 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnterior's Approach to Fairness Evaluation of Automated Prior Authorization System
Mar 15, 2026Increasing staffing constraints and turnaround-time pressures in Prior authorization (PA) have led to increasing automation of decision systems to support PA review. Evaluating fairness in such systems poses unique challenges because legitimate clinical guidelines and medical necessity criteria often differ across demographic groups, making parity in approval rates an inappropriate fairness metric. We propose a fairness evaluation framework for prior authorization models based on model error rates rather than approval outcomes. Using 7,166 human-reviewed cases spanning 27 medical necessity guidelines, we assessed consistency in sex, age, race/ethnicity, and socioeconomic status. Our evaluation combined error-rate comparisons, tolerance-band analysis with a predefined $\pm$5 percentage-point margin, statistical power evaluation, and protocol-controlled logistic regression. Across most demographics, model error rates were consistent, and confidence intervals fell within the predefined tolerance band, indicating no meaningful performance differences. For race/ethnicity, point estimates remain small, but subgroup sample sizes were limited, resulting in wide confidence intervals and underpowered tests, with inconclusive evidence within the dataset we explored. These findings illustrate a rigorous and regulator-aligned approach to fairness evaluation in administrative healthcare AI systems.
Improving Summarization with Human Edits
Oct 24, 2023



Recent work has shown the promise of learning with human feedback paradigms to produce human-determined high-quality text. Existing works use human feedback to train large language models (LLMs) in general domain abstractive summarization and have obtained summary quality exceeding traditional likelihood training. In this paper, we focus on a less explored form of human feedback -- Human Edits. We propose Sequence Alignment (un)Likelihood Training (SALT), a novel technique to use both the human-edited and model-generated data together in the training loop. In addition, we demonstrate simulating Human Edits with ground truth summaries coming from existing training data -- Imitation edits, along with the model-generated summaries obtained after the training, to reduce the need for expensive human-edit data. In our experiments, we extend human feedback exploration from general domain summarization to medical domain summarization. Our results demonstrate the effectiveness of SALT in improving the summary quality with Human and Imitation Edits. Through additional experiments, we show that SALT outperforms the conventional RLHF method (designed for human preferences) -- DPO, when applied to human-edit data. We hope the evidence in our paper prompts researchers to explore, collect, and better use different human feedback approaches scalably.
Weakly Supervised Medication Regimen Extraction from Medical Conversations
Oct 11, 2020
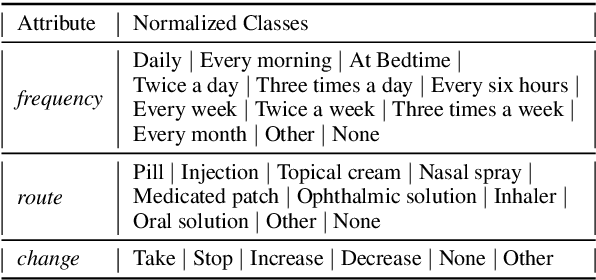

Automated Medication Regimen (MR) extraction from medical conversations can not only improve recall and help patients follow through with their care plan, but also reduce the documentation burden for doctors. In this paper, we focus on extracting spans for frequency, route and change, corresponding to medications discussed in the conversation. We first describe a unique dataset of annotated doctor-patient conversations and then present a weakly supervised model architecture that can perform span extraction using noisy classification data. The model utilizes an attention bottleneck inside a classification model to perform the extraction. We experiment with several variants of attention scoring and projection functions and propose a novel transformer-based attention scoring function (TAScore). The proposed combination of TAScore and Fusedmax projection achieves a 10 point increase in Longest Common Substring F1 compared to the baseline of additive scoring plus softmax projection.
Medication Regimen Extraction From Medical Conversations
Jan 03, 2020
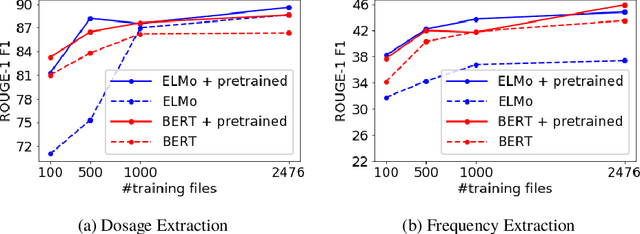
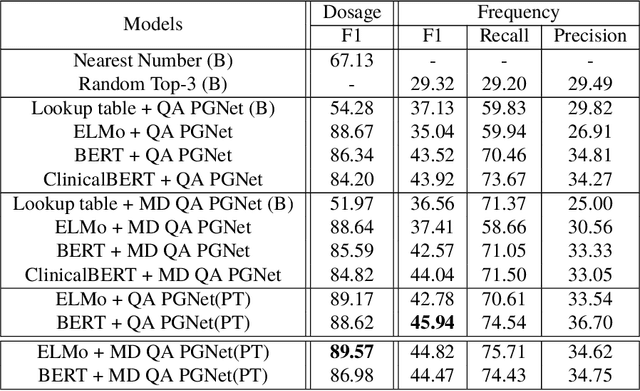
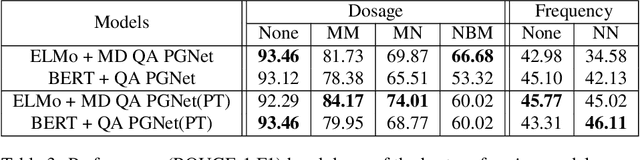
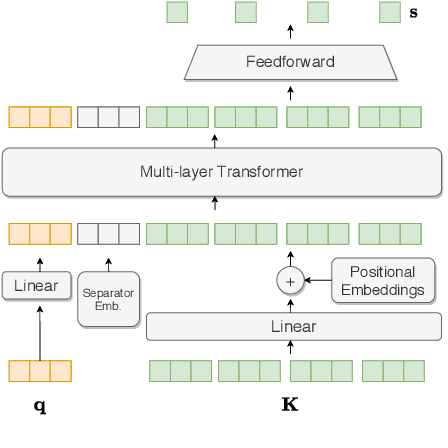
Extracting relevant information from medical conversations and providing it to doctors and patients might help in addressing doctor burnout and patient forgetfulness. In this paper, we focus on extracting the Medication Regimen (dosage and frequency for medications) discussed in a medical conversation. We frame the problem as a Question Answering (QA) task and perform comparative analysis over: a QA approach, a new combined QA and Information Extraction approach, and other baselines. We use a small corpus of 6,692 annotated doctor-patient conversations for the task. Clinical conversation corpora are costly to create, difficult to handle (because of data privacy concerns), and thus scarce. We address this data scarcity challenge through data augmentation methods, using publicly available embeddings and pretrain part of the network on a related task (summarization) to improve the model's performance. Compared to the baseline, our best-performing models improve the dosage and frequency extractions' ROUGE-1 F1 scores from 54.28 and 37.13 to 89.57 and 45.94, respectively. Using our best-performing model, we present the first fully automated system that can extract Medication Regimen tags from spontaneous doctor-patient conversations with about ~71% accuracy.