 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputational Economics in Large Language Models: Exploring Model Behavior and Incentive Design under Resource Constraints
Aug 14, 2025



Large language models (LLMs) are limited by substantial computational cost. We introduce a "computational economics" framework that treats an LLM as an internal economy of resource-constrained agents (attention heads and neuron blocks) that must allocate scarce computation to maximize task utility. First, we show empirically that when computation is scarce, standard LLMs reallocate attention toward high-value tokens while preserving accuracy. Building on this observation, we propose an incentive-driven training paradigm that augments the task loss with a differentiable computation cost term, encouraging sparse and efficient activations. On GLUE (MNLI, STS-B, CoLA) and WikiText-103, the method yields a family of models that trace a Pareto frontier and consistently dominate post-hoc pruning; for a similar accuracy we obtain roughly a forty percent reduction in FLOPS and lower latency, together with more interpretable attention patterns. These results indicate that economic principles offer a principled route to designing efficient, adaptive, and more transparent LLMs under strict resource constraints.
Localized Flood DetectionWith Minimal Labeled Social Media Data Using Transfer Learning
Feb 10, 2020
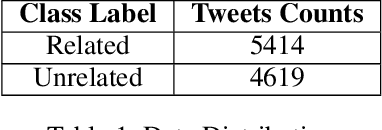
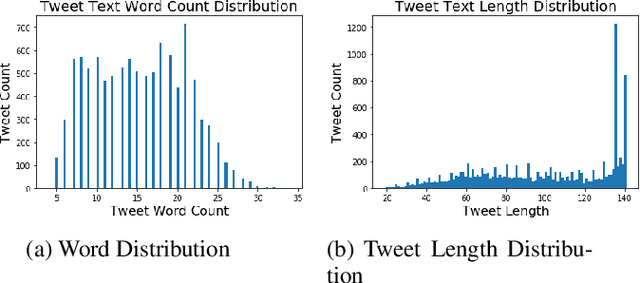
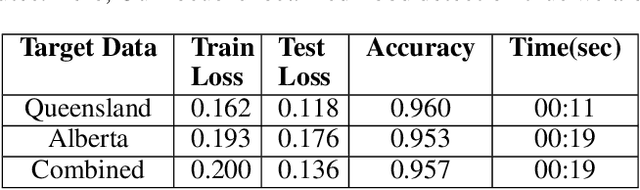
Social media generates an enormous amount of data on a daily basis but it is very challenging to effectively utilize the data without annotating or labeling it according to the target application. We investigate the problem of localized flood detection using the social sensing model (Twitter) in order to provide an efficient, reliable and accurate flood text classification model with minimal labeled data. This study is important since it can immensely help in providing the flood-related updates and notifications to the city officials for emergency decision making, rescue operations, and early warnings, etc. We propose to perform the text classification using the inductive transfer learning method i.e pre-trained language model ULMFiT and fine-tune it in order to effectively classify the flood-related feeds in any new location. Finally, we show that using very little new labeled data in the target domain we can successfully build an efficient and high performing model for flood detection and analysis with human-generated facts and observations from Twitter.