 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEarly Stopping is Nonparametric Variational Inference
Apr 06, 2015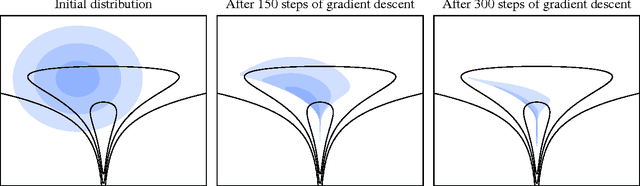
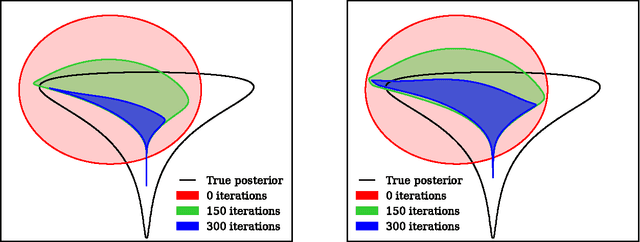
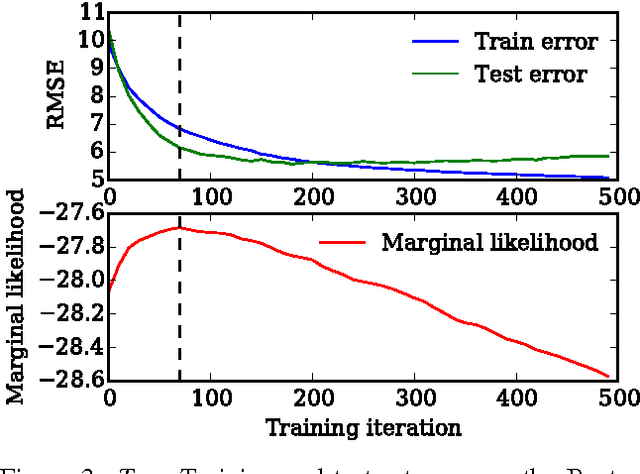
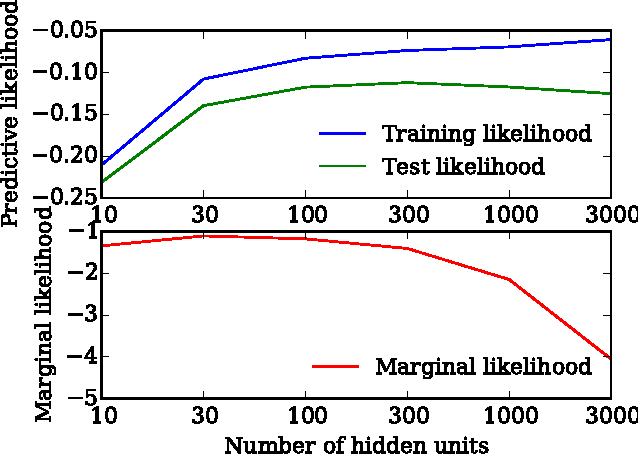
We show that unconverged stochastic gradient descent can be interpreted as a procedure that samples from a nonparametric variational approximate posterior distribution. This distribution is implicitly defined as the transformation of an initial distribution by a sequence of optimization updates. By tracking the change in entropy over this sequence of transformations during optimization, we form a scalable, unbiased estimate of the variational lower bound on the log marginal likelihood. We can use this bound to optimize hyperparameters instead of using cross-validation. This Bayesian interpretation of SGD suggests improved, overfitting-resistant optimization procedures, and gives a theoretical foundation for popular tricks such as early stopping and ensembling. We investigate the properties of this marginal likelihood estimator on neural network models.
Gradient-based Hyperparameter Optimization through Reversible Learning
Apr 02, 2015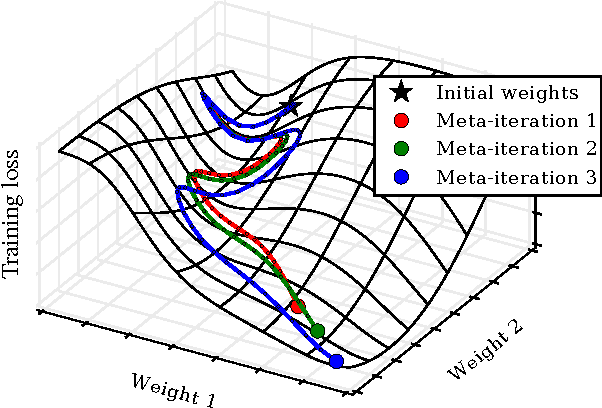
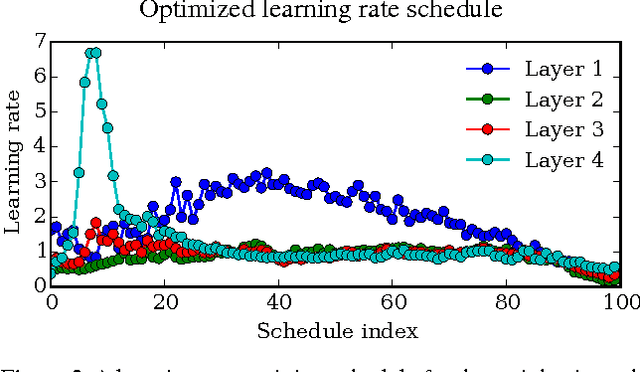
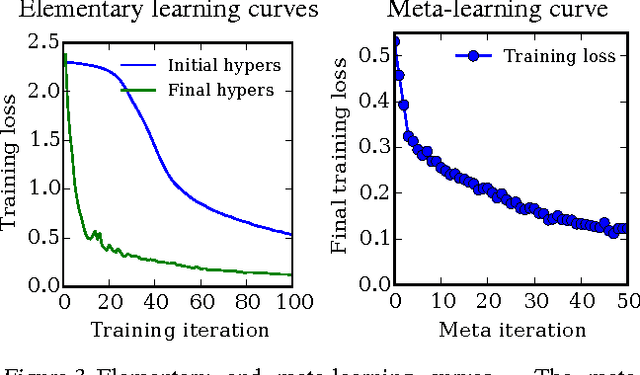
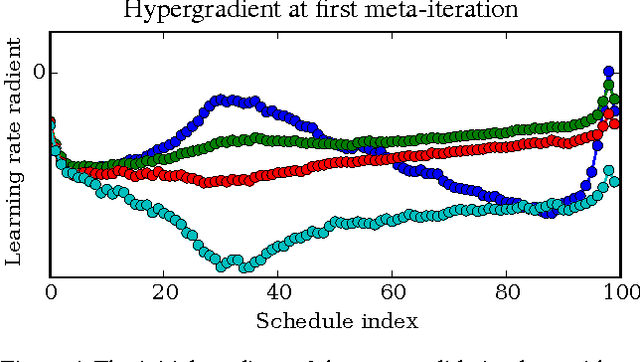
Tuning hyperparameters of learning algorithms is hard because gradients are usually unavailable. We compute exact gradients of cross-validation performance with respect to all hyperparameters by chaining derivatives backwards through the entire training procedure. These gradients allow us to optimize thousands of hyperparameters, including step-size and momentum schedules, weight initialization distributions, richly parameterized regularization schemes, and neural network architectures. We compute hyperparameter gradients by exactly reversing the dynamics of stochastic gradient descent with momentum.
A framework for studying synaptic plasticity with neural spike train data
Nov 14, 2014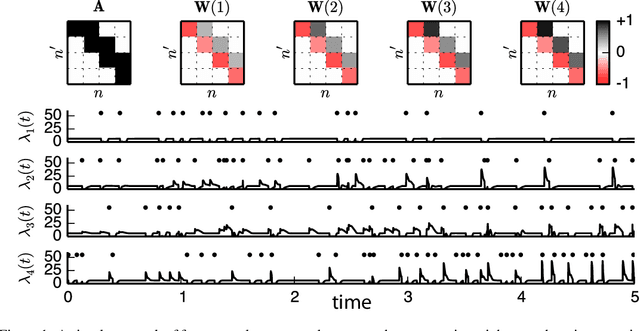
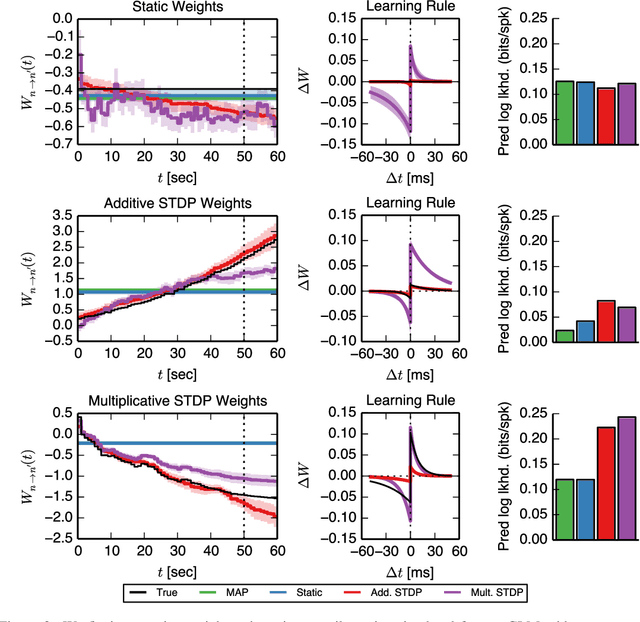
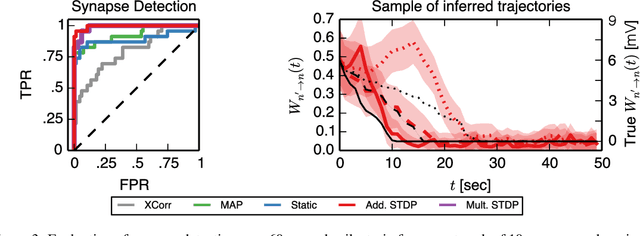
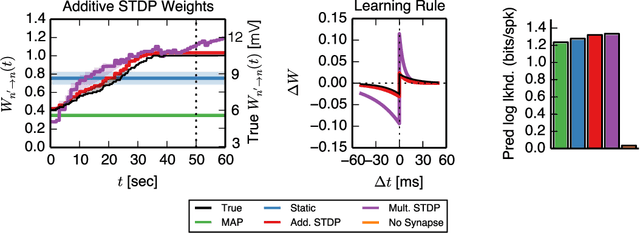
Learning and memory in the brain are implemented by complex, time-varying changes in neural circuitry. The computational rules according to which synaptic weights change over time are the subject of much research, and are not precisely understood. Until recently, limitations in experimental methods have made it challenging to test hypotheses about synaptic plasticity on a large scale. However, as such data become available and these barriers are lifted, it becomes necessary to develop analysis techniques to validate plasticity models. Here, we present a highly extensible framework for modeling arbitrary synaptic plasticity rules on spike train data in populations of interconnected neurons. We treat synaptic weights as a (potentially nonlinear) dynamical system embedded in a fully-Bayesian generalized linear model (GLM). In addition, we provide an algorithm for inferring synaptic weight trajectories alongside the parameters of the GLM and of the learning rules. Using this method, we perform model comparison of two proposed variants of the well-known spike-timing-dependent plasticity (STDP) rule, where nonlinear effects play a substantial role. On synthetic data generated from the biophysical simulator NEURON, we show that we can recover the weight trajectories, the pattern of connectivity, and the underlying learning rules.
Parallel MCMC with Generalized Elliptical Slice Sampling
Jul 24, 2014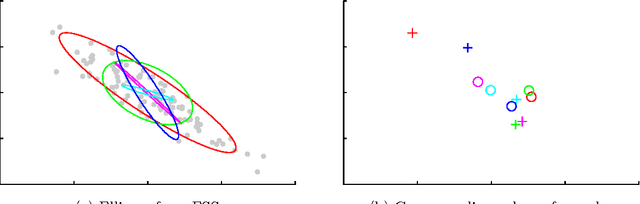
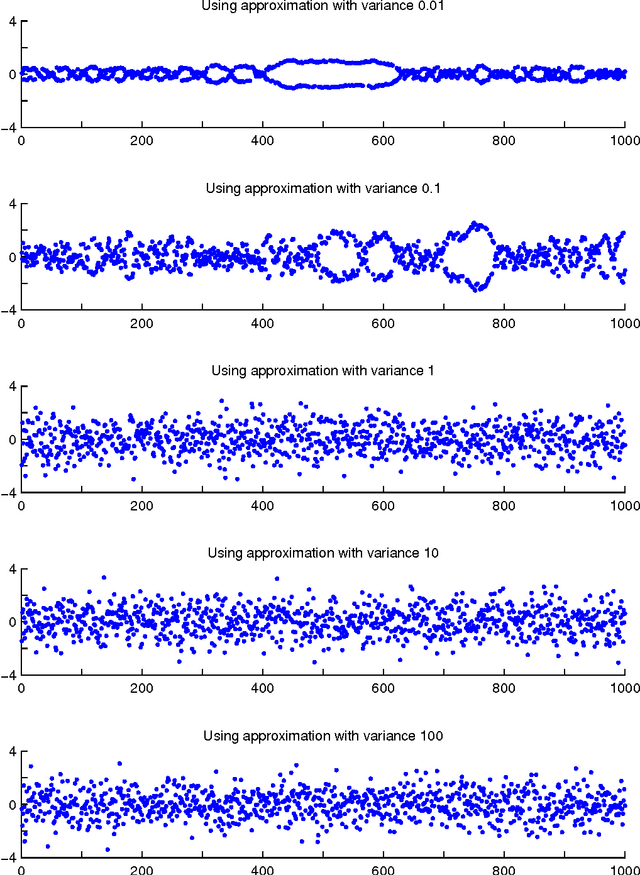
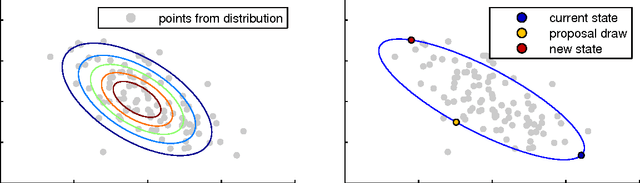
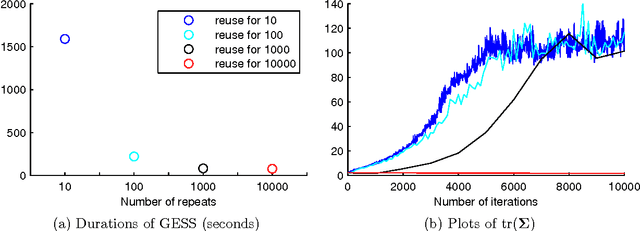
Probabilistic models are conceptually powerful tools for finding structure in data, but their practical effectiveness is often limited by our ability to perform inference in them. Exact inference is frequently intractable, so approximate inference is often performed using Markov chain Monte Carlo (MCMC). To achieve the best possible results from MCMC, we want to efficiently simulate many steps of a rapidly mixing Markov chain which leaves the target distribution invariant. Of particular interest in this regard is how to take advantage of multi-core computing to speed up MCMC-based inference, both to improve mixing and to distribute the computational load. In this paper, we present a parallelizable Markov chain Monte Carlo algorithm for efficiently sampling from continuous probability distributions that can take advantage of hundreds of cores. This method shares information between parallel Markov chains to build a scale-mixture of Gaussians approximation to the density function of the target distribution. We combine this approximation with a recent method known as elliptical slice sampling to create a Markov chain with no step-size parameters that can mix rapidly without requiring gradient or curvature computations.
* 19 pages, 8 figures, 3 algorithms
Input Warping for Bayesian Optimization of Non-stationary Functions
Jun 11, 2014


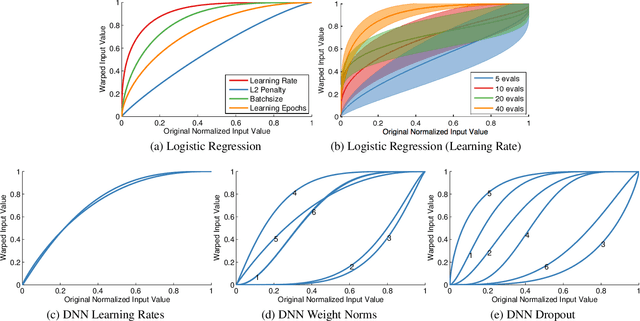
Bayesian optimization has proven to be a highly effective methodology for the global optimization of unknown, expensive and multimodal functions. The ability to accurately model distributions over functions is critical to the effectiveness of Bayesian optimization. Although Gaussian processes provide a flexible prior over functions which can be queried efficiently, there are various classes of functions that remain difficult to model. One of the most frequently occurring of these is the class of non-stationary functions. The optimization of the hyperparameters of machine learning algorithms is a problem domain in which parameters are often manually transformed a priori, for example by optimizing in "log-space," to mitigate the effects of spatially-varying length scale. We develop a methodology for automatically learning a wide family of bijective transformations or warpings of the input space using the Beta cumulative distribution function. We further extend the warping framework to multi-task Bayesian optimization so that multiple tasks can be warped into a jointly stationary space. On a set of challenging benchmark optimization tasks, we observe that the inclusion of warping greatly improves on the state-of-the-art, producing better results faster and more reliably.
Accelerating MCMC via Parallel Predictive Prefetching
Mar 28, 2014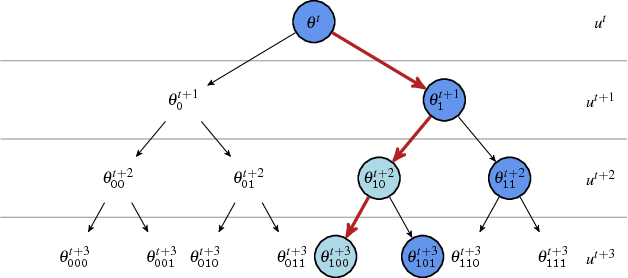
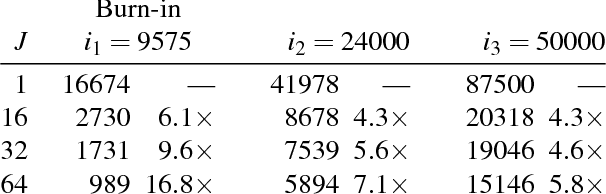
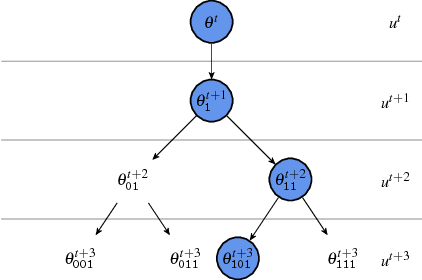

We present a general framework for accelerating a large class of widely used Markov chain Monte Carlo (MCMC) algorithms. Our approach exploits fast, iterative approximations to the target density to speculatively evaluate many potential future steps of the chain in parallel. The approach can accelerate computation of the target distribution of a Bayesian inference problem, without compromising exactness, by exploiting subsets of data. It takes advantage of whatever parallel resources are available, but produces results exactly equivalent to standard serial execution. In the initial burn-in phase of chain evaluation, it achieves speedup over serial evaluation that is close to linear in the number of available cores.
Firefly Monte Carlo: Exact MCMC with Subsets of Data
Mar 22, 2014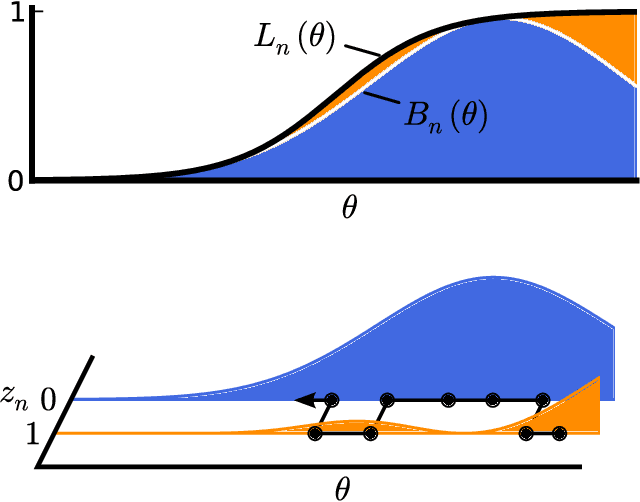
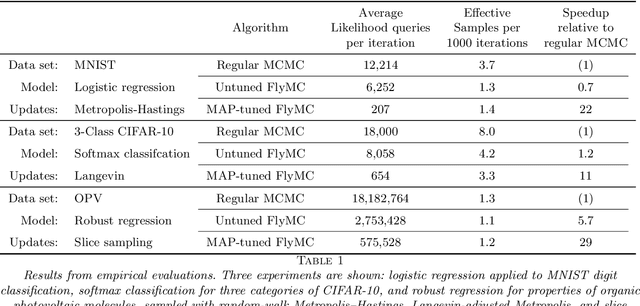
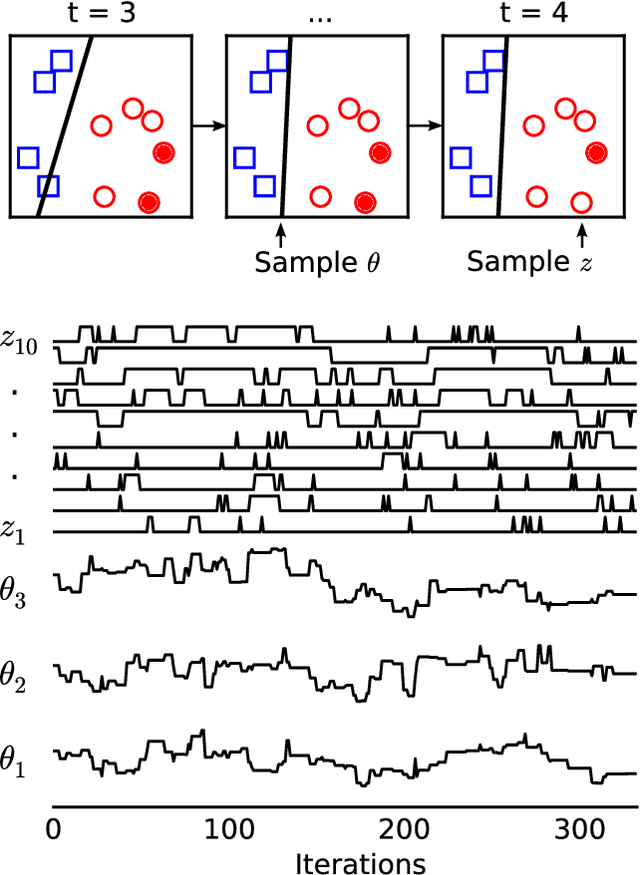
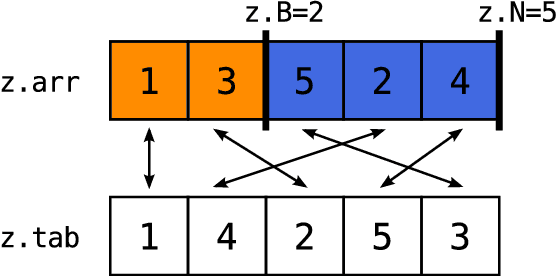
Markov chain Monte Carlo (MCMC) is a popular and successful general-purpose tool for Bayesian inference. However, MCMC cannot be practically applied to large data sets because of the prohibitive cost of evaluating every likelihood term at every iteration. Here we present Firefly Monte Carlo (FlyMC) an auxiliary variable MCMC algorithm that only queries the likelihoods of a potentially small subset of the data at each iteration yet simulates from the exact posterior distribution, in contrast to recent proposals that are approximate even in the asymptotic limit. FlyMC is compatible with a wide variety of modern MCMC algorithms, and only requires a lower bound on the per-datum likelihood factors. In experiments, we find that FlyMC generates samples from the posterior more than an order of magnitude faster than regular MCMC, opening up MCMC methods to larger datasets than were previously considered feasible.
Bayesian Optimization with Unknown Constraints
Mar 22, 2014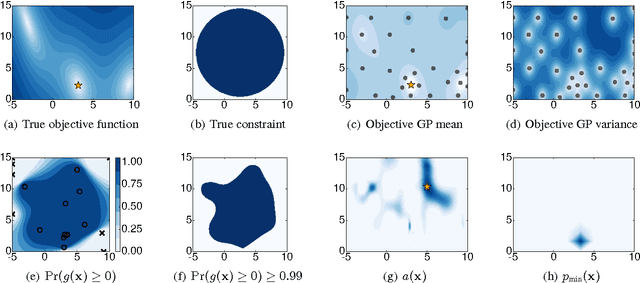

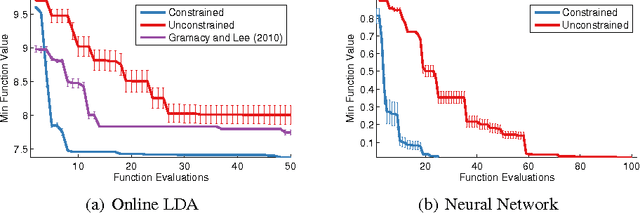
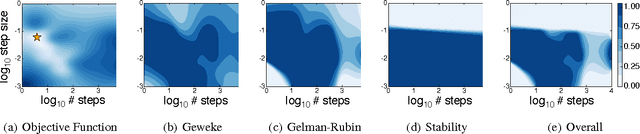
Recent work on Bayesian optimization has shown its effectiveness in global optimization of difficult black-box objective functions. Many real-world optimization problems of interest also have constraints which are unknown a priori. In this paper, we study Bayesian optimization for constrained problems in the general case that noise may be present in the constraint functions, and the objective and constraints may be evaluated independently. We provide motivating practical examples, and present a general framework to solve such problems. We demonstrate the effectiveness of our approach on optimizing the performance of online latent Dirichlet allocation subject to topic sparsity constraints, tuning a neural network given test-time memory constraints, and optimizing Hamiltonian Monte Carlo to achieve maximal effectiveness in a fixed time, subject to passing standard convergence diagnostics.
Learning the Parameters of Determinantal Point Process Kernels
Feb 20, 2014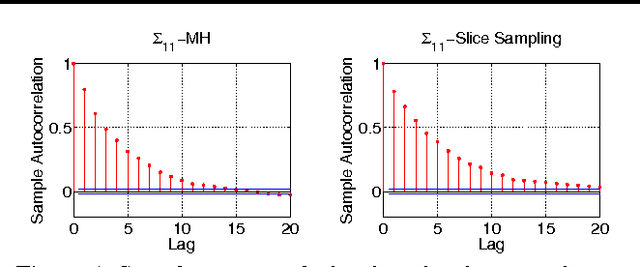
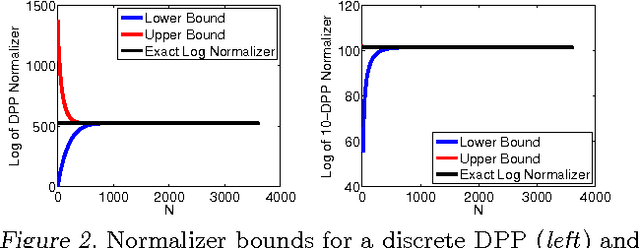
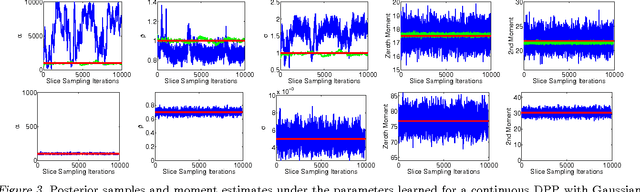
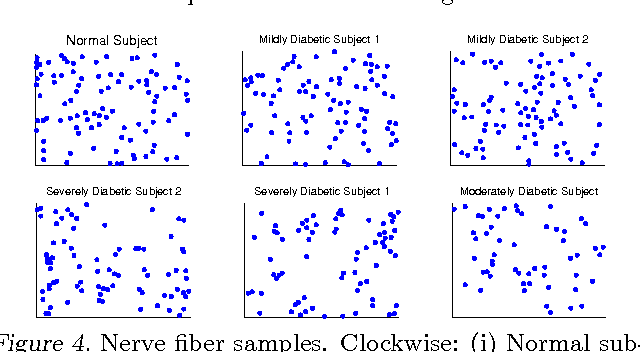
Determinantal point processes (DPPs) are well-suited for modeling repulsion and have proven useful in many applications where diversity is desired. While DPPs have many appealing properties, such as efficient sampling, learning the parameters of a DPP is still considered a difficult problem due to the non-convex nature of the likelihood function. In this paper, we propose using Bayesian methods to learn the DPP kernel parameters. These methods are applicable in large-scale and continuous DPP settings even when the exact form of the eigendecomposition is unknown. We demonstrate the utility of our DPP learning methods in studying the progression of diabetic neuropathy based on spatial distribution of nerve fibers, and in studying human perception of diversity in images.
Learning Ordered Representations with Nested Dropout
Feb 05, 2014

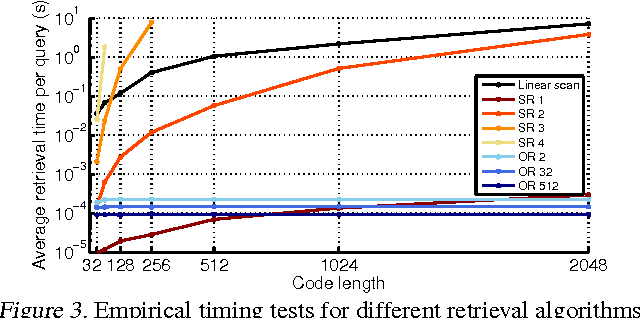

In this paper, we study ordered representations of data in which different dimensions have different degrees of importance. To learn these representations we introduce nested dropout, a procedure for stochastically removing coherent nested sets of hidden units in a neural network. We first present a sequence of theoretical results in the simple case of a semi-linear autoencoder. We rigorously show that the application of nested dropout enforces identifiability of the units, which leads to an exact equivalence with PCA. We then extend the algorithm to deep models and demonstrate the relevance of ordered representations to a number of applications. Specifically, we use the ordered property of the learned codes to construct hash-based data structures that permit very fast retrieval, achieving retrieval in time logarithmic in the database size and independent of the dimensionality of the representation. This allows codes that are hundreds of times longer than currently feasible for retrieval. We therefore avoid the diminished quality associated with short codes, while still performing retrieval that is competitive in speed with existing methods. We also show that ordered representations are a promising way to learn adaptive compression for efficient online data reconstruction.