 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBIOMRC: A Dataset for Biomedical Machine Reading Comprehension
May 13, 2020
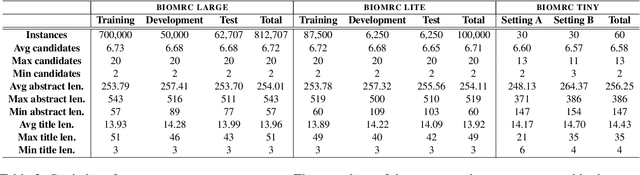
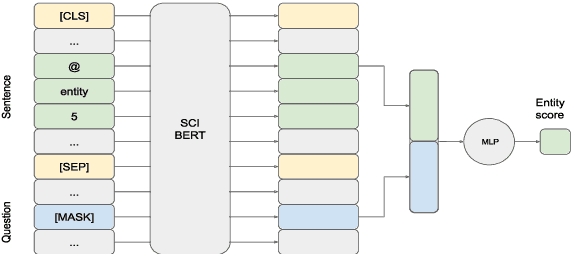
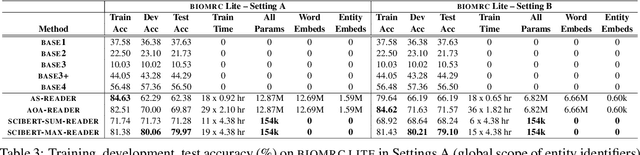
We introduce BIOMRC, a large-scale cloze-style biomedical MRC dataset. Care was taken to reduce noise, compared to the previous BIOREAD dataset of Pappas et al. (2018). Experiments show that simple heuristics do not perform well on the new dataset, and that two neural MRC models that had been tested on BIOREAD perform much better on BIOMRC, indicating that the new dataset is indeed less noisy or at least that its task is more feasible. Non-expert human performance is also higher on the new dataset compared to BIOREAD, and biomedical experts perform even better. We also introduce a new BERT-based MRC model, the best version of which substantially outperforms all other methods tested, reaching or surpassing the accuracy of biomedical experts in some experiments. We make the new dataset available in three different sizes, also releasing our code, and providing a leaderboard.
On Faithfulness and Factuality in Abstractive Summarization
May 02, 2020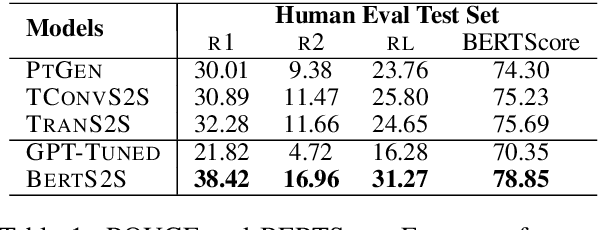

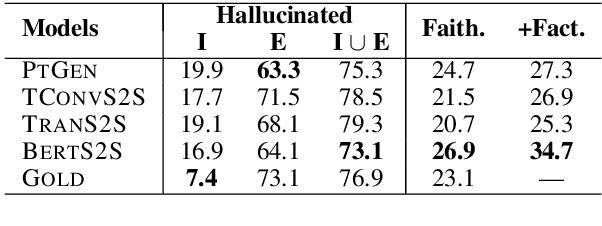
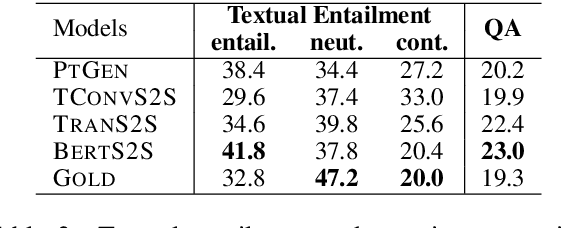
It is well known that the standard likelihood training and approximate decoding objectives in neural text generation models lead to less human-like responses for open-ended tasks such as language modeling and story generation. In this paper we have analyzed limitations of these models for abstractive document summarization and found that these models are highly prone to hallucinate content that is unfaithful to the input document. We conducted a large scale human evaluation of several neural abstractive summarization systems to better understand the types of hallucinations they produce. Our human annotators found substantial amounts of hallucinated content in all model generated summaries. However, our analysis does show that pretrained models are better summarizers not only in terms of raw metrics, i.e., ROUGE, but also in generating faithful and factual summaries as evaluated by humans. Furthermore, we show that textual entailment measures better correlate with faithfulness than standard metrics, potentially leading the way to automatic evaluation metrics as well as training and decoding criteria.
Zero-shot Neural Retrieval via Domain-targeted Synthetic Query Generation
Apr 29, 2020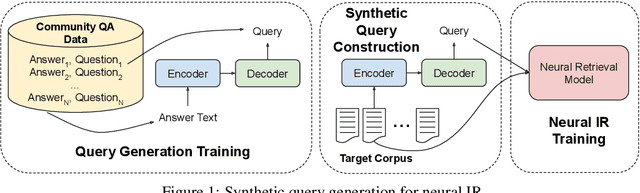

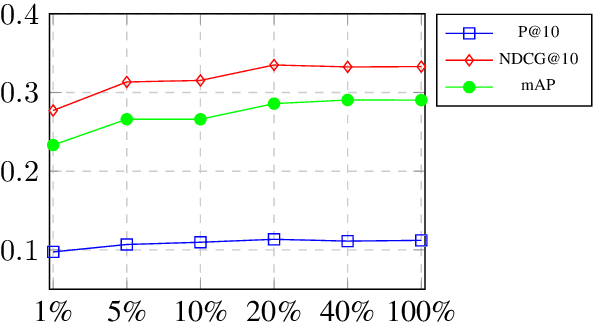
Deep neural scoring models have recently been shown to improve ranking quality on a number of benchmarks (Guo et al., 2016; Daiet al., 2018; MacAvaney et al., 2019; Yanget al., 2019a). However, these methods rely on underlying ad-hoc retrieval systems to generate candidates for scoring, which are rarely neural themselves (Zamani et al., 2018). Re-cent work has shown that the performance of ad-hoc neural retrieval systems can be competitive with a number of baselines (Zamani et al.,2018), potentially leading the way to full end-to-end neural retrieval. A major road-block to the adoption of ad-hoc retrieval models is that they require large supervised training sets to surpass classic term-based techniques, which can be developed from raw corpora. Previous work shows weakly supervised data can yield competitive results, e.g., click data (Dehghaniet al., 2017; Borisov et al., 2016). Unfortunately for many domains, even weakly supervised data can be scarce. In this paper, we pro-pose an approach to zero-shot learning (Xianet al., 2018) for ad-hoc retrieval models that relies on synthetic query generation. Crucially, the query generation system is trained on general domain data, but is applied to documents in the targeted domain. This allows us to create arbitrarily large, yet noisy, query-document relevance pairs that are domain targeted. On a number of benchmarks, we show that this is an effective strategy for building neural retrieval models for specialised domains.
Measuring Domain Portability and ErrorPropagation in Biomedical QA
Sep 24, 2019

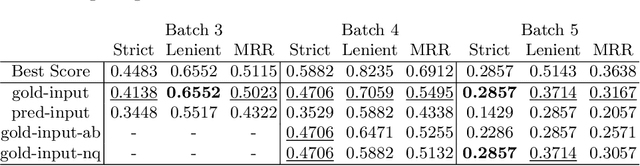

In this work we present Google's submission to the BioASQ 7 biomedical question answering (QA) task (specifically Task 7b, Phase B). The core of our systems are based on BERT QA models, specifically the model of \cite{alberti2019bert}. In this report, and via our submissions, we aimed to investigate two research questions. We start by studying how domain portable are QA systems that have been pre-trained and fine-tuned on general texts, e.g., Wikipedia. We measure this via two submissions. The first is a non-adapted model that uses a public pre-trained BERT model and is fine-tuned on the Natural Questions data set \cite{kwiatkowski2019natural}. The second system takes this non-adapted model and fine-tunes it with the BioASQ training data. Next, we study the impact of error propagation in end-to-end retrieval and QA systems. Again we test this via two submissions. The first uses human annotated relevant documents and snippets as input to the model and the second predicted documents and snippets. Our main findings are that domain specific fine-tuning can benefit Biomedical QA. However, the biggest quality bottleneck is at the retrieval stage, where we see large drops in metrics -- over 10pts absolute -- when using non gold inputs to the QA model.
Embedding Biomedical Ontologies by Jointly Encoding Network Structure and Textual Node Descriptors
Jun 20, 2019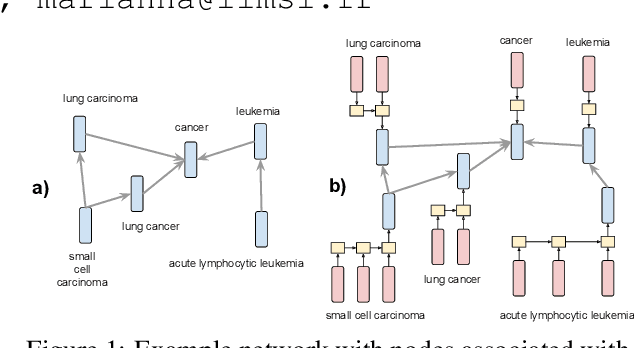
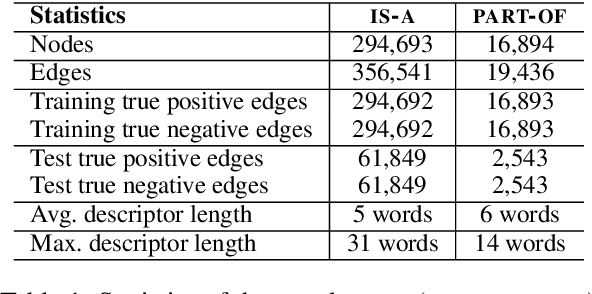
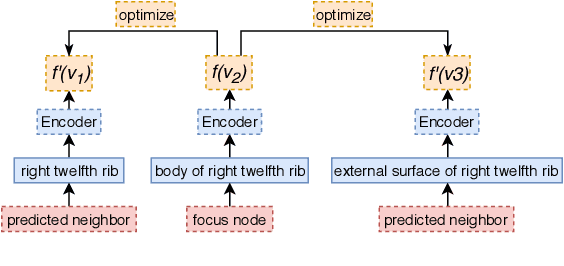
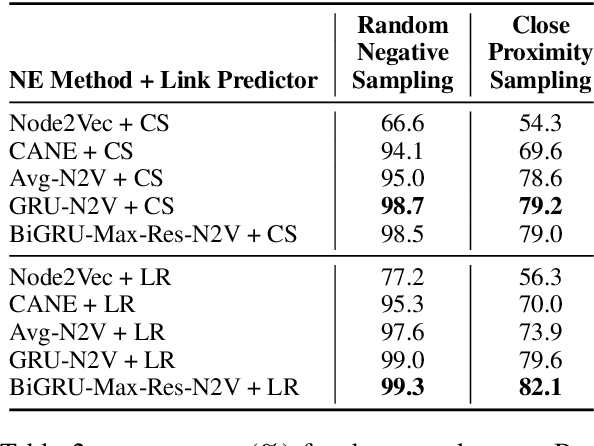
Network Embedding (NE) methods, which map network nodes to low-dimensional feature vectors, have wide applications in network analysis and bioinformatics. Many existing NE methods rely only on network structure, overlooking other information associated with the nodes, e.g., text describing the nodes. Recent attempts to combine the two sources of information only consider local network structure. We extend NODE2VEC, a well-known NE method that considers broader network structure, to also consider textual node descriptors using recurrent neural encoders. Our method is evaluated on link prediction in two networks derived from UMLS. Experimental results demonstrate the effectiveness of the proposed approach compared to previous work.
AUEB at BioASQ 6: Document and Snippet Retrieval
Sep 15, 2018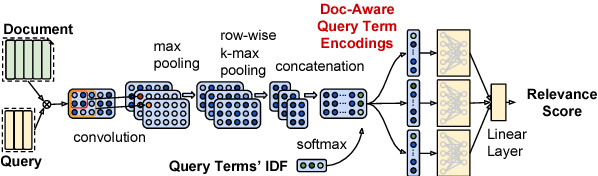
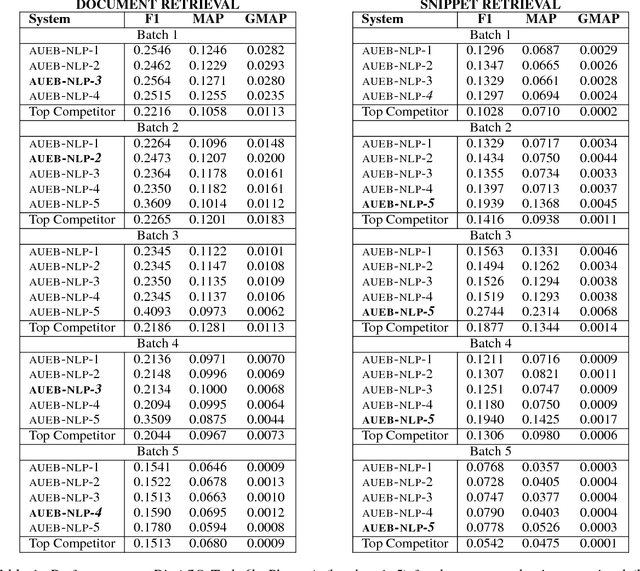
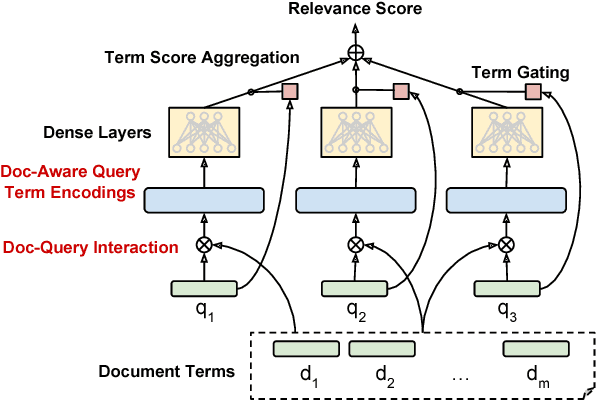
We present AUEB's submissions to the BioASQ 6 document and snippet retrieval tasks (parts of Task 6b, Phase A). Our models use novel extensions to deep learning architectures that operate solely over the text of the query and candidate document/snippets. Our systems scored at the top or near the top for all batches of the challenge, highlighting the effectiveness of deep learning for these tasks.
Deep Relevance Ranking Using Enhanced Document-Query Interactions
Sep 11, 2018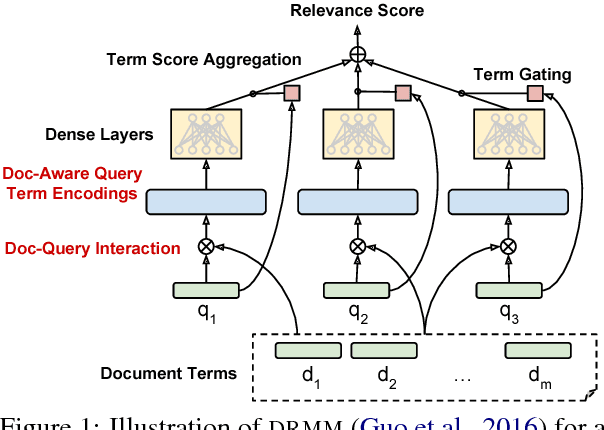
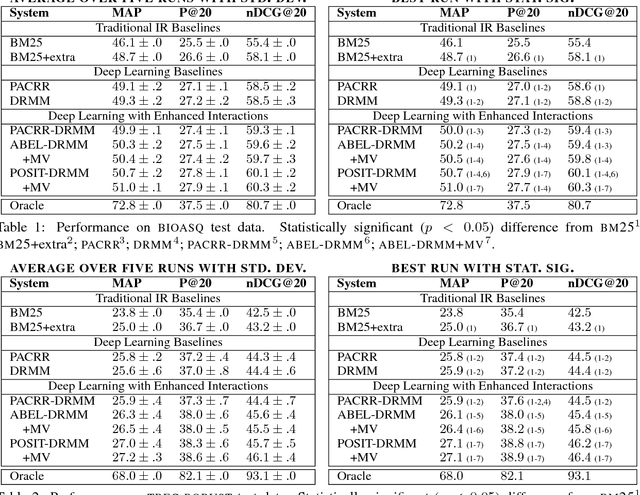
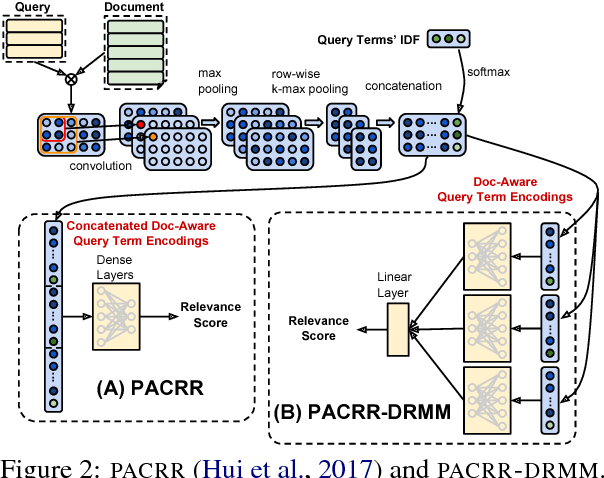
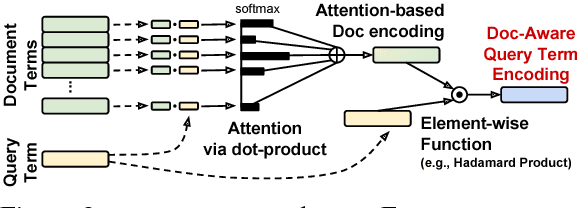
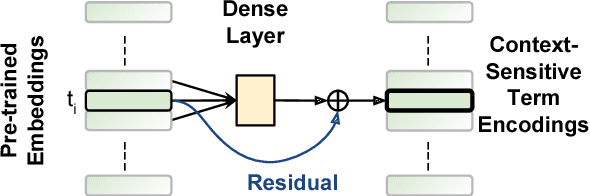
We explore several new models for document relevance ranking, building upon the Deep Relevance Matching Model (DRMM) of Guo et al. (2016). Unlike DRMM, which uses context-insensitive encodings of terms and query-document term interactions, we inject rich context-sensitive encodings throughout our models, inspired by PACRR's (Hui et al., 2017) convolutional n-gram matching features, but extended in several ways including multiple views of query and document inputs. We test our models on datasets from the BIOASQ question answering challenge (Tsatsaronis et al., 2015) and TREC ROBUST 2004 (Voorhees, 2005), showing they outperform BM25-based baselines, DRMM, and PACRR.
Morphosyntactic Tagging with a Meta-BiLSTM Model over Context Sensitive Token Encodings
May 21, 2018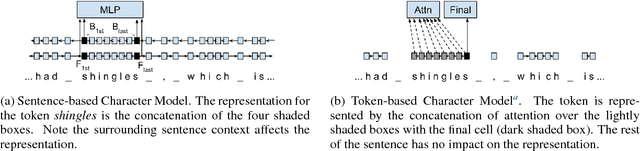
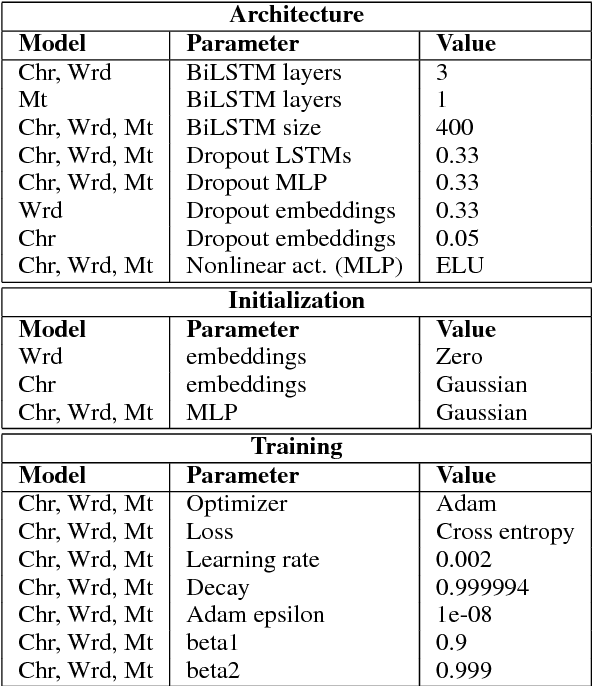
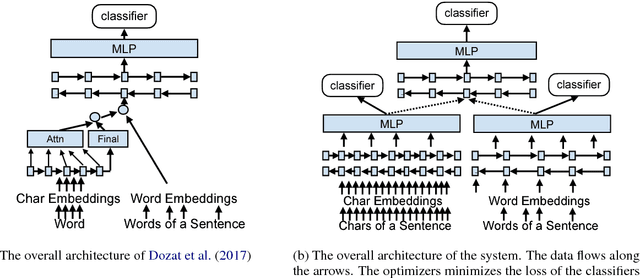
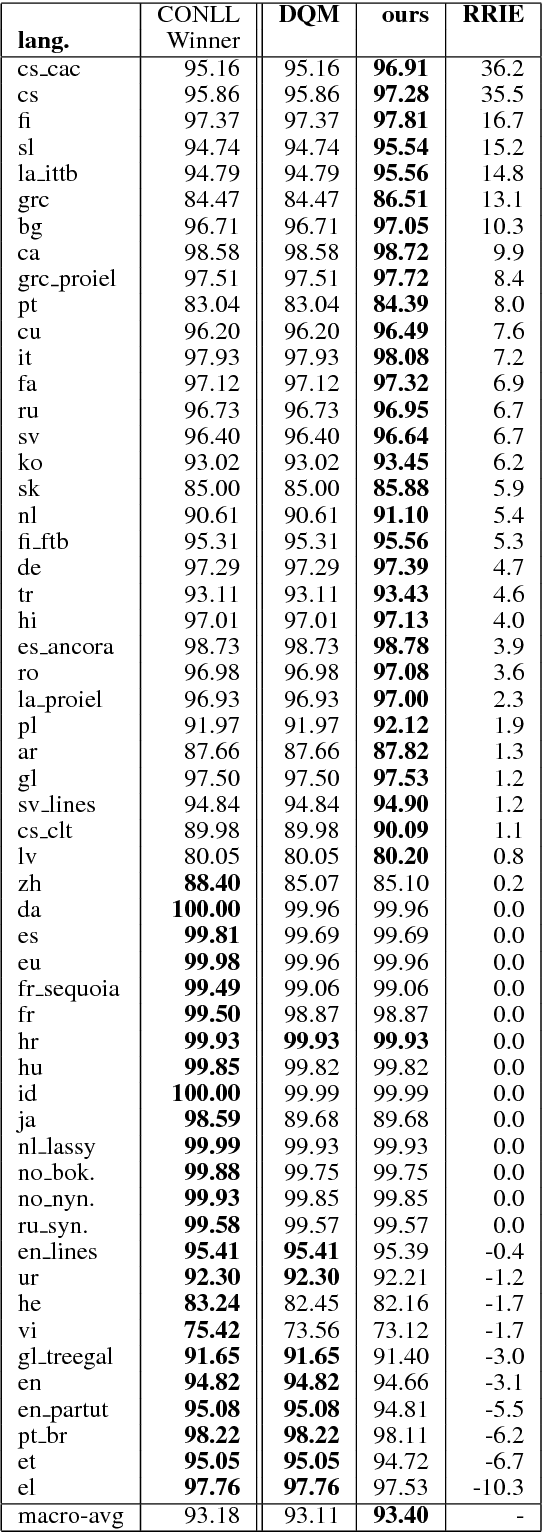
The rise of neural networks, and particularly recurrent neural networks, has produced significant advances in part-of-speech tagging accuracy. One characteristic common among these models is the presence of rich initial word encodings. These encodings typically are composed of a recurrent character-based representation with learned and pre-trained word embeddings. However, these encodings do not consider a context wider than a single word and it is only through subsequent recurrent layers that word or sub-word information interacts. In this paper, we investigate models that use recurrent neural networks with sentence-level context for initial character and word-based representations. In particular we show that optimal results are obtained by integrating these context sensitive representations through synchronized training with a meta-model that learns to combine their states. We present results on part-of-speech and morphological tagging with state-of-the-art performance on a number of languages.
Natural Language Processing with Small Feed-Forward Networks
Aug 01, 2017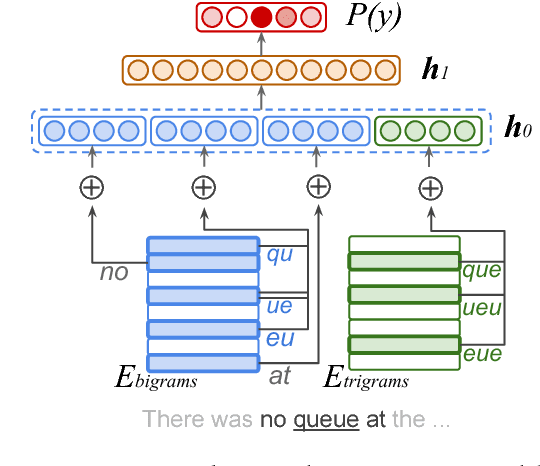
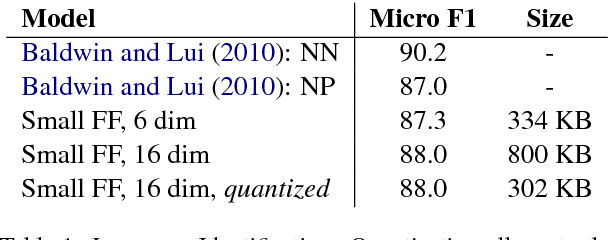
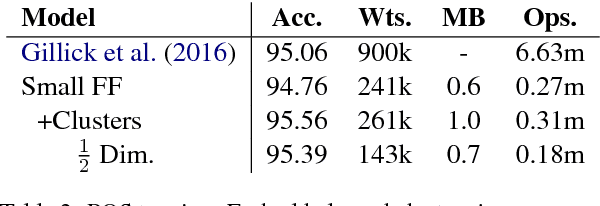
We show that small and shallow feed-forward neural networks can achieve near state-of-the-art results on a range of unstructured and structured language processing tasks while being considerably cheaper in memory and computational requirements than deep recurrent models. Motivated by resource-constrained environments like mobile phones, we showcase simple techniques for obtaining such small neural network models, and investigate different tradeoffs when deciding how to allocate a small memory budget.
Static and Dynamic Feature Selection in Morphosyntactic Analyzers
Mar 21, 2016


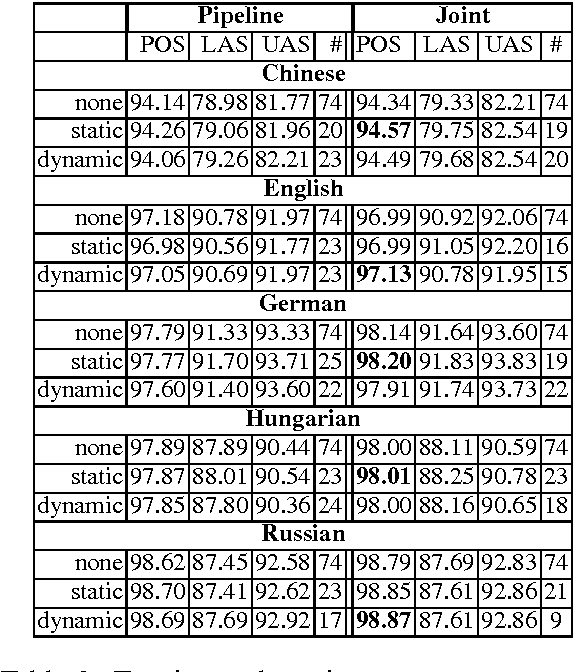
We study the use of greedy feature selection methods for morphosyntactic tagging under a number of different conditions. We compare a static ordering of features to a dynamic ordering based on mutual information statistics, and we apply the techniques to standalone taggers as well as joint systems for tagging and parsing. Experiments on five languages show that feature selection can result in more compact models as well as higher accuracy under all conditions, but also that a dynamic ordering works better than a static ordering and that joint systems benefit more than standalone taggers. We also show that the same techniques can be used to select which morphosyntactic categories to predict in order to maximize syntactic accuracy in a joint system. Our final results represent a substantial improvement of the state of the art for several languages, while at the same time reducing both the number of features and the running time by up to 80% in some cases.