 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSIMLayer: Towards Robust Deep Representation Learning via Nonlinear Structural Similarity
Jul 28, 2018
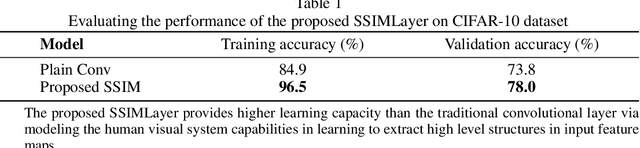


Deeper convolutional neural networks provide more capacity to approximate complex mapping functions. However, increasing network depth imposes difficulties on training and increases model complexity. This paper presents a new nonlinear computational layer of considerably high capacity to the deep convolutional neural network architectures. This layer performs a set of comprehensive convolution operations that mimics the overall function of the human visual system (HVS) via focusing on learning structural information in its input. The core of its computations is evaluating the components of the structural similarity metric (SSIM) in a setting that allows the kernels to learn to match structural information. The proposed SSIMLayer is inherently nonlinear and hence, it does not require subsequent nonlinear transformations. Experiments conducted on CIFAR-10 benchmark demonstrates that the SSIMLayer provides better convergence than the traditional convolutional layer, bypasses the need for nonlinear transformations and shows more robustness against noise perturbations and adversarial attacks.
3D Hand Pose Estimation using Simulation and Partial-Supervision with a Shared Latent Space
Jul 14, 2018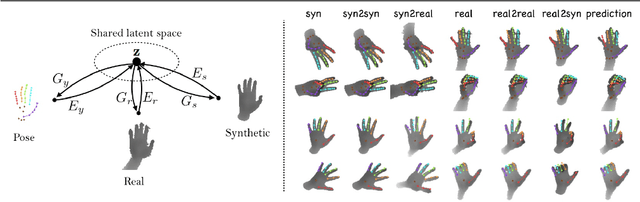

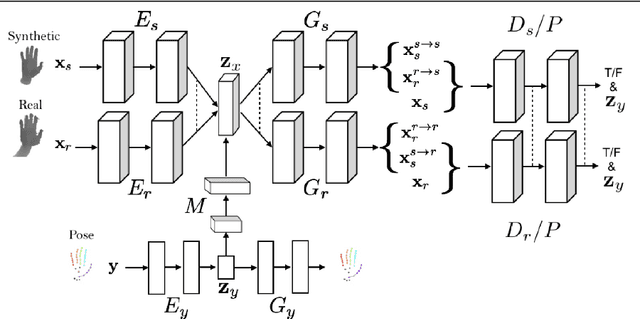
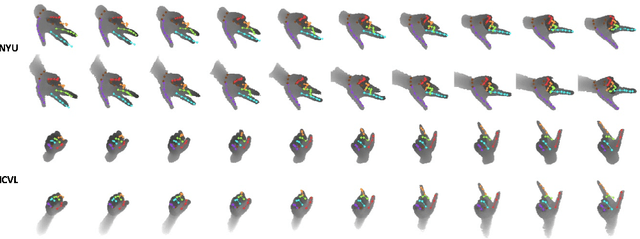
Tremendous amounts of expensive annotated data are a vital ingredient for state-of-the-art 3d hand pose estimation. Therefore, synthetic data has been popularized as annotations are automatically available. However, models trained only with synthetic samples do not generalize to real data, mainly due to the gap between the distribution of synthetic and real data. In this paper, we propose a novel method that seeks to predict the 3d position of the hand using both synthetic and partially-labeled real data. Accordingly, we form a shared latent space between three modalities: synthetic depth image, real depth image, and pose. We demonstrate that by carefully learning the shared latent space, we can find a regression model that is able to generalize to real data. As such, we show that our method produces accurate predictions in both semi-supervised and unsupervised settings. Additionally, the proposed model is capable of generating novel, meaningful, and consistent samples from all of the three domains. We evaluate our method qualitatively and quantitively on two highly competitive benchmarks (i.e., NYU and ICVL) and demonstrate its superiority over the state-of-the-art methods. The source code will be made available at https://github.com/masabdi/LSPS.
Multi-Agent Deep Reinforcement Learning with Human Strategies
Jun 12, 2018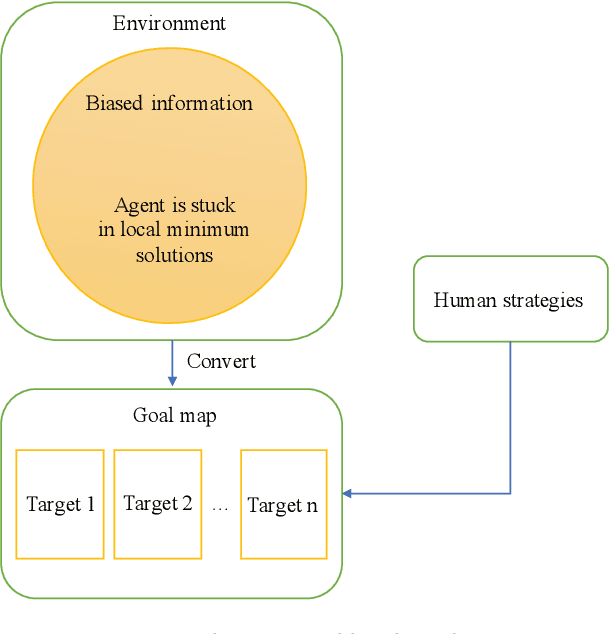
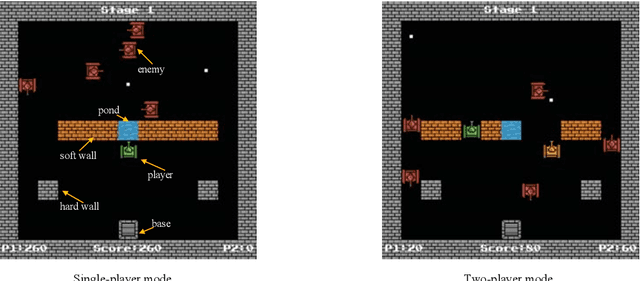
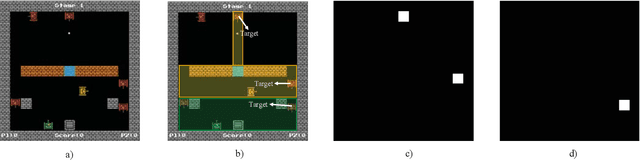
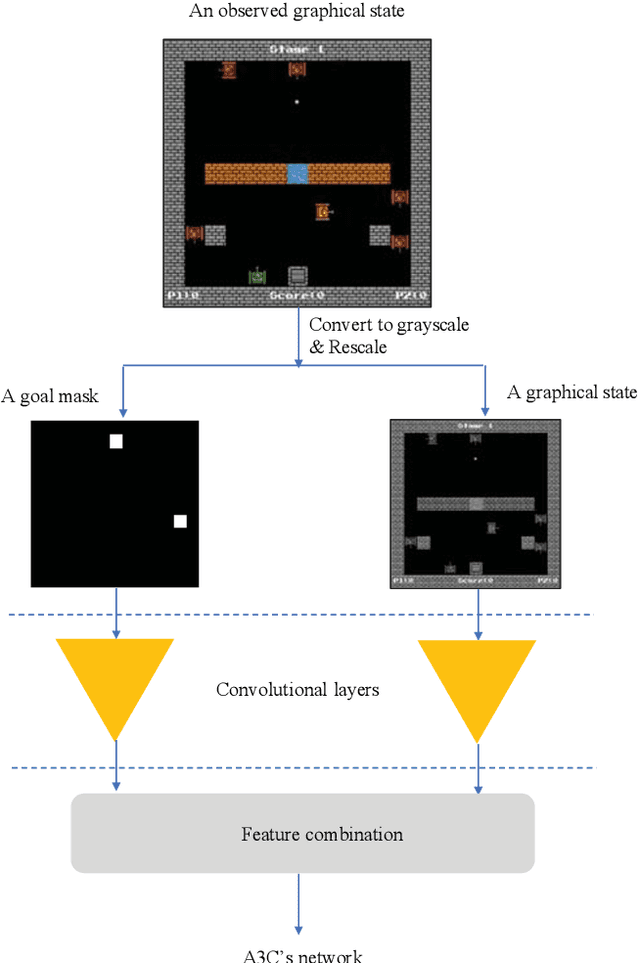
Deep learning has enabled traditional reinforcement learning methods to deal with high-dimensional problems. However, one of the disadvantages of deep reinforcement learning methods is the limited exploration capacity of learning agents. In this paper, we introduce an approach that integrates human strategies to increase the exploration capacity of multiple deep reinforcement learning agents. We also report the development of our own multi-agent environment called Multiple Tank Defence to simulate the proposed approach. The results show the significant performance improvement of multiple agents that have learned cooperatively with human strategies. This implies that there is a critical need for human intellect teamed with machines to solve complex problems. In addition, the success of this simulation indicates that our developed multi-agent environment can be used as a testbed platform to develop and validate other multi-agent control algorithms. Details of the environment implementation can be referred to http://www.deakin.edu.au/~thanhthi/madrl_human.htm
A Human Mixed Strategy Approach to Deep Reinforcement Learning
Apr 05, 2018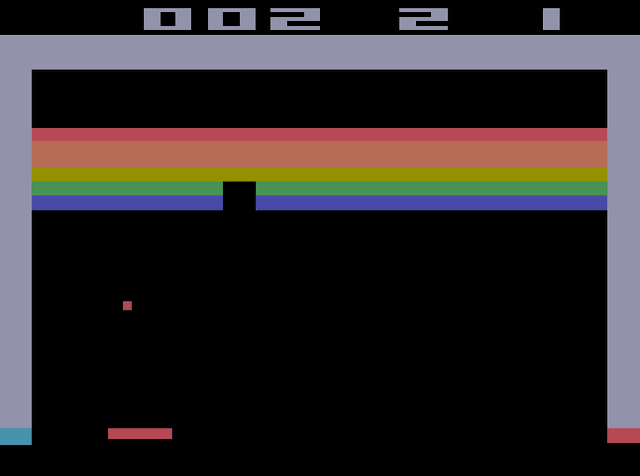
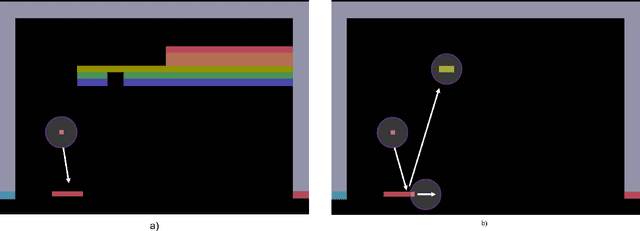
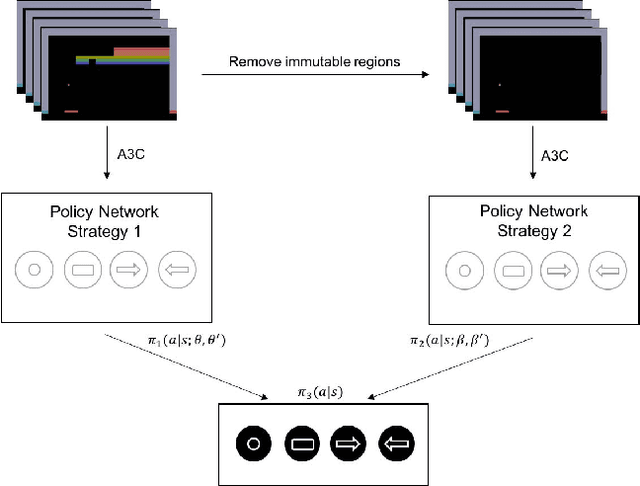
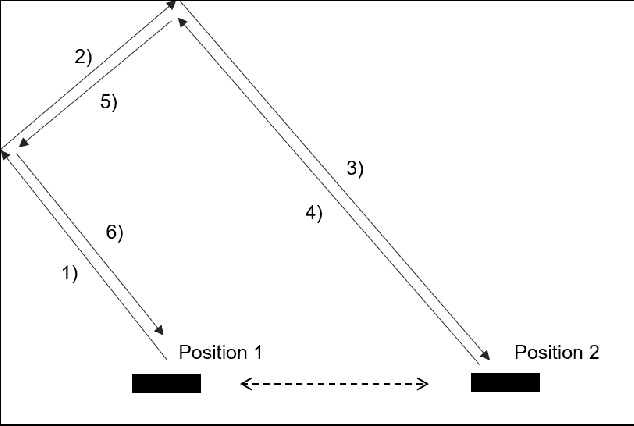
In 2015, Google's DeepMind announced an advancement in creating an autonomous agent based on deep reinforcement learning (DRL) that could beat a professional player in a series of 49 Atari games. However, the current manifestation of DRL is still immature, and has significant drawbacks. One of DRL's imperfections is its lack of "exploration" during the training process, especially when working with high-dimensional problems. In this paper, we propose a mixed strategy approach that mimics behaviors of human when interacting with environment, and create a "thinking" agent that allows for more efficient exploration in the DRL training process. The simulation results based on the Breakout game show that our scheme achieves a higher probability of obtaining a maximum score than does the baseline DRL algorithm, i.e., the asynchronous advantage actor-critic method. The proposed scheme therefore can be applied effectively to solving a complicated task in a real-world application.
Multi-Residual Networks: Improving the Speed and Accuracy of Residual Networks
Mar 15, 2017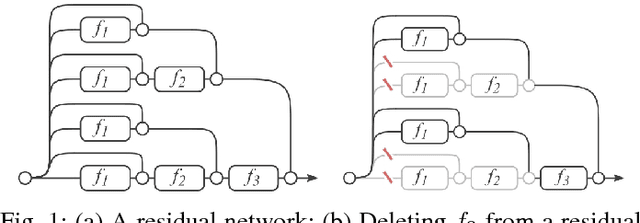
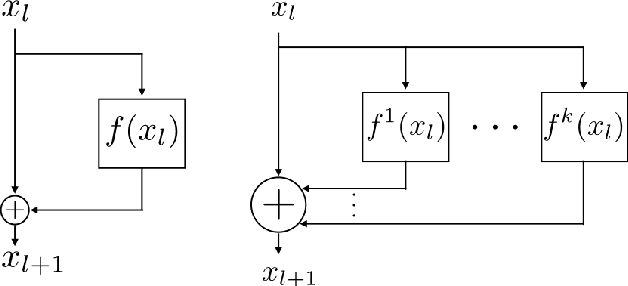
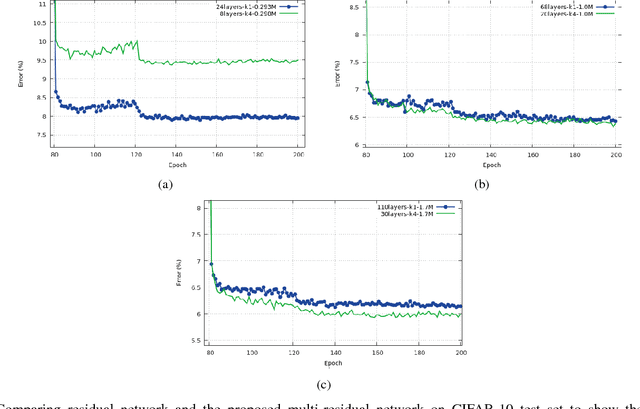
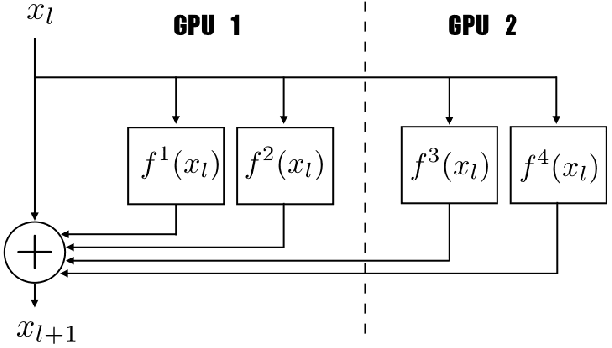
In this article, we take one step toward understanding the learning behavior of deep residual networks, and supporting the observation that deep residual networks behave like ensembles. We propose a new convolutional neural network architecture which builds upon the success of residual networks by explicitly exploiting the interpretation of very deep networks as an ensemble. The proposed multi-residual network increases the number of residual functions in the residual blocks. Our architecture generates models that are wider, rather than deeper, which significantly improves accuracy. We show that our model achieves an error rate of 3.73% and 19.45% on CIFAR-10 and CIFAR-100 respectively, that outperforms almost all of the existing models. We also demonstrate that our model outperforms very deep residual networks by 0.22% (top-1 error) on the full ImageNet 2012 classification dataset. Additionally, inspired by the parallel structure of multi-residual networks, a model parallelism technique has been investigated. The model parallelism method distributes the computation of residual blocks among the processors, yielding up to 15% computational complexity improvement.
Bag-of-Words Representation for Biomedical Time Series Classification
Dec 11, 2012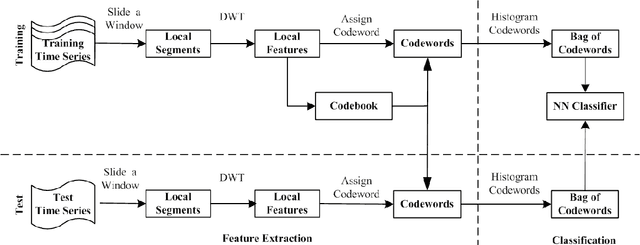
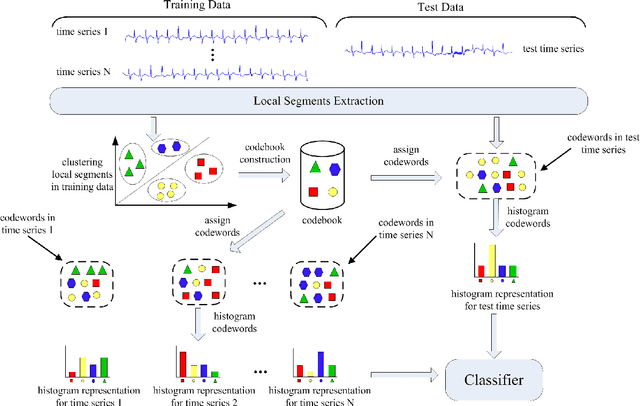
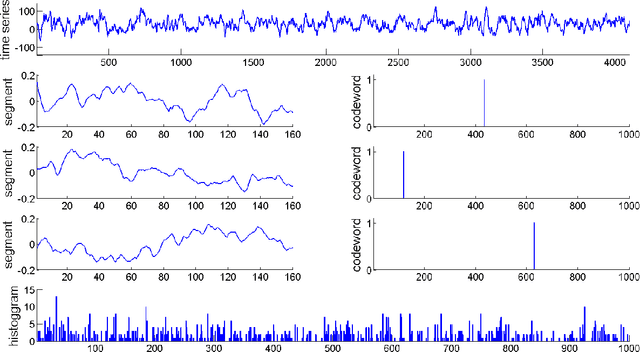
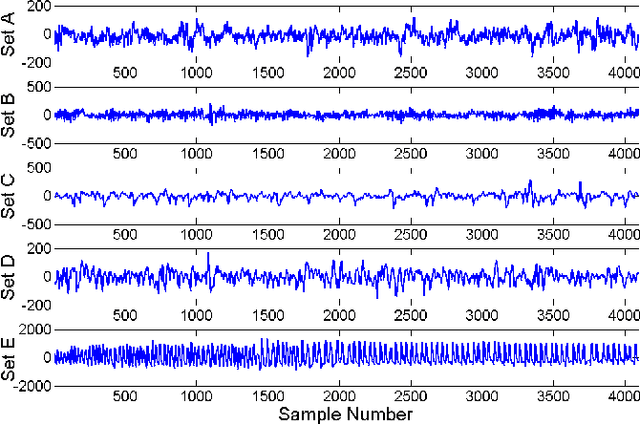
Automatic analysis of biomedical time series such as electroencephalogram (EEG) and electrocardiographic (ECG) signals has attracted great interest in the community of biomedical engineering due to its important applications in medicine. In this work, a simple yet effective bag-of-words representation that is able to capture both local and global structure similarity information is proposed for biomedical time series representation. In particular, similar to the bag-of-words model used in text document domain, the proposed method treats a time series as a text document and extracts local segments from the time series as words. The biomedical time series is then represented as a histogram of codewords, each entry of which is the count of a codeword appeared in the time series. Although the temporal order of the local segments is ignored, the bag-of-words representation is able to capture high-level structural information because both local and global structural information are well utilized. The performance of the bag-of-words model is validated on three datasets extracted from real EEG and ECG signals. The experimental results demonstrate that the proposed method is not only insensitive to parameters of the bag-of-words model such as local segment length and codebook size, but also robust to noise.