 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Hand Pose Estimation using Simulation and Partial-Supervision with a Shared Latent Space
Jul 14, 2018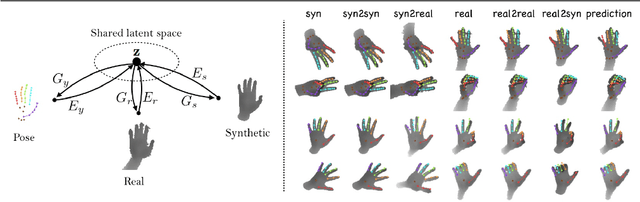

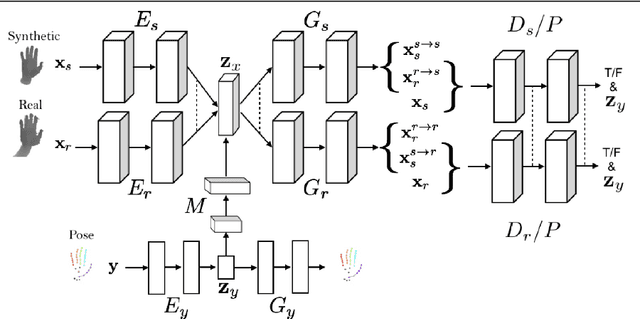
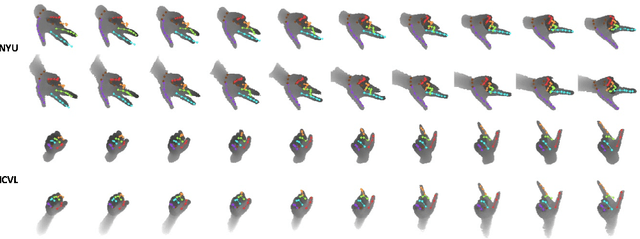
Tremendous amounts of expensive annotated data are a vital ingredient for state-of-the-art 3d hand pose estimation. Therefore, synthetic data has been popularized as annotations are automatically available. However, models trained only with synthetic samples do not generalize to real data, mainly due to the gap between the distribution of synthetic and real data. In this paper, we propose a novel method that seeks to predict the 3d position of the hand using both synthetic and partially-labeled real data. Accordingly, we form a shared latent space between three modalities: synthetic depth image, real depth image, and pose. We demonstrate that by carefully learning the shared latent space, we can find a regression model that is able to generalize to real data. As such, we show that our method produces accurate predictions in both semi-supervised and unsupervised settings. Additionally, the proposed model is capable of generating novel, meaningful, and consistent samples from all of the three domains. We evaluate our method qualitatively and quantitively on two highly competitive benchmarks (i.e., NYU and ICVL) and demonstrate its superiority over the state-of-the-art methods. The source code will be made available at https://github.com/masabdi/LSPS.
Multi-Residual Networks: Improving the Speed and Accuracy of Residual Networks
Mar 15, 2017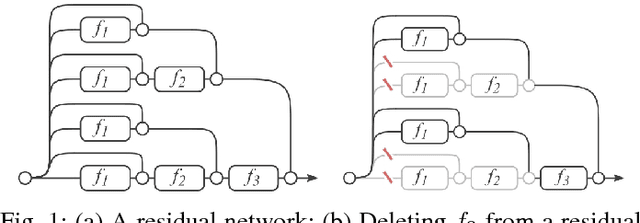
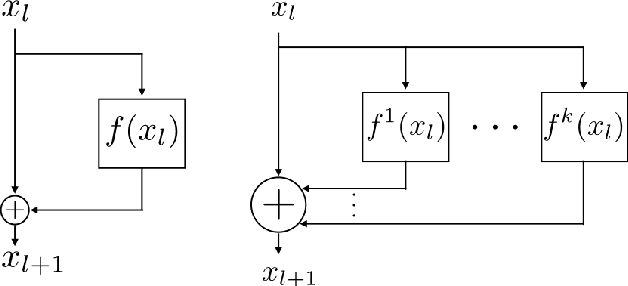
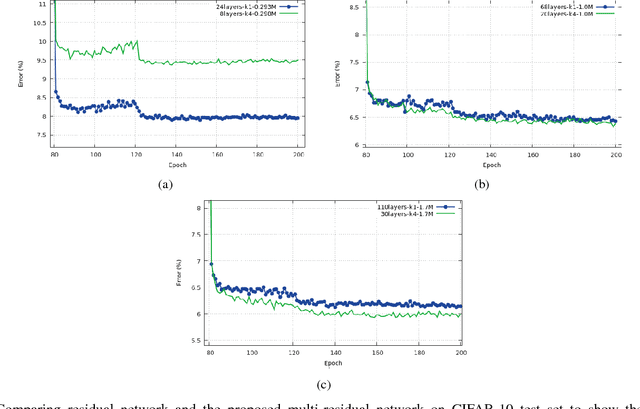
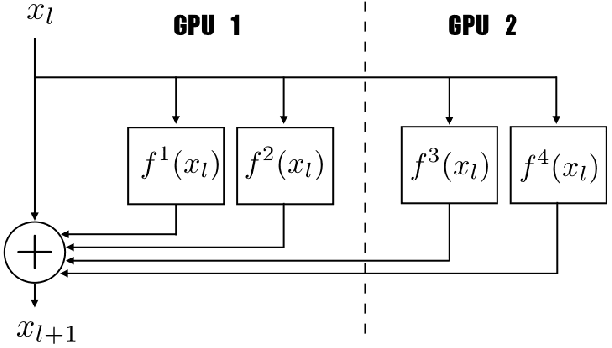
In this article, we take one step toward understanding the learning behavior of deep residual networks, and supporting the observation that deep residual networks behave like ensembles. We propose a new convolutional neural network architecture which builds upon the success of residual networks by explicitly exploiting the interpretation of very deep networks as an ensemble. The proposed multi-residual network increases the number of residual functions in the residual blocks. Our architecture generates models that are wider, rather than deeper, which significantly improves accuracy. We show that our model achieves an error rate of 3.73% and 19.45% on CIFAR-10 and CIFAR-100 respectively, that outperforms almost all of the existing models. We also demonstrate that our model outperforms very deep residual networks by 0.22% (top-1 error) on the full ImageNet 2012 classification dataset. Additionally, inspired by the parallel structure of multi-residual networks, a model parallelism technique has been investigated. The model parallelism method distributes the computation of residual blocks among the processors, yielding up to 15% computational complexity improvement.