 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Embeddings for Detecting Individual Symptoms of Depression
Jun 25, 2024



Depression, a prevalent mental health disorder impacting millions globally, demands reliable assessment systems. Unlike previous studies that focus solely on either detecting depression or predicting its severity, our work identifies individual symptoms of depression while also predicting its severity using speech input. We leverage self-supervised learning (SSL)-based speech models to better utilize the small-sized datasets that are frequently encountered in this task. Our study demonstrates notable performance improvements by utilizing SSL embeddings compared to conventional speech features. We compare various types of SSL pretrained models to elucidate the type of speech information (semantic, speaker, or prosodic) that contributes the most in identifying different symptoms. Additionally, we evaluate the impact of combining multiple SSL embeddings on performance. Furthermore, we show the significance of multi-task learning for identifying depressive symptoms effectively.
Predicting Individual Depression Symptoms from Acoustic Features During Speech
Jun 23, 2024



Current automatic depression detection systems provide predictions directly without relying on the individual symptoms/items of depression as denoted in the clinical depression rating scales. In contrast, clinicians assess each item in the depression rating scale in a clinical setting, thus implicitly providing a more detailed rationale for a depression diagnosis. In this work, we make a first step towards using the acoustic features of speech to predict individual items of the depression rating scale before obtaining the final depression prediction. For this, we use convolutional (CNN) and recurrent (long short-term memory (LSTM)) neural networks. We consider different approaches to learning the temporal context of speech. Further, we analyze two variants of voting schemes for individual item prediction and depression detection. We also include an animated visualization that shows an example of item prediction over time as the speech progresses.
Test-Time Training for Depression Detection
Apr 07, 2024



Previous works on depression detection use datasets collected in similar environments to train and test the models. In practice, however, the train and test distributions cannot be guaranteed to be identical. Distribution shifts can be introduced due to variations such as recording environment (e.g., background noise) and demographics (e.g., gender, age, etc). Such distributional shifts can surprisingly lead to severe performance degradation of the depression detection models. In this paper, we analyze the application of test-time training (TTT) to improve robustness of models trained for depression detection. When compared to regular testing of the models, we find TTT can significantly improve the robustness of the model under a variety of distributional shifts introduced due to: (a) background-noise, (b) gender-bias, and (c) data collection and curation procedure (i.e., train and test samples are from separate datasets).
Significance of Speaker Embeddings and Temporal Context for Depression Detection
Jul 24, 2021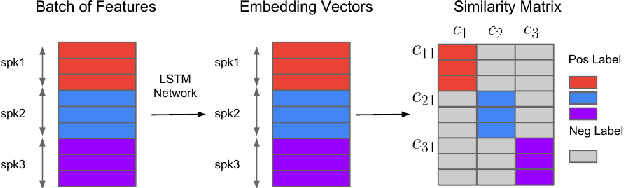
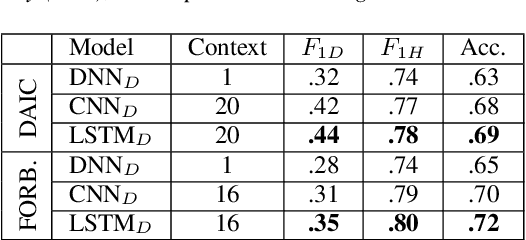
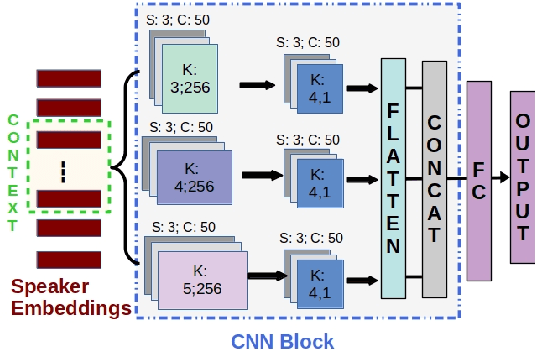
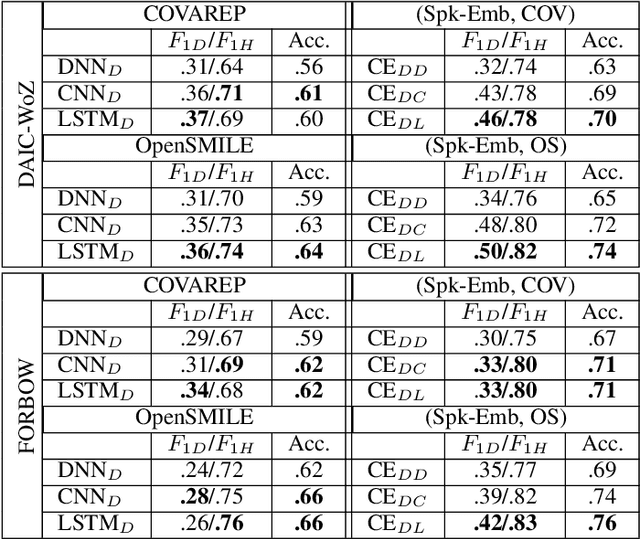
Depression detection from speech has attracted a lot of attention in recent years. However, the significance of speaker-specific information in depression detection has not yet been explored. In this work, we analyze the significance of speaker embeddings for the task of depression detection from speech. Experimental results show that the speaker embeddings provide important cues to achieve state-of-the-art performance in depression detection. We also show that combining conventional OpenSMILE and COVAREP features, which carry complementary information, with speaker embeddings further improves the depression detection performance. The significance of temporal context in the training of deep learning models for depression detection is also analyzed in this paper.
Multimodal Deep Learning for Mental Disorders Prediction from Audio Speech Samples
Sep 12, 2019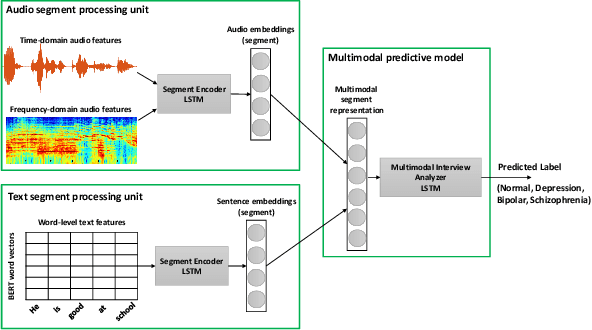
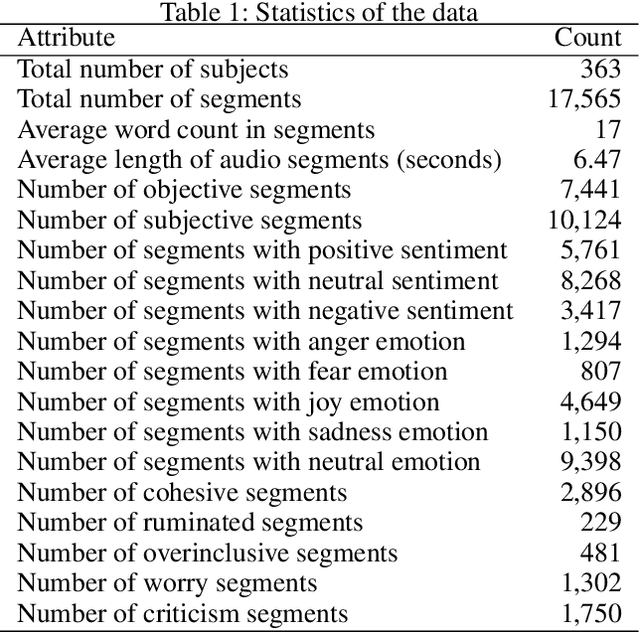
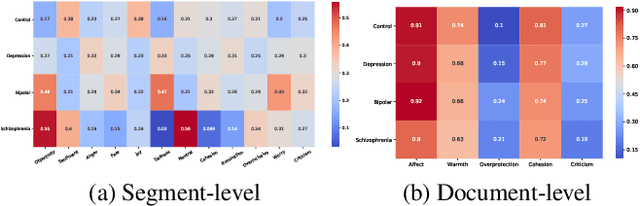
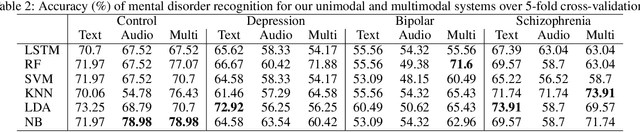
Key features of mental illnesses are reflected in speech. Our research focuses on designing a multimodal deep learning structure that automatically extracts salient features from recorded speech samples for predicting various mental disorders including depression, bipolar, and schizophrenia. We adopt a variety of pre-trained models to extract embeddings from both audio and text segments. We use several state-of-the-art embedding techniques including BERT, FastText, and Doc2VecC for the text representation learning and WaveNet and VGG-ish models for audio encoding. We also leverage huge auxiliary emotion-labeled text and audio corpora to train emotion-specific embeddings and use transfer learning in order to address the problem of insufficient annotated multimodal data available. All these embeddings are then combined into a joint representation in a multimodal fusion layer and finally a recurrent neural network is used to predict the mental disorder. Our results show that mental disorders can be predicted with acceptable accuracy through multimodal analysis of clinical interviews.