 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngGPT2: Sovereign, Efficient and Open Intelligence
Mar 17, 2026EngGPT2-16B-A3B is the latest iteration of Engineering Group's Italian LLM and it's built to be a Sovereign, Efficient and Open model. EngGPT2 is trained on 2.5 trillion tokens - less than Qwen3's 36T or Llama3's 15T - and delivers performance on key benchmarks, including MMLU-Pro, GSM8K, IFEval and HumanEval, comparable to dense models in the 8B-16B range, while requiring one-fifth to half of the inference power, and between one-tenth to one-sixth of the training data and consequent needed training power. Designed as a trained-from-scratch Mixture-of-Experts (MoE) architecture, EngGPT2 features 16 billion parameters with 3 billion active per inference, with expert sizes positioned between those used in GPT-OSS and Qwen3. Approximately 25% of its training corpus consists of Italian-language data, to deliver strong capabilities for European and Italian NLP tasks among models of similar scale. This efficiency aims to position EngGPT2 as a key contributor to the growing portfolio of open-weight European models, combining performance and efficiency with full alignment to the EU AI Act. EngGPT2 is also a single model capable of multiple reasoning modes: non-reasoning, reasoning in Italian or English, and turbo-reasoning (a concise, bullet-point style reasoning available in both languages designed for real-time reasoning use cases). EngGPT2 aims to set a new standard for resource-conscious, high-performance LLMs tailored to European and Italian contexts.
Quantum Approaches to Urban Logistics: From Core QAOA to Clustered Scalability
Dec 11, 2025The Traveling Salesman Problem (TSP) is a fundamental challenge in combinatorial optimization, widely applied in logistics and transportation. As the size of TSP instances grows, traditional algorithms often struggle to produce high-quality solutions within reasonable timeframes. This study investigates the potential of the Quantum Approximate Optimization Algorithm (QAOA), a hybrid quantum-classical method, to solve TSP under realistic constraints. We adopt a QUBO-based formulation of TSP that integrates real-world logistical constraints reflecting operational conditions, such as vehicle capacity, road accessibility, and time windows, while ensuring compatibility with the limitations of current quantum hardware. Our experiments are conducted in a simulated environment using high-performance computing (HPC) resources to assess QAOA's performance across different problem sizes and quantum circuit depths. In order to improve scalability, we propose clustering QAOA (Cl-QAOA), a hybrid approach combining classical machine learning with QAOA. This method decomposes large TSP instances into smaller sub-problems, making quantum optimization feasible even on devices with a limited number of qubits. The results offer a comprehensive evaluation of QAOA's strengths and limitations in solving constrained TSP scenarios. This study advances quantum optimization and lays groundwork for future large-scale applications.
Training very large scale nonlinear SVMs using Alternating Direction Method of Multipliers coupled with the Hierarchically Semi-Separable kernel approximations
Aug 09, 2021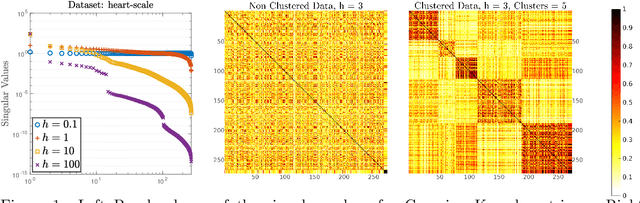
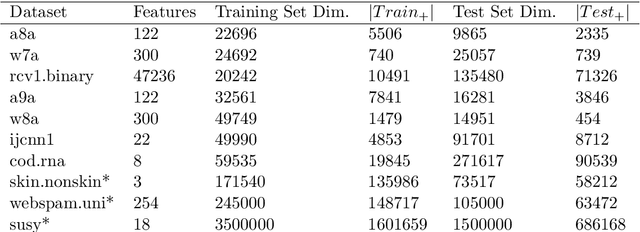
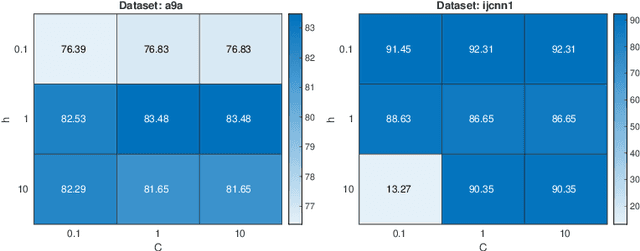
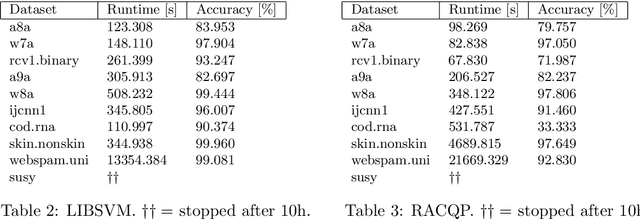
Typically, nonlinear Support Vector Machines (SVMs) produce significantly higher classification quality when compared to linear ones but, at the same time, their computational complexity is prohibitive for large-scale datasets: this drawback is essentially related to the necessity to store and manipulate large, dense and unstructured kernel matrices. Despite the fact that at the core of training a SVM there is a \textit{simple} convex optimization problem, the presence of kernel matrices is responsible for dramatic performance reduction, making SVMs unworkably slow for large problems. Aiming to an efficient solution of large-scale nonlinear SVM problems, we propose the use of the \textit{Alternating Direction Method of Multipliers} coupled with \textit{Hierarchically Semi-Separable} (HSS) kernel approximations. As shown in this work, the detailed analysis of the interaction among their algorithmic components unveils a particularly efficient framework and indeed, the presented experimental results demonstrate a significant speed-up when compared to the \textit{state-of-the-art} nonlinear SVM libraries (without significantly affecting the classification accuracy).