 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Economics in Large Language Models: Exploring Model Behavior and Incentive Design under Resource Constraints
Aug 14, 2025



Large language models (LLMs) are limited by substantial computational cost. We introduce a "computational economics" framework that treats an LLM as an internal economy of resource-constrained agents (attention heads and neuron blocks) that must allocate scarce computation to maximize task utility. First, we show empirically that when computation is scarce, standard LLMs reallocate attention toward high-value tokens while preserving accuracy. Building on this observation, we propose an incentive-driven training paradigm that augments the task loss with a differentiable computation cost term, encouraging sparse and efficient activations. On GLUE (MNLI, STS-B, CoLA) and WikiText-103, the method yields a family of models that trace a Pareto frontier and consistently dominate post-hoc pruning; for a similar accuracy we obtain roughly a forty percent reduction in FLOPS and lower latency, together with more interpretable attention patterns. These results indicate that economic principles offer a principled route to designing efficient, adaptive, and more transparent LLMs under strict resource constraints.
SpiroMask: Measuring Lung Function Using Consumer-Grade Masks
Jan 31, 2022
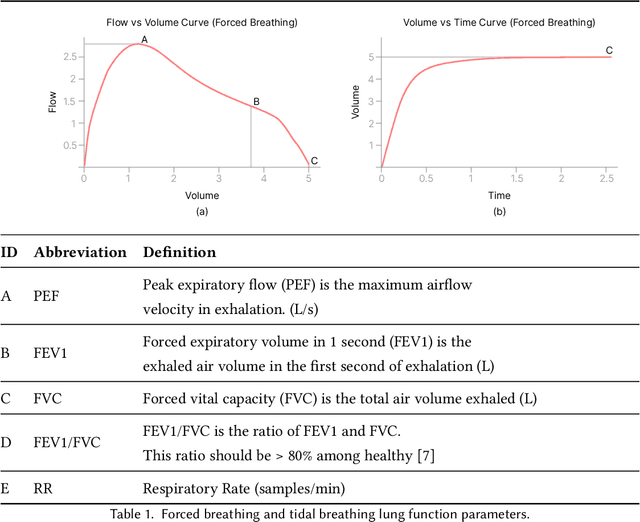
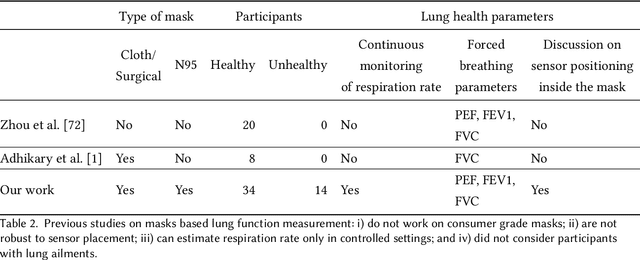
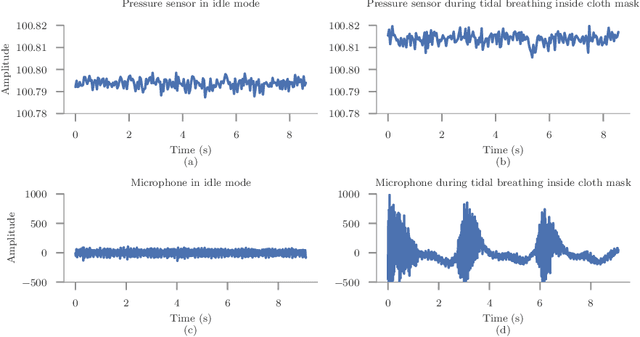
According to the World Health Organisation (WHO), 235 million people suffer from respiratory illnesses and four million people die annually due to air pollution. Regular lung health monitoring can lead to prognoses about deteriorating lung health conditions. This paper presents our system SpiroMask that retrofits a microphone in consumer-grade masks (N95 and cloth masks) for continuous lung health monitoring. We evaluate our approach on 48 participants (including 14 with lung health issues) and find that we can estimate parameters such as lung volume and respiration rate within the approved error range by the American Thoracic Society (ATS). Further, we show that our approach is robust to sensor placement inside the mask.
Blind Motion Deblurring through SinGAN Architecture
Nov 07, 2020
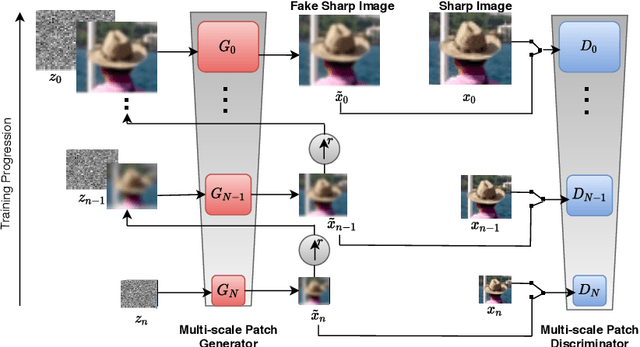
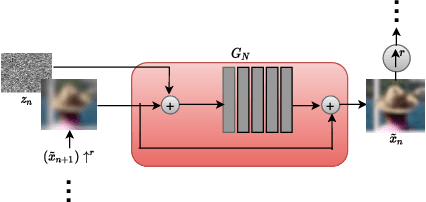

Blind motion deblurring involves reconstructing a sharp image from an observation that is blurry. It is a problem that is ill-posed and lies in the categories of image restoration problems. The training data-based methods for image deblurring mostly involve training models that take a lot of time. These models are data-hungry i.e., they require a lot of training data to generate satisfactory results. Recently, there are various image feature learning methods developed which relieve us of the need for training data and perform image restoration and image synthesis, e.g., DIP, InGAN, and SinGAN. SinGAN is a generative model that is unconditional and could be learned from a single natural image. This model primarily captures the internal distribution of the patches which are present in the image and is capable of generating samples of varied diversity while preserving the visual content of the image. Images generated from the model are very much like real natural images. In this paper, we focus on blind motion deblurring through SinGAN architecture.