 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneric Preferences over Subsets of Structured Objects
Jan 15, 2014
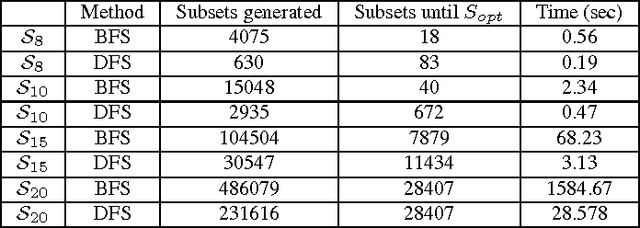
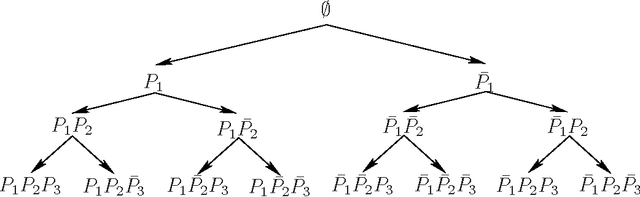
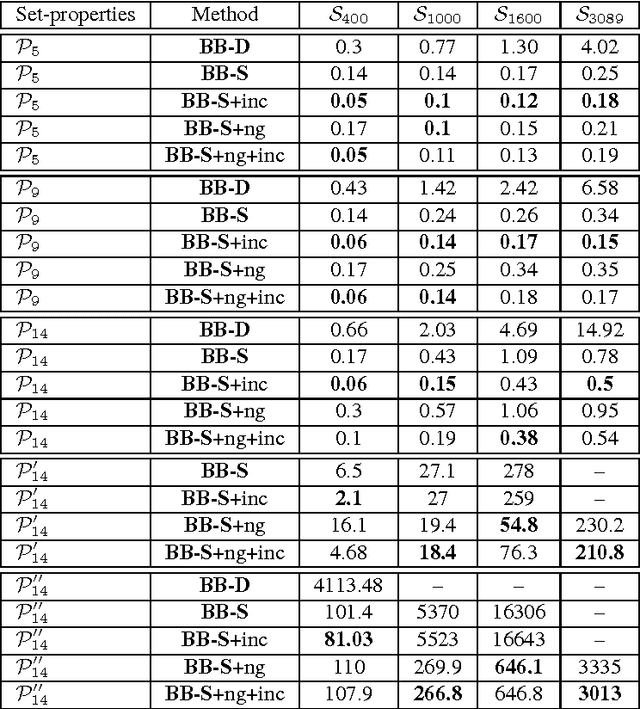
Various tasks in decision making and decision support systems require selecting a preferred subset of a given set of items. Here we focus on problems where the individual items are described using a set of characterizing attributes, and a generic preference specification is required, that is, a specification that can work with an arbitrary set of items. For example, preferences over the content of an online newspaper should have this form: At each viewing, the newspaper contains a subset of the set of articles currently available. Our preference specification over this subset should be provided offline, but we should be able to use it to select a subset of any currently available set of articles, e.g., based on their tags. We present a general approach for lifting formalisms for specifying preferences over objects with multiple attributes into ones that specify preferences over subsets of such objects. We also show how we can compute an optimal subset given such a specification in a relatively efficient manner. We provide an empirical evaluation of the approach as well as some worst-case complexity results.
A Heuristic Search Approach to Planning with Continuous Resources in Stochastic Domains
Jan 15, 2014
We consider the problem of optimal planning in stochastic domains with resource constraints, where the resources are continuous and the choice of action at each step depends on resource availability. We introduce the HAO* algorithm, a generalization of the AO* algorithm that performs search in a hybrid state space that is modeled using both discrete and continuous state variables, where the continuous variables represent monotonic resources. Like other heuristic search algorithms, HAO* leverages knowledge of the start state and an admissible heuristic to focus computational effort on those parts of the state space that could be reached from the start state by following an optimal policy. We show that this approach is especially effective when resource constraints limit how much of the state space is reachable. Experimental results demonstrate its effectiveness in the domain that motivates our research: automated planning for planetary exploration rovers.
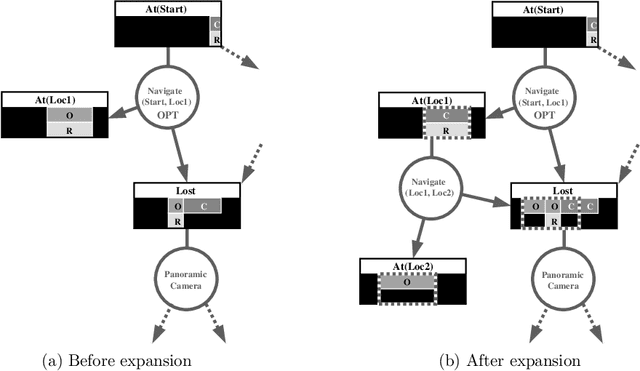
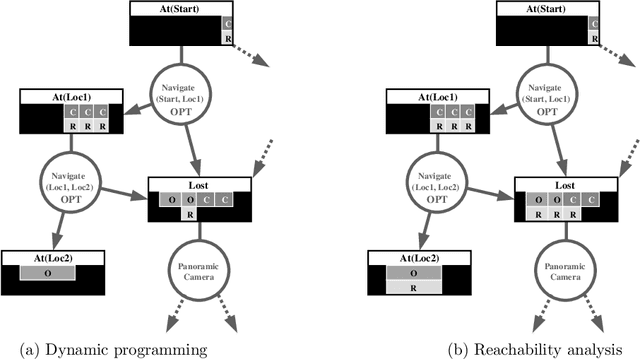
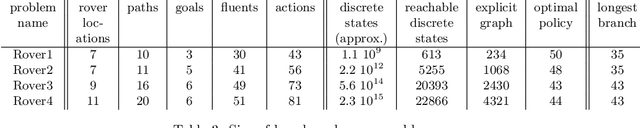
Structured Reachability Analysis for Markov Decision Processes
Apr 23, 2013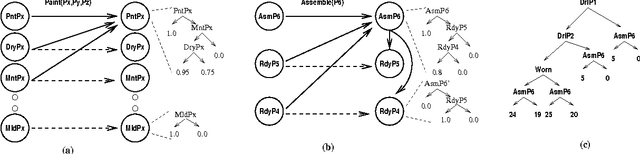
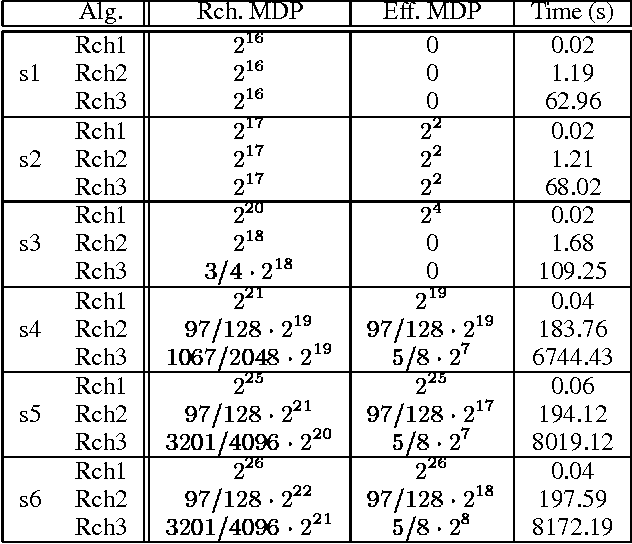
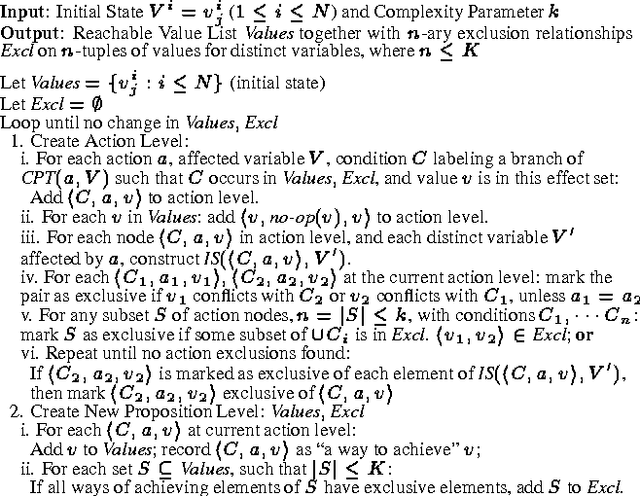
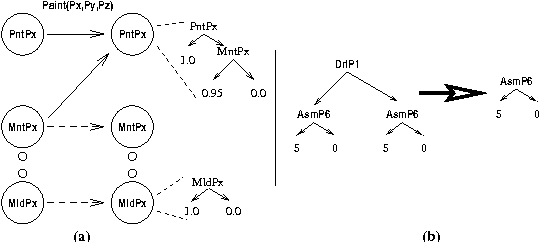
Recent research in decision theoretic planning has focussed on making the solution of Markov decision processes (MDPs) more feasible. We develop a family of algorithms for structured reachability analysis of MDPs that are suitable when an initial state (or set of states) is known. Using compact, structured representations of MDPs (e.g., Bayesian networks), our methods, which vary in the tradeoff between complexity and accuracy, produce structured descriptions of (estimated) reachable states that can be used to eliminate variables or variable values from the problem description, reducing the size of the MDP and making it easier to solve. One contribution of our work is the extension of ideas from GRAPHPLAN to deal with the distributed nature of action representations typically embodied within Bayes nets and the problem of correlated action effects. We also demonstrate that our algorithm can be made more complete by using k-ary constraints instead of binary constraints. Another contribution is the illustration of how the compact representation of reachability constraints can be exploited by several existing (exact and approximate) abstraction algorithms for MDPs.
Reasoning With Conditional Ceteris Paribus Preference Statem
Jan 23, 2013
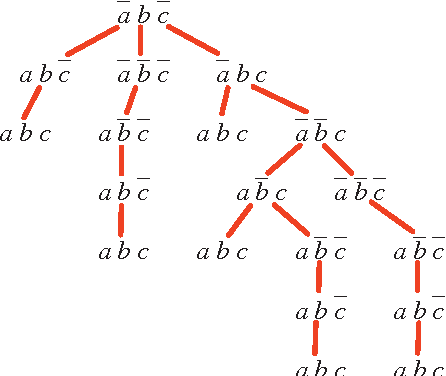
In many domains it is desirable to assess the preferences of users in a qualitative rather than quantitative way. Such representations of qualitative preference orderings form an importnat component of automated decision tools. We propose a graphical representation of preferences that reflects conditional dependence and independence of preference statements under a ceteris paribus (all else being equal) interpretation. Such a representation is ofetn compact and arguably natural. We describe several search algorithms for dominance testing based on this representation; these algorithms are quite effective, especially in specific network topologies, such as chain-and tree- structured networks, as well as polytrees.
UCP-Networks: A Directed Graphical Representation of Conditional Utilities
Jan 10, 2013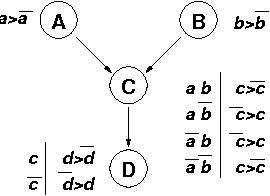
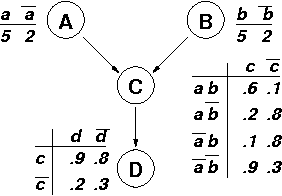
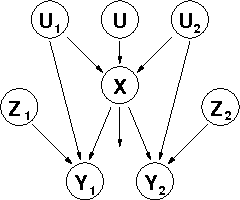
We propose a new directed graphical representation of utility functions, called UCP-networks, that combines aspects of two existing graphical models: generalized additive models and CP-networks. The network decomposes a utility function into a number of additive factors, with the directionality of the arcs reflecting conditional dependence of preference statements - in the underlying (qualitative) preference ordering - under a {em ceteris paribus} (all else being equal) interpretation. This representation is arguably natural in many settings. Furthermore, the strong CP-semantics ensures that computation of optimization and dominance queries is very efficient. We also demonstrate the value of this representation in decision making. Finally, we describe an interactive elicitation procedure that takes advantage of the linear nature of the constraints on "`tradeoff weights" imposed by a UCP-network. This procedure allows the network to be refined until the regret of the decision with minimax regret (with respect to the incompletely specified utility function) falls below a specified threshold (e.g., the cost of further questioning.
Introducing Variable Importance Tradeoffs into CP-Nets
Dec 12, 2012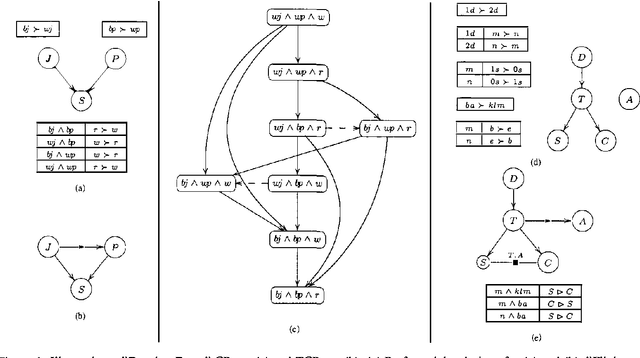

The ability to make decisions and to assess potential courses of action is a corner-stone of many AI applications, and usually this requires explicit information about the decision-maker s preferences. IN many applications, preference elicitation IS a serious bottleneck.The USER either does NOT have the time, the knowledge, OR the expert support required TO specify complex multi - attribute utility functions. IN such cases, a method that IS based ON intuitive, yet expressive, preference statements IS required. IN this paper we suggest the USE OF TCP - nets, an enhancement OF CP - nets, AS a tool FOR representing, AND reasoning about qualitative preference statements.We present AND motivate this framework, define its semantics, AND show how it can be used TO perform constrained optimization.
Exploiting Uniform Assignments in First-Order MPE
Oct 16, 2012
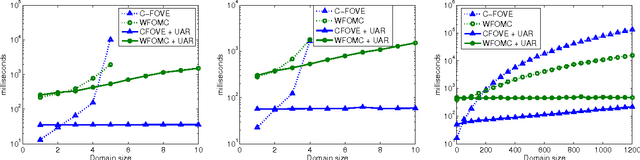
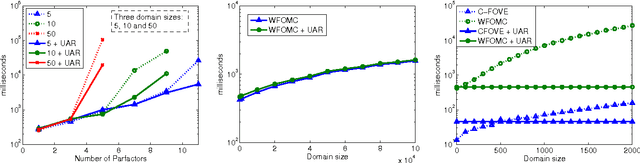
The MPE (Most Probable Explanation) query plays an important role in probabilistic inference. MPE solution algorithms for probabilistic relational models essentially adapt existing belief assessment method, replacing summation with maximization. But the rich structure and symmetries captured by relational models together with the properties of the maximization operator offer an opportunity for additional simplification with potentially significant computational ramifications. Specifically, these models often have groups of variables that define symmetric distributions over some population of formulas. The maximizing choice for different elements of this group is the same. If we can realize this ahead of time, we can significantly reduce the size of the model by eliminating a potentially significant portion of random variables. This paper defines the notion of uniformly assigned and partially uniformly assigned sets of variables, shows how one can recognize these sets efficiently, and how the model can be greatly simplified once we recognize them, with little computational effort. We demonstrate the effectiveness of these ideas empirically on a number of models.
Compact Value-Function Representations for Qualitative Preferences
Jul 11, 2012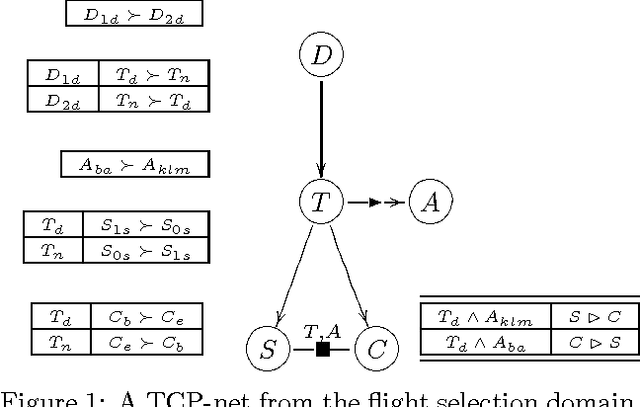
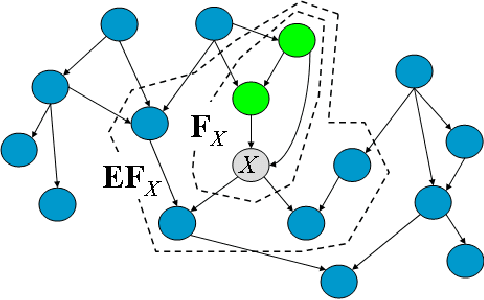
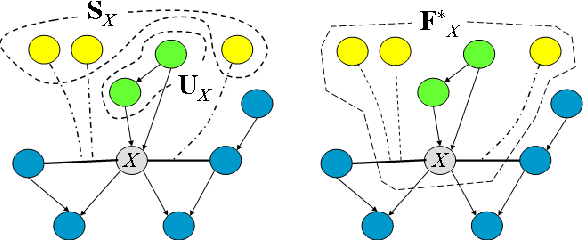
We consider the challenge of preference elicitation in systems that help users discover the most desirable item(s) within a given database. Past work on preference elicitation focused on structured models that provide a factored representation of users' preferences. Such models require less information to construct and support efficient reasoning algorithms. This paper makes two substantial contributions to this area: (1) Strong representation theorems for factored value functions. (2) A methodology that utilizes our representation results to address the problem of optimal item selection.
Extended Lifted Inference with Joint Formulas
Feb 14, 2012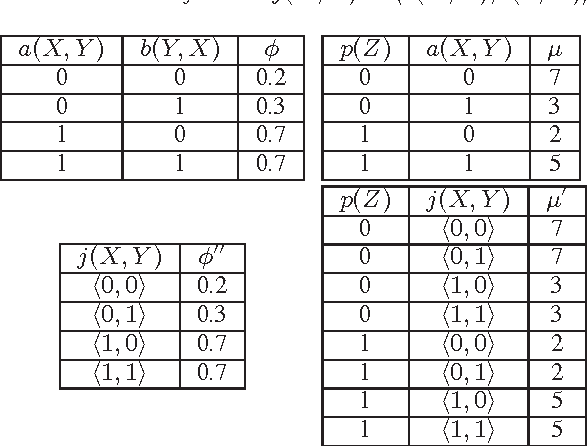
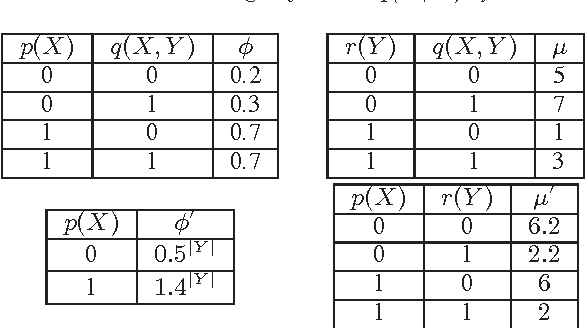
The First-Order Variable Elimination (FOVE) algorithm allows exact inference to be applied directly to probabilistic relational models, and has proven to be vastly superior to the application of standard inference methods on a grounded propositional model. Still, FOVE operators can be applied under restricted conditions, often forcing one to resort to propositional inference. This paper aims to extend the applicability of FOVE by providing two new model conversion operators: the first and the primary is joint formula conversion and the second is just-different counting conversion. These new operations allow efficient inference methods to be applied directly on relational models, where no existing efficient method could be applied hitherto. In addition, aided by these capabilities, we show how to adapt FOVE to provide exact solutions to Maximum Expected Utility (MEU) queries over relational models for decision under uncertainty. Experimental evaluations show our algorithms to provide significant speedup over the alternatives.