 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaterial Fingerprinting: Identifying and Predicting Perceptual Attributes of Material Appearance
Oct 17, 2024



The world is abundant with diverse materials, each possessing unique surface appearances that play a crucial role in our daily perception and understanding of their properties. Despite advancements in technology enabling the capture and realistic reproduction of material appearances for visualization and quality control, the interoperability of material property information across various measurement representations and software platforms remains a complex challenge. A key to overcoming this challenge lies in the automatic identification of materials' perceptual features, enabling intuitive differentiation of properties stored in disparate material data representations. We reasoned that for many practical purposes, a compact representation of the perceptual appearance is more useful than an exhaustive physical description.This paper introduces a novel approach to material identification by encoding perceptual features obtained from dynamic visual stimuli. We conducted a psychophysical experiment to select and validate 16 particularly significant perceptual attributes obtained from videos of 347 materials. We then gathered attribute ratings from over twenty participants for each material, creating a 'material fingerprint' that encodes the unique perceptual properties of each material. Finally, we trained a multi-layer perceptron model to predict the relationship between statistical and deep learning image features and their corresponding perceptual properties. We demonstrate the model's performance in material retrieval and filtering according to individual attributes. This model represents a significant step towards simplifying the sharing and understanding of material properties in diverse digital environments regardless of their digital representation, enhancing both the accuracy and efficiency of material identification.
Self-Supervised Learning of Color Constancy
Apr 11, 2024



Color constancy (CC) describes the ability of the visual system to perceive an object as having a relatively constant color despite changes in lighting conditions. While CC and its limitations have been carefully characterized in humans, it is still unclear how the visual system acquires this ability during development. Here, we present a first study showing that CC develops in a neural network trained in a self-supervised manner through an invariance learning objective. During learning, objects are presented under changing illuminations, while the network aims to map subsequent views of the same object onto close-by latent representations. This gives rise to representations that are largely invariant to the illumination conditions, offering a plausible example of how CC could emerge during human cognitive development via a form of self-supervised learning.
Predicting Perceived Gloss: Do Weak Labels Suffice?
Mar 26, 2024Estimating perceptual attributes of materials directly from images is a challenging task due to their complex, not fully-understood interactions with external factors, such as geometry and lighting. Supervised deep learning models have recently been shown to outperform traditional approaches, but rely on large datasets of human-annotated images for accurate perception predictions. Obtaining reliable annotations is a costly endeavor, aggravated by the limited ability of these models to generalise to different aspects of appearance. In this work, we show how a much smaller set of human annotations ("strong labels") can be effectively augmented with automatically derived "weak labels" in the context of learning a low-dimensional image-computable gloss metric. We evaluate three alternative weak labels for predicting human gloss perception from limited annotated data. Incorporating weak labels enhances our gloss prediction beyond the current state of the art. Moreover, it enables a substantial reduction in human annotation costs without sacrificing accuracy, whether working with rendered images or real photographs.
Deep Neural Models for color discrimination and color constancy
Dec 28, 2020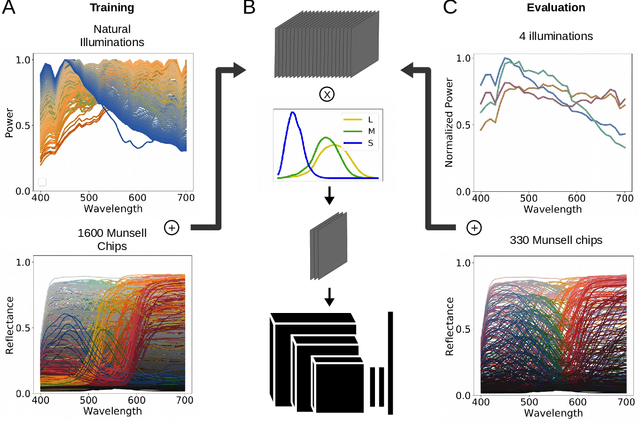
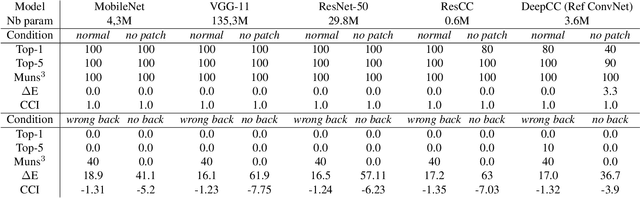
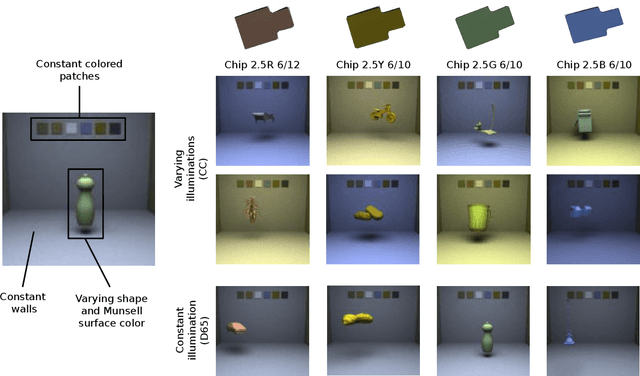
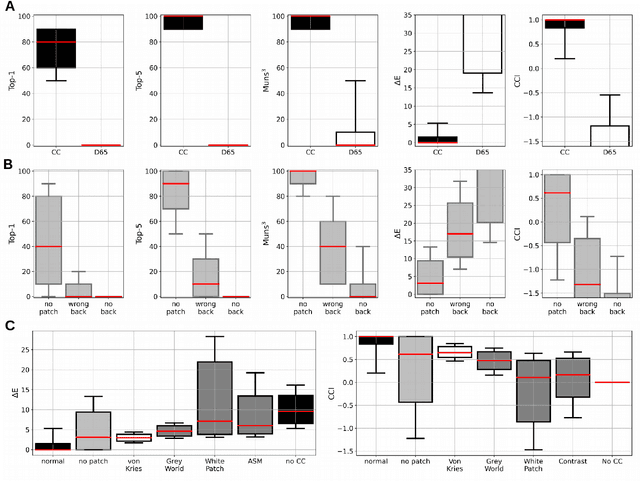
Color constancy is our ability to perceive constant colors across varying illuminations. Here, we trained deep neural networks to be color constant and evaluated their performance with varying cues. Inputs to the networks consisted of the cone excitations in 3D-rendered images of 2115 different 3D-shapes, with spectral reflectances of 1600 different Munsell chips, illuminated under 278 different natural illuminations. The models were trained to classify the reflectance of the objects. One network, Deep65, was trained under a fixed daylight D65 illumination, while DeepCC was trained under varying illuminations. Testing was done with 4 new illuminations with equally spaced CIEL*a*b* chromaticities, 2 along the daylight locus and 2 orthogonal to it. We found a high degree of color constancy for DeepCC, and constancy was higher along the daylight locus. When gradually removing cues from the scene, constancy decreased. High levels of color constancy were achieved with different DNN architectures. Both ResNets and classical ConvNets of varying degrees of complexity performed well. However, DeepCC, a convolutional network, represented colors along the 3 color dimensions of human color vision, while ResNets showed a more complex representation.
Distinguishing mirror from glass: A 'big data' approach to material perception
Mar 05, 2019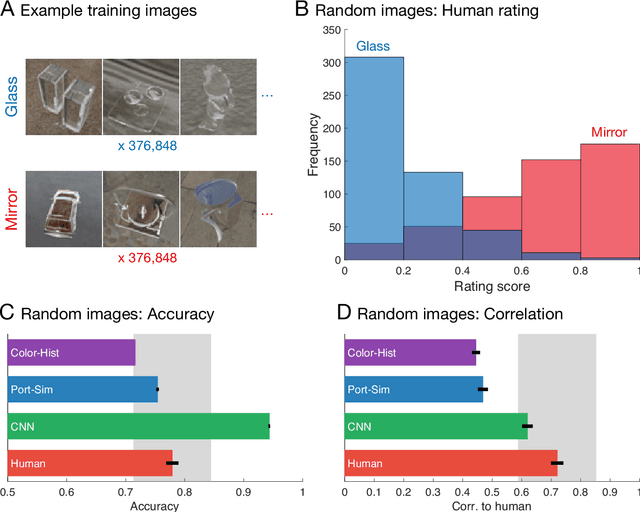
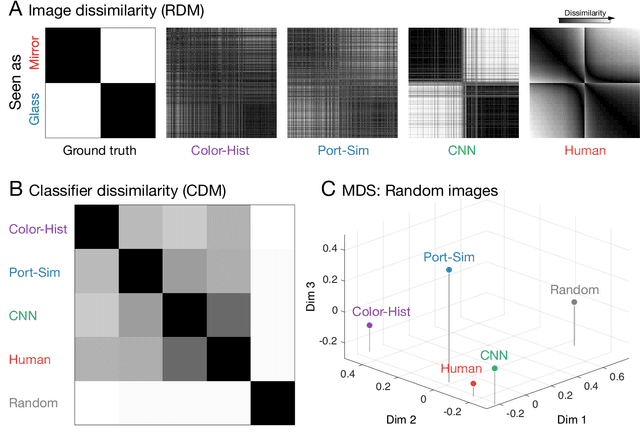
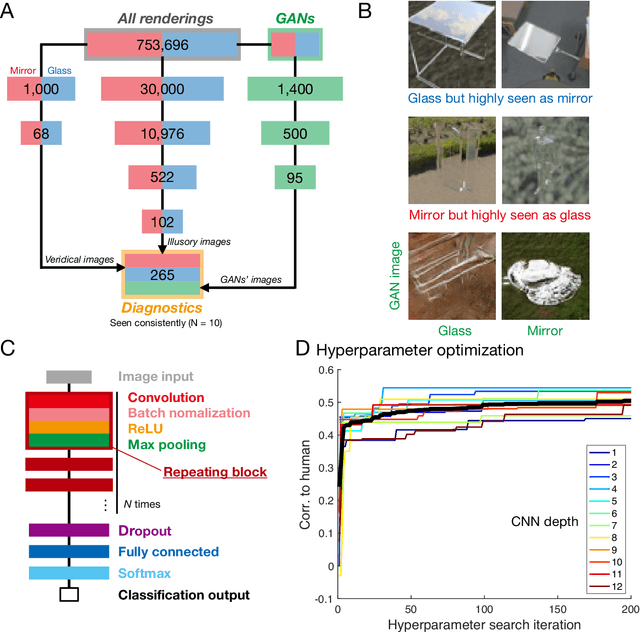
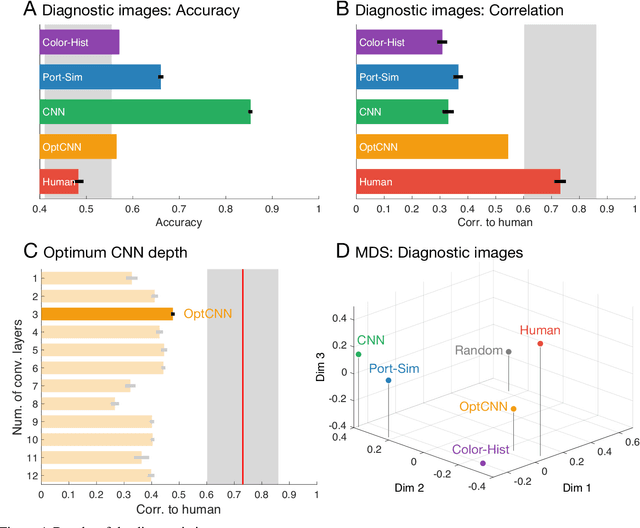
Visually identifying materials is crucial for many tasks, yet material perception remains poorly understood. Distinguishing mirror from glass is particularly challenging as both materials derive their appearance from their surroundings, yet we rarely experience difficulties telling them apart. Here we took a 'big data' approach to uncovering the underlying visual cues and processes, leveraging recent advances in neural network models of vision. We trained thousands of convolutional neural networks on >750,000 simulated mirror and glass objects, and compared their performance with human judgments, as well as alternative classifiers based on 'hand-engineered' image features. For randomly chosen images, all classifiers and humans performed with high accuracy, and therefore correlated highly with one another. To tease the models apart, we then painstakingly assembled a diagnostic image set for which humans make highly systematic errors, allowing us to decouple accuracy from human-like performance. A large-scale, systematic search through feedforward neural architectures revealed that relatively shallow networks predicted human judgments better than any other models. However, surprisingly, no network correlated better than 0.6 with humans (below inter-human correlations). Thus, although the model sets new standards for simulating human vision in a challenging material perception task, the results cast doubt on recent claims that such architectures are generally good models of human vision.