 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Image Editing Foundation Models for Data-Efficient CT Metal Artifact Reduction
Apr 07, 2026Metal artifacts from high-attenuation implants severely degrade CT image quality, obscuring critical anatomical structures and posing a challenge for standard deep learning methods that require extensive paired training data. We propose a paradigm shift: reframing artifact reduction as an in-context reasoning task by adapting a general-purpose vision-language diffusion foundation model via parameter-efficient Low-Rank Adaptation (LoRA). By leveraging rich visual priors, our approach achieves effective artifact suppression with only 16 to 128 paired training examples reducing data requirements by two orders of magnitude. Crucially, we demonstrate that domain adaptation is essential for hallucination mitigation; without it, foundation models interpret streak artifacts as erroneous natural objects (e.g., waffles or petri dishes). To ground the restoration, we propose a multi-reference conditioning strategy where clean anatomical exemplars from unrelated subjects are provided alongside the corrupted input, enabling the model to exploit category-specific context to infer uncorrupted anatomy. Extensive evaluation on the AAPM CT-MAR benchmark demonstrates that our method achieves state-of-the-art performance on perceptual and radiological-feature metrics . This work establishes that foundation models, when appropriately adapted, offer a scalable alternative for interpretable, data-efficient medical image reconstruction. Code is available at https://github.com/ahmetemirdagi/CT-EditMAR.
Edit2Interp: Adapting Image Foundation Models from Spatial Editing to Video Frame Interpolation with Few-Shot Learning
Mar 16, 2026Pre-trained image editing models exhibit strong spatial reasoning and object-aware transformation capabilities acquired from billions of image-text pairs, yet they possess no explicit temporal modeling. This paper demonstrates that these spatial priors can be repurposed to unlock temporal synthesis capabilities through minimal adaptation - without introducing any video-specific architecture or motion estimation modules. We show that a large image editing model (Qwen-Image-Edit), originally designed solely for static instruction-based edits, can be adapted for Video Frame Interpolation (VFI) using only 64-256 training samples via Low-Rank Adaptation (LoRA). Our core contribution is revealing that the model's inherent understanding of "how objects transform" in static scenes contains latent temporal reasoning that can be activated through few-shot fine-tuning. While the baseline model completely fails at producing coherent intermediate frames, our parameter-efficient adaptation successfully unlocks its interpolation capability. Rather than competing with task-specific VFI methods trained from scratch on massive datasets, our work establishes that foundation image editing models possess untapped potential for temporal tasks, offering a data-efficient pathway for video synthesis in resource-constrained scenarios. This bridges the gap between image manipulation and video understanding, suggesting that spatial and temporal reasoning may be more intertwined in foundation models than previously recognized
Multimodal Video-based Apparent Personality Recognition Using Long Short-Term Memory and Convolutional Neural Networks
Nov 01, 2019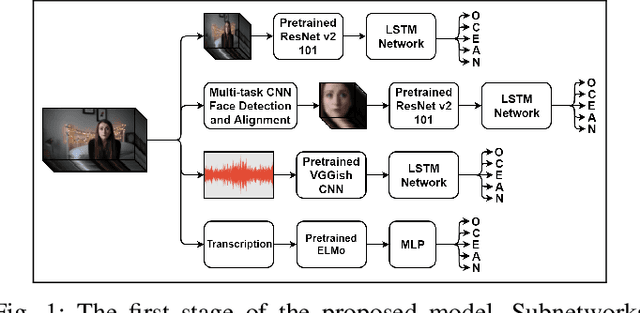
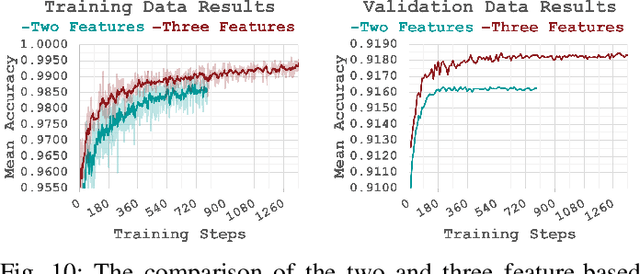
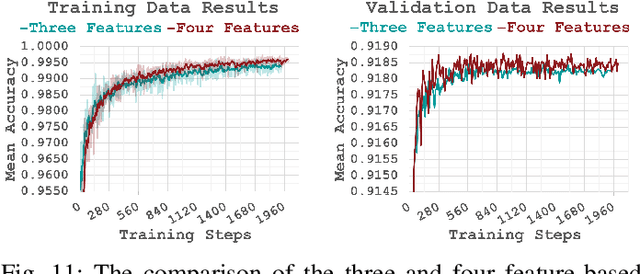
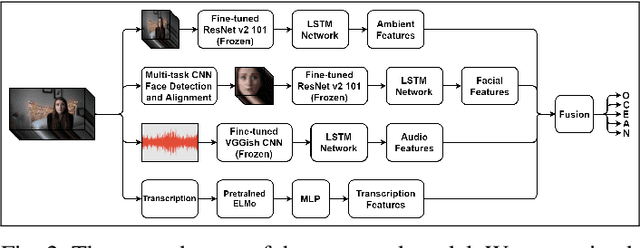
Personality computing and affective computing, where the recognition of personality traits is essential, have gained increasing interest and attention in many research areas recently. We propose a novel approach to recognize the Big Five personality traits of people from videos. Personality and emotion affect the speaking style, facial expressions, body movements, and linguistic factors in social contexts, and they are affected by environmental elements. We develop a multimodal system to recognize apparent personality based on various modalities such as the face, environment, audio, and transcription features. We use modality-specific neural networks that learn to recognize the traits independently and we obtain a final prediction of apparent personality with a feature-level fusion of these networks. We employ pre-trained deep convolutional neural networks such as ResNet and VGGish networks to extract high-level features and Long Short-Term Memory networks to integrate temporal information. We train the large model consisting of modality-specific subnetworks using a two-stage training process. We first train the subnetworks separately and then fine-tune the overall model using these trained networks. We evaluate the proposed method using ChaLearn First Impressions V2 challenge dataset. Our approach obtains the best overall "mean accuracy" score, averaged over five personality traits, compared to the state-of-the-art.
Deep Convolutional Generative Adversarial Networks Based Flame Detection in Video
Feb 05, 2019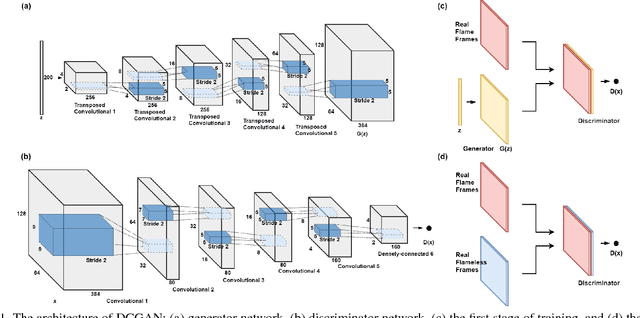
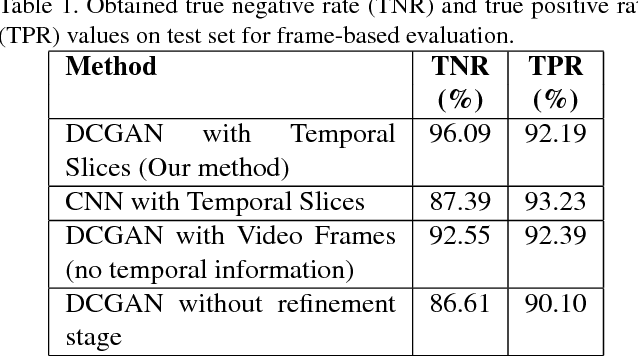

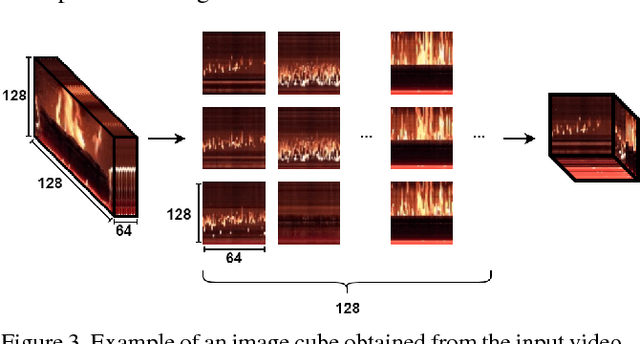
Real-time flame detection is crucial in video based surveillance systems. We propose a vision-based method to detect flames using Deep Convolutional Generative Adversarial Neural Networks (DCGANs). Many existing supervised learning approaches using convolutional neural networks do not take temporal information into account and require substantial amount of labeled data. In order to have a robust representation of sequences with and without flame, we propose a two-stage training of a DCGAN exploiting spatio-temporal flame evolution. Our training framework includes the regular training of a DCGAN with real spatio-temporal images, namely, temporal slice images, and noise vectors, and training the discriminator separately using the temporal flame images without the generator. Experimental results show that the proposed method effectively detects flame in video with negligible false positive rates in real-time.