 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLib-SibGMU -- A University Library Circulation Dataset for Recommender Systems Developmen
Aug 25, 2022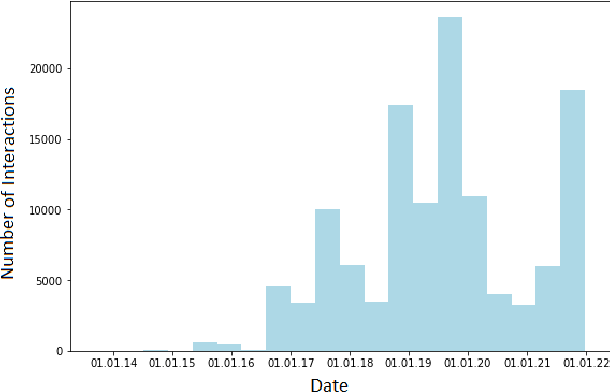
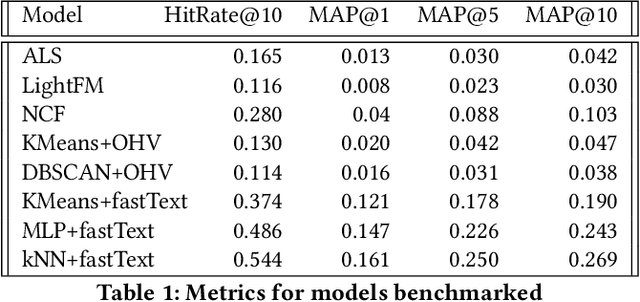
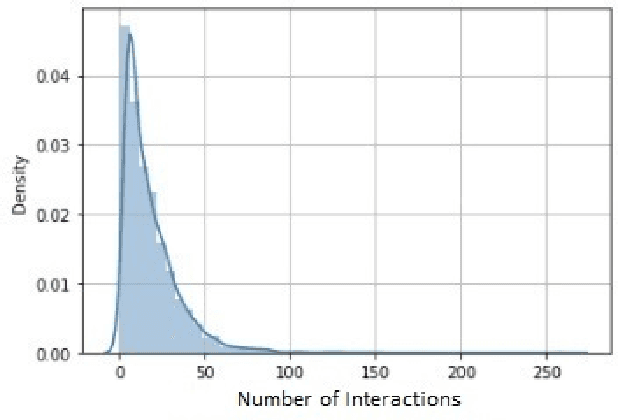
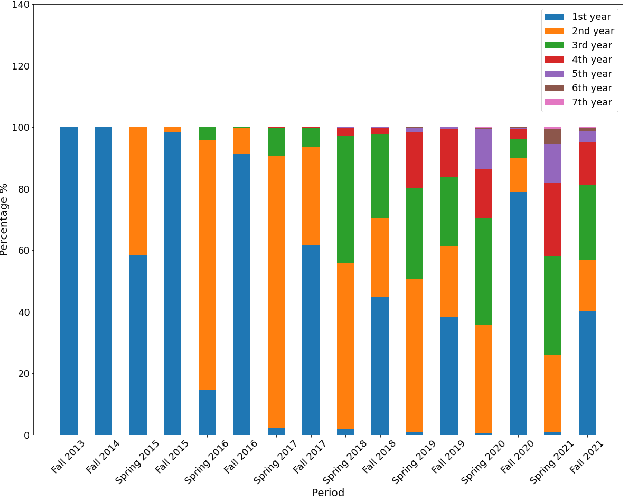
We opensource under CC BY 4.0 license Lib-SibGMU - a university library circulation dataset - for a wide research community, and benchmark major algorithms for recommender systems on this dataset. For a recommender architecture that consists of a vectorizer that turns the history of the books borrowed into a vector, and a neighborhood-based recommender, trained separately, we show that using the fastText model as a vectorizer delivers competitive results.
Using a Language Model in a Kiosk Recommender System at Fast-Food Restaurants
Feb 08, 2022

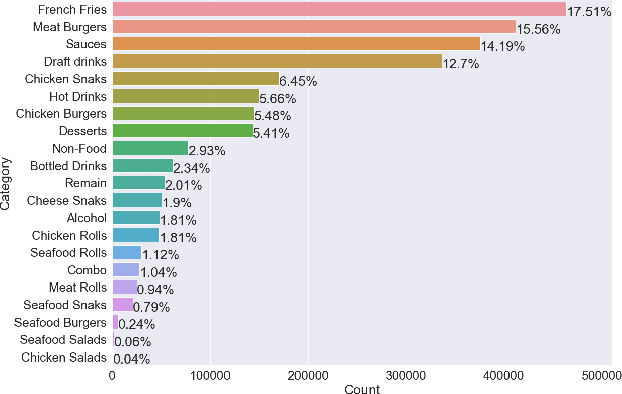
Kiosks are a popular self-service option in many fast-food restaurants, they save time for the visitors and save labor for the fast-food chains. In this paper, we propose an effective design of a kiosk shopping cart recommender system that combines a language model as a vectorizer and a neural network-based classifier. The model performs better than other models in offline tests and exhibits performance comparable to the best models in A/B/C tests.
MediaSpeech: Multilanguage ASR Benchmark and Dataset
Mar 30, 2021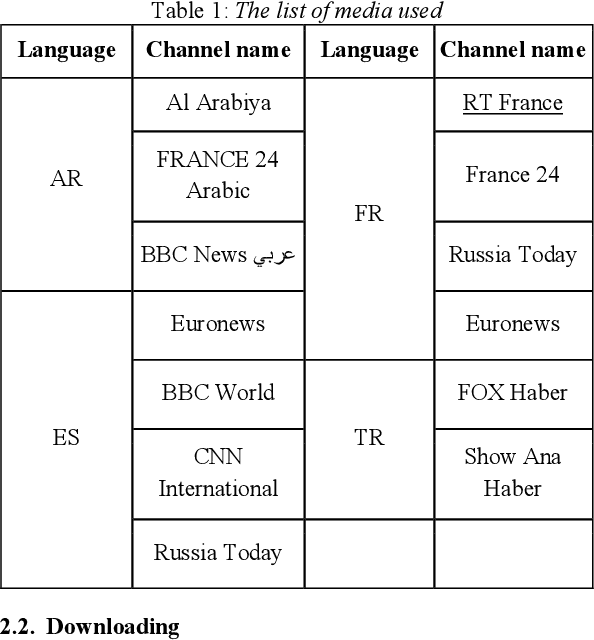
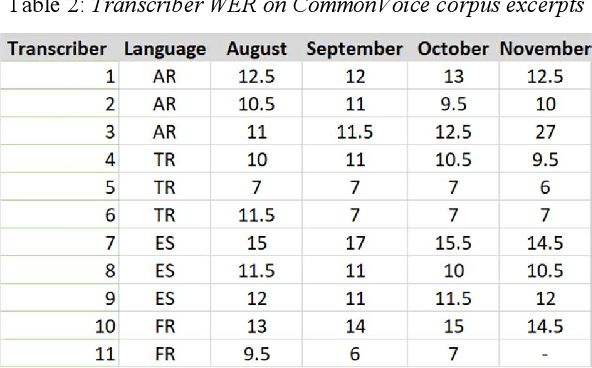
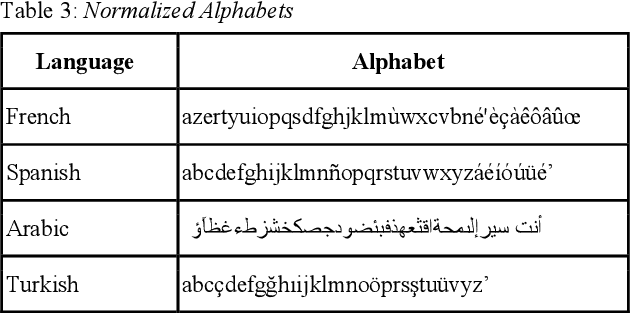
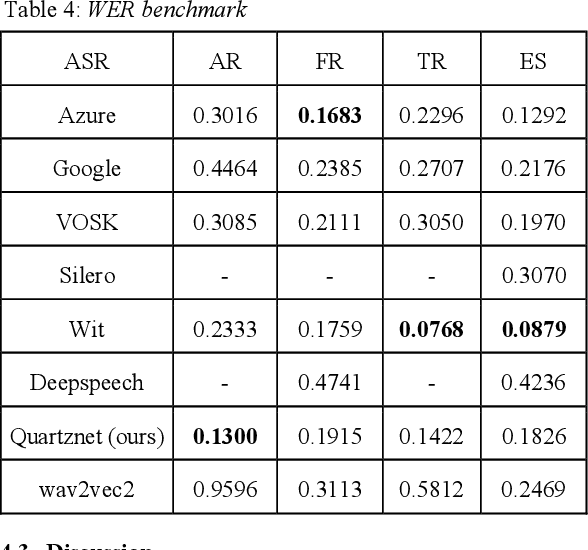
The performance of automated speech recognition (ASR) systems is well known to differ for varied application domains. At the same time, vendors and research groups typically report ASR quality results either for limited use simplistic domains (audiobooks, TED talks), or proprietary datasets. To fill this gap, we provide an open-source 10-hour ASR system evaluation dataset NTR MediaSpeech for 4 languages: Spanish, French, Turkish and Arabic. The dataset was collected from the official youtube channels of media in the respective languages, and manually transcribed. We estimate that the WER of the dataset is under 5%. We have benchmarked many ASR systems available both commercially and freely, and provide the benchmark results. We also open-source baseline QuartzNet models for each language.