 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of Pre-training Text in Black-box LLMs
Jun 24, 2025Detecting whether a given text is a member of the pre-training data of Large Language Models (LLMs) is crucial for ensuring data privacy and copyright protection. Most existing methods rely on the LLM's hidden information (e.g., model parameters or token probabilities), making them ineffective in the black-box setting, where only input and output texts are accessible. Although some methods have been proposed for the black-box setting, they rely on massive manual efforts such as designing complicated questions or instructions. To address these issues, we propose VeilProbe, the first framework for automatically detecting LLMs' pre-training texts in a black-box setting without human intervention. VeilProbe utilizes a sequence-to-sequence mapping model to infer the latent mapping feature between the input text and the corresponding output suffix generated by the LLM. Then it performs the key token perturbations to obtain more distinguishable membership features. Additionally, considering real-world scenarios where the ground-truth training text samples are limited, a prototype-based membership classifier is introduced to alleviate the overfitting issue. Extensive evaluations on three widely used datasets demonstrate that our framework is effective and superior in the black-box setting.
The MBPEP: a deep ensemble pruning algorithm providing high quality uncertainty prediction
Feb 25, 2019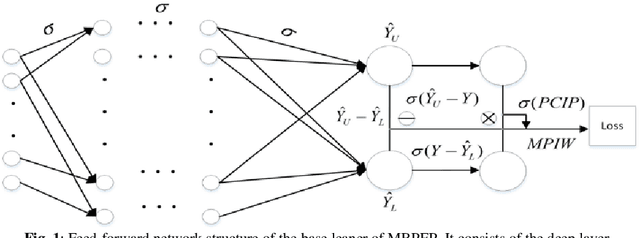
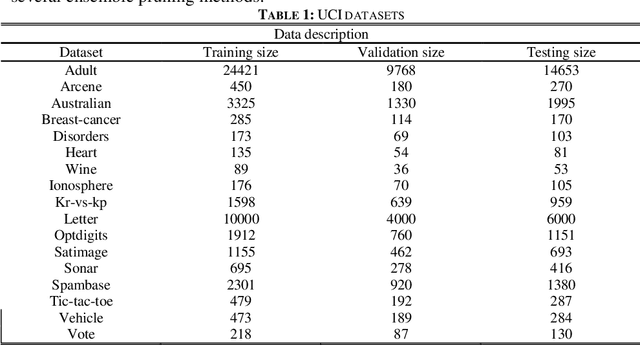
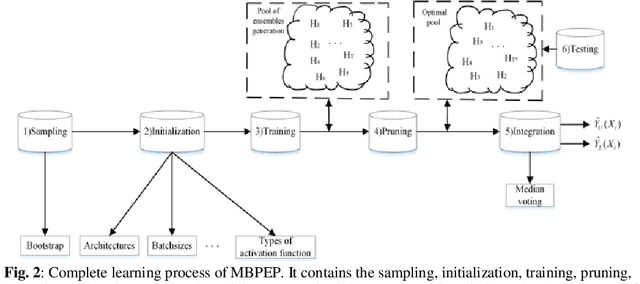
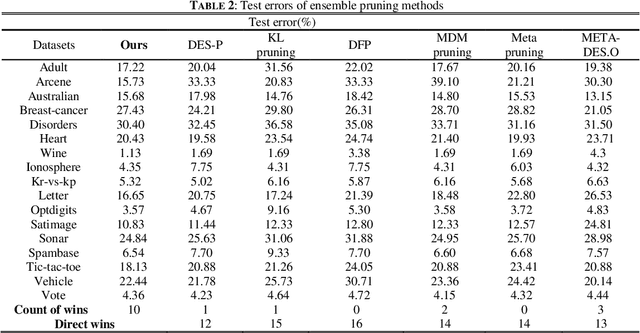
Machine learning algorithms have been effectively applied into various real world tasks. However, it is difficult to provide high-quality machine learning solutions to accommodate an unknown distribution of input datasets; this difficulty is called the uncertainty prediction problems. In this paper, a margin-based Pareto deep ensemble pruning (MBPEP) model is proposed. It achieves the high-quality uncertainty estimation with a small value of the prediction interval width (MPIW) and a high confidence of prediction interval coverage probability (PICP) by using deep ensemble networks. In addition to these networks, unique loss functions are proposed, and these functions make the sub-learners available for standard gradient descent learning. Furthermore, the margin criterion fine-tuning-based Pareto pruning method is introduced to optimize the ensembles. Several experiments including predicting uncertainties of classification and regression are conducted to analyze the performance of MBPEP. The experimental results show that MBPEP achieves a small interval width and a low learning error with an optimal number of ensembles. For the real-world problems, MBPEP performs well on input datasets with unknown distributions datasets incomings and improves learning performance on a multi task problem when compared to that of each single model.
* 20 pages, 7 figures