 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Video Compression with Domain Transfer
May 13, 2026Content-adaptive compression has always been a key direction in neural video coding (NVC), aiming to mitigate the domain gap between training and testing data. Such gaps often arise from distributional discrepancies between training and inference data, which may cause noticeable performance degradation when the testing content differs from the training distribution. To tackle this challenge, we propose DCVC-DT, a domain transfer enhanced neural video compression framework. Specifically, we design a lightweight online domain transfer (DT) mechanism that dynamically adapts the encoded latent representation during inference, effectively bridging the domain gap without modifying the encoder or decoder parameters. In addition, we develop a frame-level dynamic RD (Rate and Distortion) adjustment scheme that actively regulates the ratio of R and D in the loss function based on quality fluctuation, thereby improving rate-distortion performance. Extensive experiments demonstrate that DCVC-DT achieves up to 6.21% bitrate savings over the baseline DCVC-DC, while significantly enhancing generalization to unseen testing data and alleviating error propagation. Our code is available at https://github.com/SunnyMass/DCVC-DT.
Towards Modality Transferable Visual Information Representation with Optimal Model Compression
Aug 13, 2020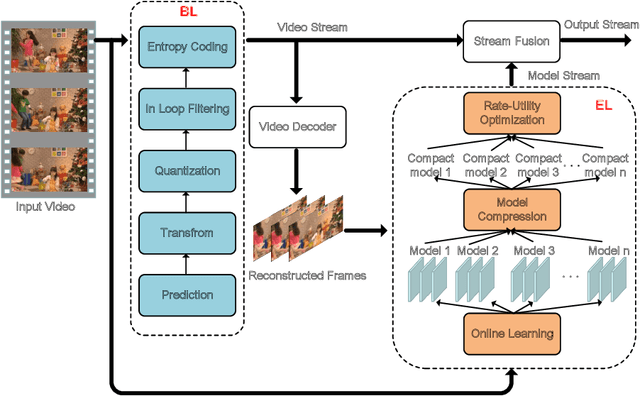
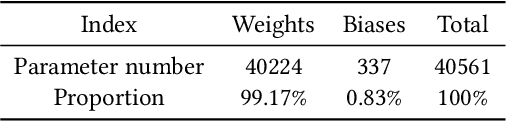
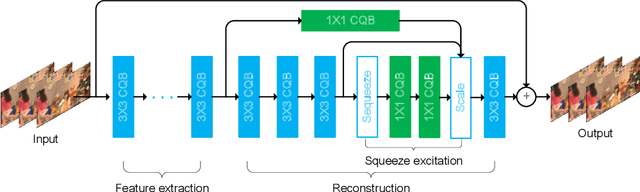

Compactly representing the visual signals is of fundamental importance in various image/video-centered applications. Although numerous approaches were developed for improving the image and video coding performance by removing the redundancies within visual signals, much less work has been dedicated to the transformation of the visual signals to another well-established modality for better representation capability. In this paper, we propose a new scheme for visual signal representation that leverages the philosophy of transferable modality. In particular, the deep learning model, which characterizes and absorbs the statistics of the input scene with online training, could be efficiently represented in the sense of rate-utility optimization to serve as the enhancement layer in the bitstream. As such, the overall performance can be further guaranteed by optimizing the new modality incorporated. The proposed framework is implemented on the state-of-the-art video coding standard (i.e., versatile video coding), and significantly better representation capability has been observed based on extensive evaluations.