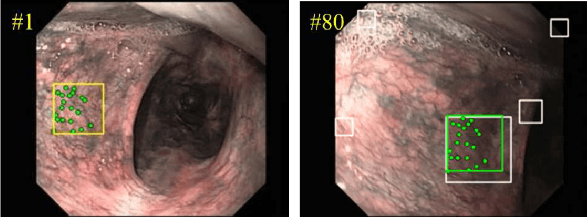

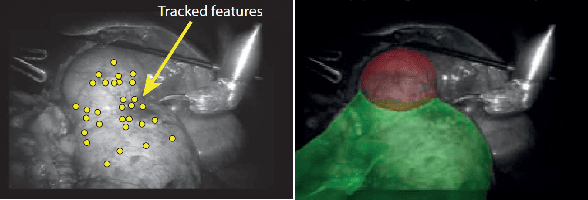

Feature tracking is the building block of many applications such as visual odometry, augmented reality, and target tracking. Unfortunately, the state-of-the-art vision-based tracking algorithms fail in surgical images due to the challenges imposed by the nature of such environments. In this paper, we proposed a novel and unified deep learning-based approach that can learn how to track features reliably as well as learn how to detect such reliable features for tracking purposes. The proposed network dubbed as Deep-PT, consists of a tracker network which is a convolutional neural network simulating cross-correlation in terms of deep learning and two fully connected networks that operate on the output of intermediate layers of the tracker to detect features and predict trackability of the detected points. The ability to detect features based on the capabilities of the tracker distinguishes the proposed method from previous algorithms used in this area and improves the robustness of the algorithms against dynamics of the scene. The network is trained using multiple datasets due to the lack of specialized dataset for feature tracking datasets and extensive comparisons are conducted to compare the accuracy of Deep-PT against recent pixel tracking algorithms. As the experiments suggest, the proposed deep architecture deliberately learns what to track and how to track and outperforms the state-of-the-art methods.