 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReviving ConvNeXt for Efficient Convolutional Diffusion Models
Mar 10, 2026Recent diffusion models increasingly favor Transformer backbones, motivated by the remarkable scalability of fully attentional architectures. Yet the locality bias, parameter efficiency, and hardware friendliness--the attributes that established ConvNets as the efficient vision backbone--have seen limited exploration in modern generative modeling. Here we introduce the fully convolutional diffusion model (FCDM), a model having a backbone similar to ConvNeXt, but designed for conditional diffusion modeling. We find that using only 50% of the FLOPs of DiT-XL/2, FCDM-XL achieves competitive performance with 7$\times$ and 7.5$\times$ fewer training steps at 256$\times$256 and 512$\times$512 resolutions, respectively. Remarkably, FCDM-XL can be trained on a 4-GPU system, highlighting the exceptional training efficiency of our architecture. Our results demonstrate that modern convolutional designs provide a competitive and highly efficient alternative for scaling diffusion models, reviving ConvNeXt as a simple yet powerful building block for efficient generative modeling.
Spectrogram Feature Losses for Music Source Separation
Jan 18, 2019



In this paper we study deep learning-based music source separation, and explore using an alternative loss to the standard spectrogram pixel-level L2 loss for model training. Our main contribution is in demonstrating that adding a high-level feature loss term, extracted from the spectrograms using a VGG net, can improve separation quality vis-a-vis a pure pixel-level loss. We show this improvement in the context of the MMDenseNet, a State-of-the-Art deep learning model for this task, for the extraction of drums and vocal sounds from songs in the musdb18 database, covering a broad range of western music genres. We believe that this finding can be generalized and applied to broader machine learning-based systems in the audio domain.
Unsupervised Deep Representations for Learning Audience Facial Behaviors
May 10, 2018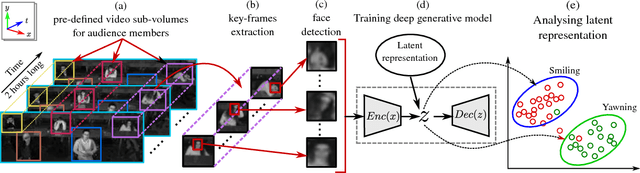
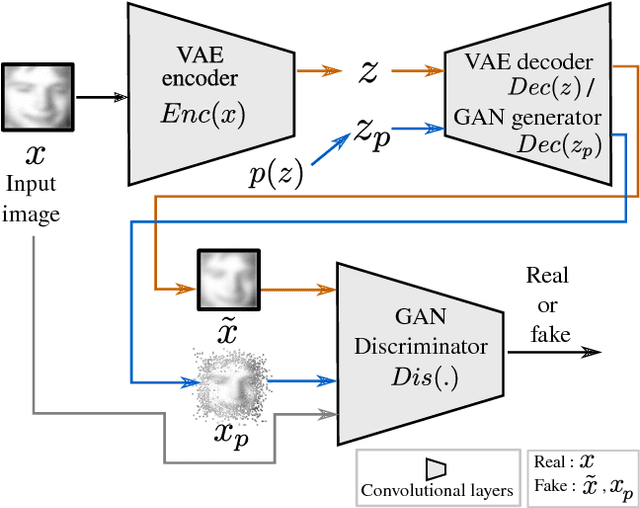

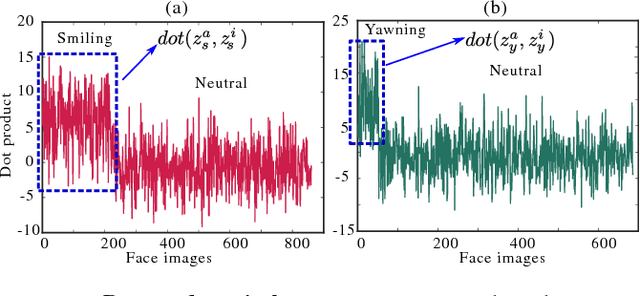
In this paper, we present an unsupervised learning approach for analyzing facial behavior based on a deep generative model combined with a convolutional neural network (CNN). We jointly train a variational auto-encoder (VAE) and a generative adversarial network (GAN) to learn a powerful latent representation from footage of audiences viewing feature-length movies. We show that the learned latent representation successfully encodes meaningful signatures of behaviors related to audience engagement (smiling & laughing) and disengagement (yawning). Our results provide a proof of concept for a more general methodology for annotating hard-to-label multimedia data featuring sparse examples of signals of interest.