 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVuyko Mistral: Adapting LLMs for Low-Resource Dialectal Translation
Jun 09, 2025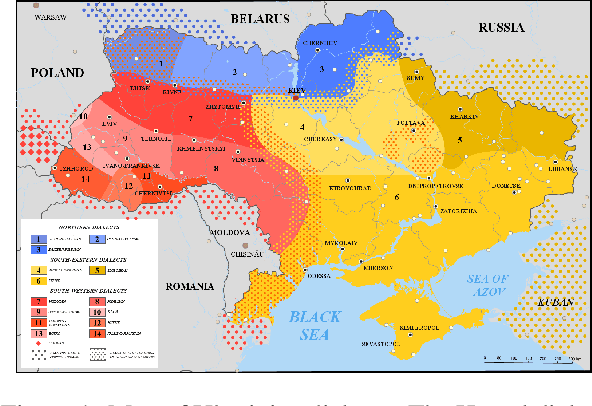
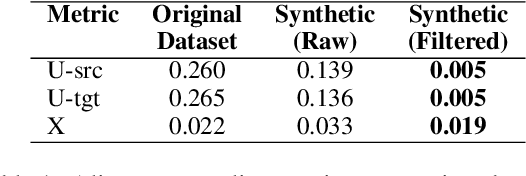
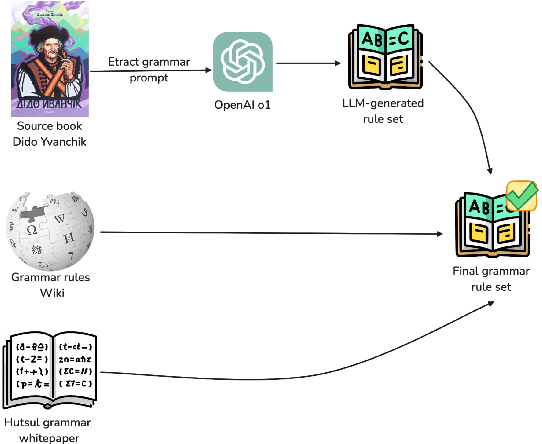

In this paper we introduce the first effort to adapt large language models (LLMs) to the Ukrainian dialect (in our case Hutsul), a low-resource and morphologically complex dialect spoken in the Carpathian Highlands. We created a parallel corpus of 9852 dialect-to-standard Ukrainian sentence pairs and a dictionary of 7320 dialectal word mappings. We also addressed data shortage by proposing an advanced Retrieval-Augmented Generation (RAG) pipeline to generate synthetic parallel translation pairs, expanding the corpus with 52142 examples. We have fine-tuned multiple open-source LLMs using LoRA and evaluated them on a standard-to-dialect translation task, also comparing with few-shot GPT-4o translation. In the absence of human annotators, we adopt a multi-metric evaluation strategy combining BLEU, chrF++, TER, and LLM-based judgment (GPT-4o). The results show that even small(7B) finetuned models outperform zero-shot baselines such as GPT-4o across both automatic and LLM-evaluated metrics. All data, models, and code are publicly released at: https://github.com/woters/vuyko-hutsul