 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVuyko Mistral: Adapting LLMs for Low-Resource Dialectal Translation
Jun 09, 2025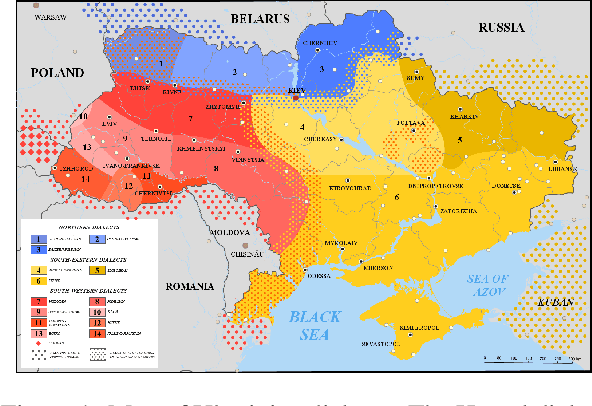
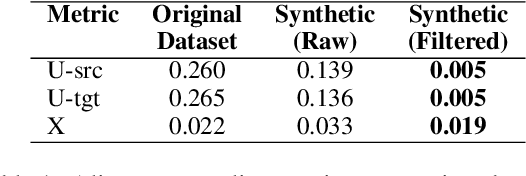
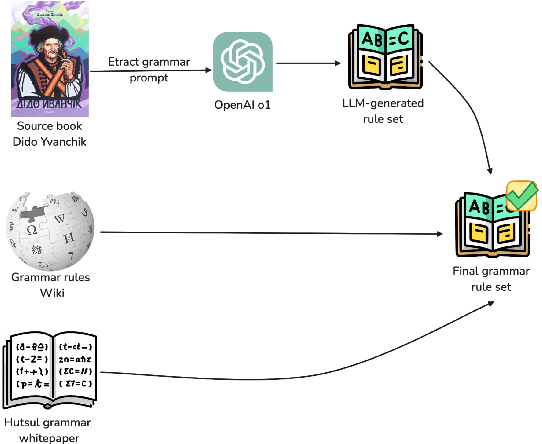

In this paper we introduce the first effort to adapt large language models (LLMs) to the Ukrainian dialect (in our case Hutsul), a low-resource and morphologically complex dialect spoken in the Carpathian Highlands. We created a parallel corpus of 9852 dialect-to-standard Ukrainian sentence pairs and a dictionary of 7320 dialectal word mappings. We also addressed data shortage by proposing an advanced Retrieval-Augmented Generation (RAG) pipeline to generate synthetic parallel translation pairs, expanding the corpus with 52142 examples. We have fine-tuned multiple open-source LLMs using LoRA and evaluated them on a standard-to-dialect translation task, also comparing with few-shot GPT-4o translation. In the absence of human annotators, we adopt a multi-metric evaluation strategy combining BLEU, chrF++, TER, and LLM-based judgment (GPT-4o). The results show that even small(7B) finetuned models outperform zero-shot baselines such as GPT-4o across both automatic and LLM-evaluated metrics. All data, models, and code are publicly released at: https://github.com/woters/vuyko-hutsul
Evaluating Quality of Answers for Retrieval-Augmented Generation: A Strong LLM Is All You Need
Jun 26, 2024



We present a comprehensive evaluation of answer quality in Retrieval-Augmented Generation (RAG) applications using vRAG-Eval, a novel grading system that is designed to assess correctness, completeness, and honesty. We further map the grading of quality aspects aforementioned into a binary score, indicating an accept or reject decision, mirroring the intuitive "thumbs-up" or "thumbs-down" gesture commonly used in chat applications. This approach suits factual business settings where a clear decision opinion is essential. Our assessment applies vRAG-Eval to two Large Language Models (LLMs), evaluating the quality of answers generated by a vanilla RAG application. We compare these evaluations with human expert judgments and find a substantial alignment between GPT-4's assessments and those of human experts, reaching 83% agreement on accept or reject decisions. This study highlights the potential of LLMs as reliable evaluators in closed-domain, closed-ended settings, particularly when human evaluations require significant resources.