 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining very large scale nonlinear SVMs using Alternating Direction Method of Multipliers coupled with the Hierarchically Semi-Separable kernel approximations
Aug 09, 2021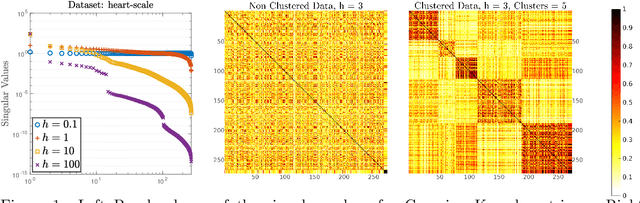
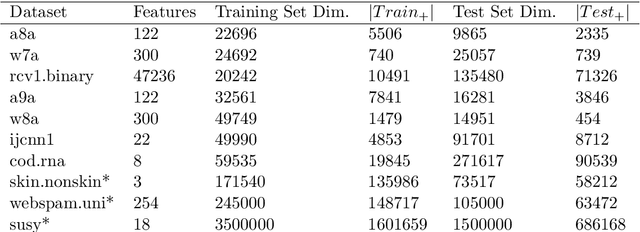
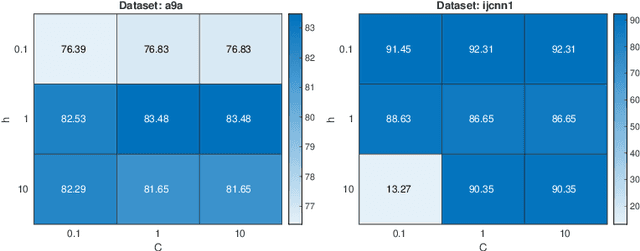
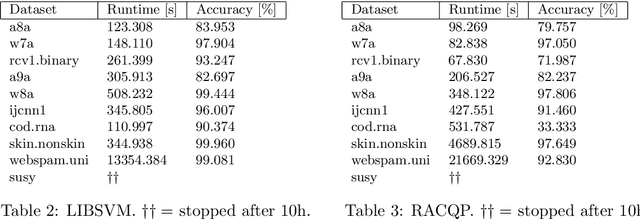
Typically, nonlinear Support Vector Machines (SVMs) produce significantly higher classification quality when compared to linear ones but, at the same time, their computational complexity is prohibitive for large-scale datasets: this drawback is essentially related to the necessity to store and manipulate large, dense and unstructured kernel matrices. Despite the fact that at the core of training a SVM there is a \textit{simple} convex optimization problem, the presence of kernel matrices is responsible for dramatic performance reduction, making SVMs unworkably slow for large problems. Aiming to an efficient solution of large-scale nonlinear SVM problems, we propose the use of the \textit{Alternating Direction Method of Multipliers} coupled with \textit{Hierarchically Semi-Separable} (HSS) kernel approximations. As shown in this work, the detailed analysis of the interaction among their algorithmic components unveils a particularly efficient framework and indeed, the presented experimental results demonstrate a significant speed-up when compared to the \textit{state-of-the-art} nonlinear SVM libraries (without significantly affecting the classification accuracy).