 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrOCR for Medieval HTR: A Systematic Ablation Study with Cross-Dataset Validation
Jun 23, 2026Fine-tuning transformer-based handwritten text recognition (HTR) models on medieval manuscripts is challenging because these models are pre-trained on modern text and must adapt to a very different visual domain. This paper studies how three controllable fine-tuning choices (contrast normalization, data augmentation, and layer freezing) affect recognition accuracy when adapting TrOCR to small historical datasets. We run controlled experiments on a 13th-century Italian manuscript (I-CT 91 "Cortonese") and replicate the same experimental grid on the public READ-16 benchmark as robustness evidence. On Cortonese, our best configuration achieves 8.03% character error rate (CER). Statistical comparisons across 13 configurations show that freezing up to three encoder layers or six decoder layers does not significantly harm accuracy, while deeper freezing becomes progressively detrimental. Removing contrast normalization (CLAHE) yields 7.84% CER, comparable to a domain-specialized baseline, suggesting strong optimization can reduce reliance on image preprocessing. Cross-dataset validation on READ-16 shows that decoder freezing thresholds transfer more robustly than encoder thresholds, and combined freezing strategies require dataset-specific re-validation. Finally, we use Grad-CAM gradient attributions and decoder cross-attention maps to diagnose error patterns and failure modes revealed by the ablations. Source code is available at https://github.com/LaudareProject/TrOCR-analysis
Pre-Hoc Predictions in AutoML: Leveraging LLMs to Enhance Model Selection and Benchmarking for Tabular datasets
Oct 02, 2025The field of AutoML has made remarkable progress in post-hoc model selection, with libraries capable of automatically identifying the most performing models for a given dataset. Nevertheless, these methods often rely on exhaustive hyperparameter searches, where methods automatically train and test different types of models on the target dataset. Contrastingly, pre-hoc prediction emerges as a promising alternative, capable of bypassing exhaustive search through intelligent pre-selection of models. Despite its potential, pre-hoc prediction remains under-explored in the literature. This paper explores the intersection of AutoML and pre-hoc model selection by leveraging traditional models and Large Language Model (LLM) agents to reduce the search space of AutoML libraries. By relying on dataset descriptions and statistical information, we reduce the AutoML search space. Our methodology is applied to the AWS AutoGluon portfolio dataset, a state-of-the-art AutoML benchmark containing 175 tabular classification datasets available on OpenML. The proposed approach offers a shift in AutoML workflows, significantly reducing computational overhead, while still selecting the best model for the given dataset.
YouLeQD: Decoding the Cognitive Complexity of Questions and Engagement in Online Educational Videos from Learners' Perspectives
Jan 20, 2025Questioning is a fundamental aspect of education, as it helps assess students' understanding, promotes critical thinking, and encourages active engagement. With the rise of artificial intelligence in education, there is a growing interest in developing intelligent systems that can automatically generate and answer questions and facilitate interactions in both virtual and in-person education settings. However, to develop effective AI models for education, it is essential to have a fundamental understanding of questioning. In this study, we created the YouTube Learners' Questions on Bloom's Taxonomy Dataset (YouLeQD), which contains learner-posed questions from YouTube lecture video comments. Along with the dataset, we developed two RoBERTa-based classification models leveraging Large Language Models to detect questions and analyze their cognitive complexity using Bloom's Taxonomy. This dataset and our findings provide valuable insights into the cognitive complexity of learner-posed questions in educational videos and their relationship with interaction metrics. This can aid in the development of more effective AI models for education and improve the overall learning experience for students.
Characterization of Frequent Online Shoppers using Statistical Learning with Sparsity
Nov 11, 2021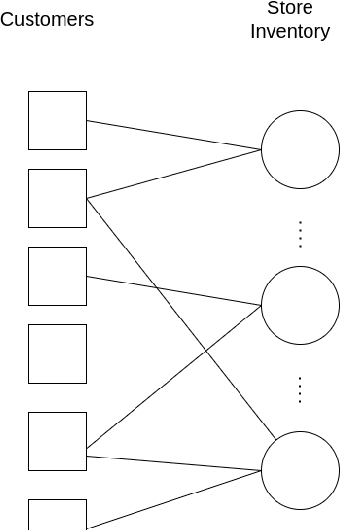
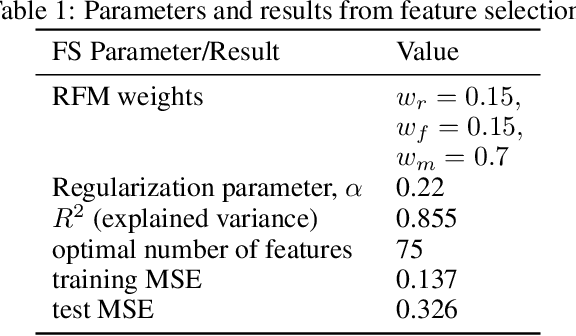
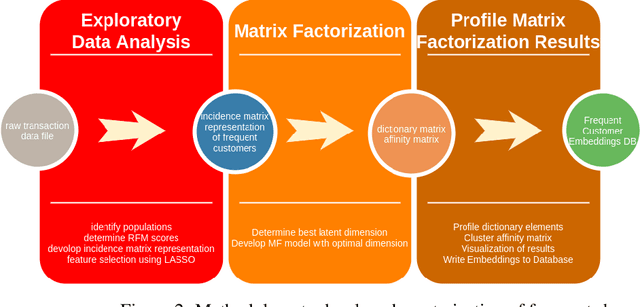

Developing shopping experiences that delight the customer requires businesses to understand customer taste. This work reports a method to learn the shopping preferences of frequent shoppers to an online gift store by combining ideas from retail analytics and statistical learning with sparsity. Shopping activity is represented as a bipartite graph. This graph is refined by applying sparsity-based statistical learning methods. These methods are interpretable and reveal insights about customers' preferences as well as products driving revenue to the store.